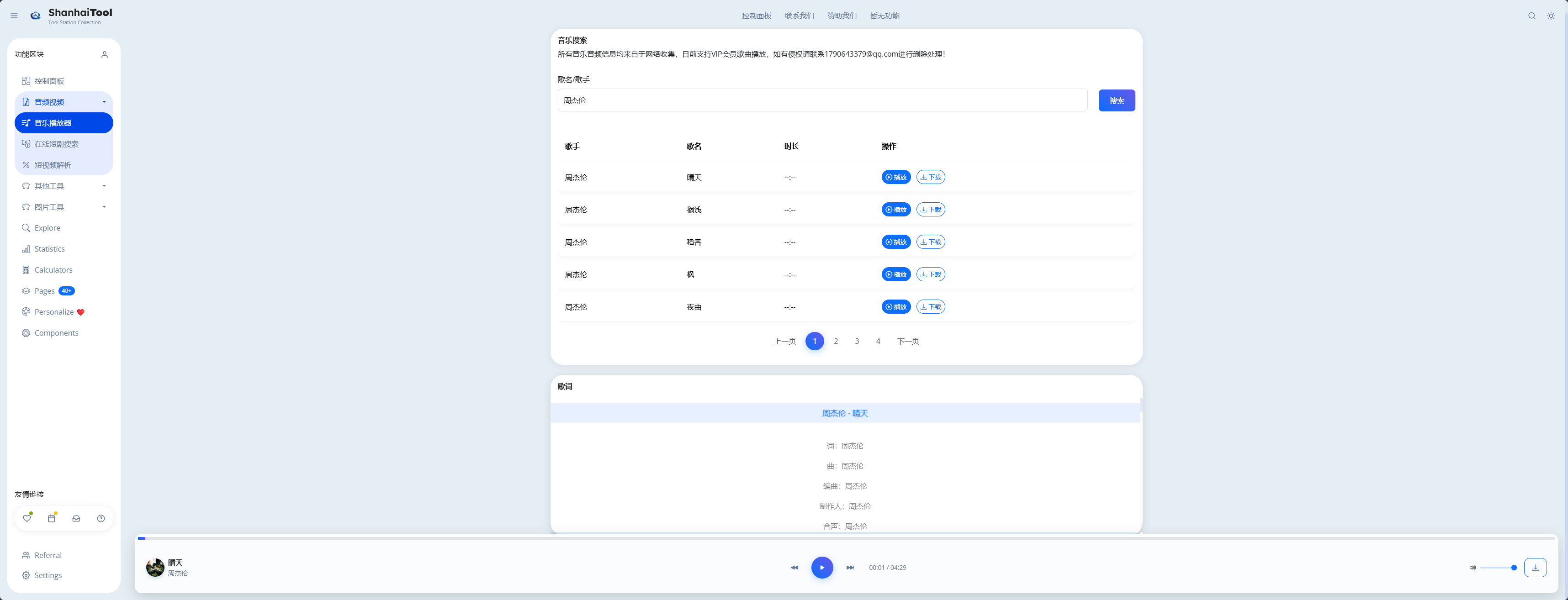
数据类型
字符串
概述:由若干个字符组成字符序列,称之为字符串
特点:字符串一旦被创建就不能被更改
- 定义一个字符串
s1 = "hello"
- 字符串一旦被创建就不能被更改
s1 = "hello"
s1 = "world" # 相当于将新的字符串内存中的地址值赋值给了s1,原本的"hello"的内容没有改变
print(s1)
公共功能
- len() python内置的函数,可以获取字符串的长度【字符个数】
s1 = "shujiakeji"
print(len(s1))
-
字符串具有索引的概念,可以通过索引获取对应的字符
-
从左向右,从0开始编号;从右向左,从-1开始编号
- 使用for循环遍历一个字符串,得到每一个字符
- 字符串通过索引获取字符语句格式:字符串变量名[索引]
s1 = "shujiakeji" # print(len(s1)) for i in range(len(s1)): # 0 - 9print(s1[i],end='') else:print() print("hello world")
-
-
字符串具有切片功能
- 字符串变量名[开始索引 : 结束索引] (注意:左闭右开,右边的范围取不到)
s1 = "同学们,大家好,我们一起来学习python语法!" print(s1[8:11]) # 8,9,10 print(s1)s1 = "同学们,大家好,我们一起来学习python语法!" print(s1[-13 : -10]) # 8,9,10 print(s1)- 字符串变量名[开始索引 : 结束索引 : 步长]
s1 = "同学们,大家好,我们一起来学习python语法!" print(s1[::2]) # 输出为:同们大好我一来习yhn法 print(s1) -
in 用于判断某一个字符串,是否被包含在原有字符串中
-
not in 判断不在
s1 = input("请输入一个包含字母和数字的字符串:")
if 'aas' in s1:print("aas在字符串中")
else:print("aas不在字符串中")
独有功能
- upper() 转大写
s1 = "hello"
print(s1.upper()) # HELLO
- lower() 转小写
s1 = "heLlO wORlD"
print(s1.upper()) # HELLO
print(s1.lower()) # hello world
例:登录模块
while True:name = input("请输入您的姓名:")if name.upper() == 'Q':print("退出系统....")breakpwd = input("请输入您的密码:")if name == 'root' and pwd == '123456':print("登录成功!")breakelse:print("登录失败!请重新输入....")
