1. 视图
1.1 理论
[1] 什么是视图
视图是通过查询得到一张虚拟表,并保存下来,后续可以直接使用。
视图也是一张表。
在计算机科学中,视图(View)是一种虚拟表,其内容是一个或多个基本表的查询结果。
与基本表不同,视图不存储实际的数据,而是根据创建视图时的查询语句在使用时进行实时计算。
[2]视图的作用
如果需要频繁操作一张虚拟表(表并不存在,只是结构与表类似),就可以制作成视图,降低操作复杂度。
[3]注意事项
视图只有表结构没有实际数据,所展示的数据来自于原本表。
视图可以对原本表中的数据进行增删改查。
但是建议视图只用来查询,不要对原本表中的数据进行增加、删除、修改。
[4]语法
create view 视图名(即表名) as SQL查询语句;
1.2 代码示例
原本表数据

在原本表的基础上创建视图
create view virtual_emp as select * from emp where id>3;
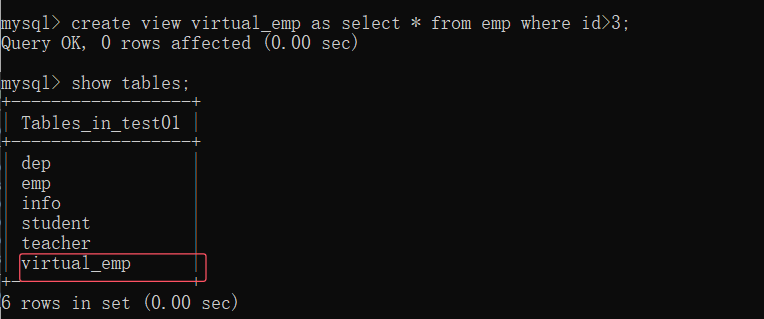
查看视图数据
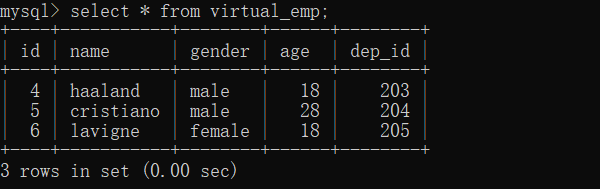