- isdigit() 判断字符串内容是否是数字
s1 = input("请输入一个字符串:") # '100' 'hello'
if s1.isdigit():print(int(s1)+1)
else:print("您输入的字符串内容不是一个数值")
print("好好学习")
练习:输入一个长字符串,判断其中数字的个数。
s1 = input("请输入一个包含字母和数字的字符串:")
num = 0 # 定义一个变量用于计数数字的个数
for i in s1: # 字符串是可以直接被for循环遍历得到每一个字符的if i.isdigit():num = num + 1
print(f"该字符串中,数字字符有:{num}个")
- startswith 判断字符串是否以某个小字符串开头
s1 = "sh我在study大数据"
b = s1.startswith('sh')
print(b) # True
- endswith 判断字符串是否以某个小字符串结尾
s1 = "sh我在study大数据"
b = s1.endswith('wdy')
print(b) # False
- split 指定分隔符从左向右切进行切分
# 扩展知识:.csv后缀格式的文件,若以记事本打开的话,
# 列和列之间,默认使用的是英文逗号分割的
# 1001,张三,18,男,33期
s1 = "1001,张三,18,男,33期"
l1 = s1.split(',')
print(l1)
默认是所有分隔符都会切分,但是可以设置maxsplit参数值,指定切割的次数
s1 = "1001,张三,18,男,未婚"
l1 = s1.split(',', maxsplit=2)
print(l1) # ['1001', '张三', '18,男,未婚']
- rsplit 指定分隔符从右向左切进行切分
s1 = "1001,张三,18,男,未婚"
l1 = s1.rsplit(',', maxsplit=1)
print(l1)
- join 以调用该方法的字符串进行拼接
s1 = "1001,张三,18,男,未婚"
l1 = s1.split(',')
print(l1)
# 1001|张三|18|男|未婚
print("---------------------")
s2 = '|'.join(l1)
print(s2)
- replace 指定新字符串替换旧字符串
s1 = '今天我学习学习了很多python相关的知识,我的每一天都很充实!'
s2 = s1.replace('学习', 'study')
print(f"s1:{s1}")
print(f"s2:{s2}")
- strip() 去除字符串两边的空白字符, 注意不会去除字符串中间本身的空白字符
s1 = ' hello world '
s2 = s1.strip()
print(f"s1:{s1}") # s1: hello world
print(f"s2:{s2}") # s2:hello world
-
rstrip() 去除字符串右边的空白字符
-
ltrip() 去除字符串左边边的空白字符
- 例子:登录例子
name = input("请输入您的姓名:") pwd = input("请输入您的密码:") if name.strip()=='root' and pwd.strip()=='123':print('登录成功!') else:print('登录失败!')
字符串练习
- 多次替换
每次替换都会得到一个新的结果字符串,下次替换,接着上一次结果继续替换
s1 = "今天我在学习python的相关知识,在学习中的每一天都很充实!"
s2 = s1.replace('我','me')
s3 = s2.replace('学习','study')
s4 = s3.replace('每一天','every day')
print(s4)
只使用一个变量,直接覆盖接收新的结果
s1 = "今天我在学习python的相关知识,在学习中的每一天都很充实!"
s1 = s1.replace('我','me')
s1 = s1.replace('学习','study')
s1 = s1.replace('每一天','every day')
print(s1)
使用链式调用改进
s1 =("今天我在学习python的相关知识,在学习中的每一天都很充实!".replace('我','me').replace('学习','study').replace('每一天','every day'))
print(s1)
- 写代码实现,用户输入自己的国籍,如果是以中国开头,输出中国人,否则输出外国人
方式1:使用startswith实现
s1 = input("请输入自己的国籍:")
if s1.startswith("中国"):print("中国人")
else:print("外国人")
方式2:单独取前两个字符判断
s1 = input("请输入自己的国籍:")
if s1[0:2] == '中国':print("中国人")
else:print("外国人")
- 根据用户输入的文本信息,统计出‘数’这个字的出现次数
# 根据用户输入的文本信息,统计出‘数’这个字的出现次数
s1 = input("输入一个文本: ")
n = 0
for i in s1:if i == '数':n = n + 1
print(f"该文本中'数'出现了{n}次")
- 根据用户输入的文本信息(只包含英语字母和数字),将所有的字母和数字单独提取出来
# 根据用户输入的文本信息(只包含英语字母和数字),将所有的字母和数字单独提取出来
s1 = input("输入一个文本: ")
number_str = ''
zimu_str = ''
for i in s1:if i.isdigit():number_str = number_str + ielse:zimu_str = zimu_str + i
print(f"所有数字字符:{number_str}")
print(f"所有非数字字符:{zimu_str}")
整数 int
所有的整数都是int类型,包括负数
小数 float
所有的小数都是float类型,包括负数
布尔 bool
就两种值,True和False
列表 list
用于存储多种元素的容器,列表中的元素具有有序【存储和取出的顺序一致】且可以发生重复的特点
同样具备索引的概念,同一个列表中的元素类型可以是不一样的
举例:[10, 12.23, '我真棒', True, [11,22,33,44], 'liebiao']
公共功能
- 长度功能
# 如何创建一个空列表?
# 方式1:直接使用[]
list1 = []
# 方式2:使用内置函数list()
list1 = list()
# 使用len()函数获取元素的个数
list1 = [10, 12.23, '学习', True, [11,22,33,44], 'xuexi']
print(f"list1列表中的元素个数为:{len(list1)}") # 6
# 列表本身就是一个可以迭代的序列,所以直接使用for循环获取元素
list1 = [10, 12.23, '学习', True, [11,22,33,44], 'xuexi']
for i in list1:print(i)
- 索引功能
# 0 1 2 3 4 5
list1 = [11, 22, 33, 44, 55, 66]
# -6 -5 -4 -3 -2 -1
# 获取44这个元素
print(list1[3])
- 切片功能
# 0 1 2 3 4 5
list1 = [11, 22, 33, 44, 55, 66]
# -6 -5 -4 -3 -2 -1
print(list1[2:5])
print(list1, type(list1))
# 使用负数索引获取33,44,55
print(list1[-4:-1]) # [33, 44, 55]
# 按顺序取55,44,33
print(list1[-2:-5:-1]) # [55, 44, 33]
- in 判断某一个元素是否在列表中出现
list1 = [11,22,33,44,55,66,22,11,55,77,22,11,22]
if 77 in list1:print("77出现在列表中")
else:print("未出现")
独有功能
-
增加元素
- 追加append
# 创建一个空列表 list1 = [] # list1 =list() list1.append(100) list1.append('hello') list1.append('world') list1.append(True) list1.append('hello') list1.append('flink') print(f"list1:{list1}") # list1:[100, 'hello', 'world', True, 'hello','flink']例子
name_list = [] while True:name = input("请输入登录用户的名字:")if name.upper() == 'Q':breakname_list.append(name) print(name_list)- 插入 insert
# list1:[100, 'hello', 'world', True, 'hello', 'flink'] print(f"list1:{list1}") print("--------------------") list1.insert( 2,'上海') print(f"list1:{list1}")#[100,'上海' 'hello', 'world', True, 'hello', 'flink'] -
删除元素
- 方式1:调用remove()函数 在已知要删除元素的值(只能删除已存在的元素)
list1 = [11, 22, 33, 44, 55, 66] list1.remove(44) print(f"list1: {list1}") print('hello world')使用remove需要确保要删除的元素存在于列表中,否则报错,程序停止运行。
- 方式2:调用pop()函数 根据索引删除元素,返回被删除元素的值
list1 = [11, 22, 33, 44, 55, 66] s = list1.pop(3) print(f"list1: {list1}") print(s) print('hello world')- 方式3:使用python内置关键字 del
list1 = [11, 22, 33, 44, 55, 66] del list1[3] print(f"list1: {list1}") -
修改元素 直接通过索引覆盖原有的值,起到修改的效果
list1 = [11, 22, 33, 44, 55, 66]
list1[3] = 100
print(f"list1: {list1}")
- 反转功能
list1 = [11, 22, 33, 44, 55, 66]
print(f"反转前:{list1}")
list1.reverse()
print(f"反转后:{list1}")
练习:判断某一个字符串是否是对称字符串
# aba helloolleh hello owo str1 = input("请输入一个字符串:") list2 = list(str1) # 字符串转列表,每个字符作为列表中的元素 list2.reverse() # 将列表中的元素进行反转 str2 = ''.join(list2) # 将元素以指定分隔符拼接得到字符串 if str2==str1:print("该字符串是一个对称字符串!") else:print("不是对称字符串!")
-
拷贝功能
-
python列表中的copy()属于浅拷贝
-
拷贝单个元素列表的形式
list1 = [11, 22, 33, 44, 55, 66] list2 = list1.copy() print(f"list1:{list1}") print(f"list2:{list2}") print("-----------------------------") list1[3] = 100 print(f"list1:{list1}") print(f"list2:{list2}")- 拷贝复杂元素列表的形式
list1 = [11, 22, 33, [100, 200, 300], 55, 66] list2 = list1.copy() print(f"list1:{list1}") print(f"list2:{list2}") print("-----------------------------") list1[3][1] = 'hello' print(f"list1:{list1}") print(f"list2:{list2}")
-
-
-
count() 统计列表中某个元素的个数
list1 = [11,22,33,44,55,66,22,11,55,77,22,11,22]
res1 = list1.count(11)
print(res1)
元组tuple
元素是有序的,元素也可以发生重复,但是元组中的元素一旦确定了,就不能更改【无法完成增删改】
-
如何创建一个元组?
- 创建一个空元组
# 创建一个空元组 t1 = () 或者 t1 = tuple()-
创建一个非空元组
- 创建一个只有1个元素的元组 , 元素的后面要有一个逗号,若不加,则等同于一个元素直接赋值
t1 = (11,)- 创建一个元素个数大于等于2的元组 最后一个元素后面加逗号或者不加都行
t2 = (11,22,33,) 或 t2 = (11,22,33)
公共功能
- 长度功能 获取的是元素的个数
t2 = (11,22,33,)
print(len(t2))
- 索引功能
t2 = (11,22,33,)
print(t2[1])
- 切片功能
t1 = (11,22,33,44,55,66)
print(t1[2:5]) # (33, 44, 55)
- in 包含
t1 = (11,22,33,44,55,66)
if 44 in t1:print("yes")
else:print("no")
独有功能
- count()
- index()
通常情况下,开发中我们将元组中存储固定的链接值,比如与数据库的连接信息,重要的路径信
息。
字典dict
特点:
- 元素是由键值对构成,一个键值对看作一个元素
- 键是唯一的,不允许重复出现
- 值可以发生重复的
- 元素键和值的类型可以是不一样的
- 一个字典中的元素之间是有序的(python3.6版本之后有序,python3.6之前是无序的)
- 如何创建一个字典?
# 创建一个空字典
d1 = dict()
或者
d2 = {}
公共功能
- 长度功能 获取的是键值对的个数
d1 = {'name':'张三', 'age':18, 'likes':['打游戏','看电影','跑步'], 'dog':{'name':'哮
天犬','age':3}}
print(len(d1)) #结果为4
- 索引功能
在字典类型里,索引指的是键,键是唯一,可以通过键获取对应的值
d1 = {'name':'张三', 'age':18, 'likes':['打游戏','看电影','跑步'], 'dog':{'name':'哮
天犬','age':3}}
print(d1['age']) # 18
print(d1['likes'][1]) # 看电影
- 切片功能 字典没有切片
- in 包含功能 判断的是键是否存在字典中
if 'name' in d1:print('存在这个键') # 存在!!
else:print("不存在")
# -----------------------------------------
if 18 in d1:print('存在这个键')
else:print("不存在") # 不存在!!
-
遍历
- 先获取所有的键,遍历得到每一个键,根据键获取每一个值
d1 = {'name': '张三', 'age': 18, 'gender': '男', 'clazz': '33期'} # 获取所有的键 keys = list(d1.keys()) for key in keys:# 根据键获取对应的值value = d1.get(key)print(f"{key}-{value}")- 直接获取所有的键值对,遍历得到每一个键值对,得到每一个键和每一个值
key_values = list(d1.items()) # print(key_values, type(key_values)) for key_value in key_values:key = key_value[0]value = key_value[1]print(f"{key}={value}")
独有功能
- keys() 获取字典中所有的键
- get(键) 根据键获取值
- items() 获取所有的键值对
- clear() 清空字典中所有的元素
- pop 根据键从字典中移除一个键值对,返回一个值
集合 set
元素唯一且无序
set集合创建的方式:
- 创建空set集合
s1 = set()
- 创建有元素的集合
s2 = {11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11}
公共功能
- 没有索引的概念
- 没有切片的功能
- 长度功能
s2 = {11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11}
# print(s2, type(s2))
print(s2)
print(len(s2))
- in 包含
s2 = {11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11}
if 22 in s2:print("yes")
else:print("no")
-
练习:去重列表中的重复元素
- 方法1:借助一个空列表
list1= [11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11] list2 = [] for i in list1:if i not in list2:list2.append(i) print(f"list2:{list2}")- 方式2:借助转set集合进行去重
list1= [11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11] list1 = list(set(list1)) print(list1)
独有功能
- 求差集
s1 = {11,22,33,44}
s2 = {22,33,55,66}
# res1 = s1 - s2 # 求差集
res1 = s1.difference(s2)
print(res1)
- 求并集
s1 = {11,22,33,44}
s2 = {22,33,55,66}
res1 = s1.union(s2)
print(res1)
- 求交集
s1 = {11,22,33,44}
s2 = {22,33,55,66}
res1 = s1.intersection(s2)
print(res1)
- 添加元素 add
s1 = {11,22,33,44}
s1.add('hello')
s1.add('world')
s1.add(14)
print(s1)
- 删除一个元素
res1 = s1.pop()
print(s1)
print(res1)
- 指定元素删除 remove()
需要元素存在集合中,否则报错
res1 = s1.remove(11)
print(s1)
print(res1)
- 指定元素删除 discard()
元素不存在于集合中也不会报错
s1 = {11,22,33,44}
s1.discard(33)
print(s1)
列表推导式【列表生成式】
# 例子:将1-10之间所有数*2 放入到一个列表中
list1 = [i * 2 for i in range(1,11)]
print(list1)
# 例子:将1-10之间所有的偶数*2 放入到一个列表中
list1 = [i * 2 for i in range(1,11) if i%2==0]
print(list1)
生成式结构:
[部分1 部分2 [部分3]] (第三部分不是必须)
部分1:对元素要进行的操作 i * 2
部分2:循环取元素 for i in range(1,11)
部分3:可以对循环取的元素进行过滤 if i%2==0
练习
在控制台中输出99乘法表 (做出之后,想一想能不能使用一行代码生成)
for i in range(1, 10):for j in range(1, i + 1):print(f"{j}*{i}={i * j}", end='\t')print()
# 一行生成99乘法表
list1 = [f"{j}*{i}={i * j}" for i in range(1, 10) for j in range(1, i + 1)]
print(list1)
现在有一个元组(1,3,2,4,5,1,2,3,4),请进行去重,最终得到的也是一个元组
# 方式1:利用set里元素唯一进行去重
tuple1 = (1,3,2,4,5,1,2,3,4)
tuple1 = tuple(set(tuple1))
print(tuple1)# 方式2:利用一个空列表进行去重
tuple1 = (1,3,2,4,5,1,2,3,4)
list1 = []
for i in tuple1:if i not in list1:list1.append(i)
tuple1 = tuple(list1)
print(tuple1)
将列表元素以指定格式输出:list1 = ['华为mate60','iphone15 pro','小米14 pro']
输出格式为:1.华为mate60
2.iphone15 pro
3.小米14 pro
#方式一:
list1 = ['华为mate60', 'iphone15 pro', '小米14 pro']
n = 1
for i in list1:print(f"{n}.{i}")n = n + 1#方式2:使用内置函数
list1 = ['华为mate60', 'iphone15 pro', '小米14 pro']
for index, e in enumerate(list1):print(f"{index + 1}.{e}")
杨辉三角
list1 = [1]
for i in range(10):print(list1)list1.append(0)list1 = [list1[j] + list1[j - 1] for j in range(i + 2)]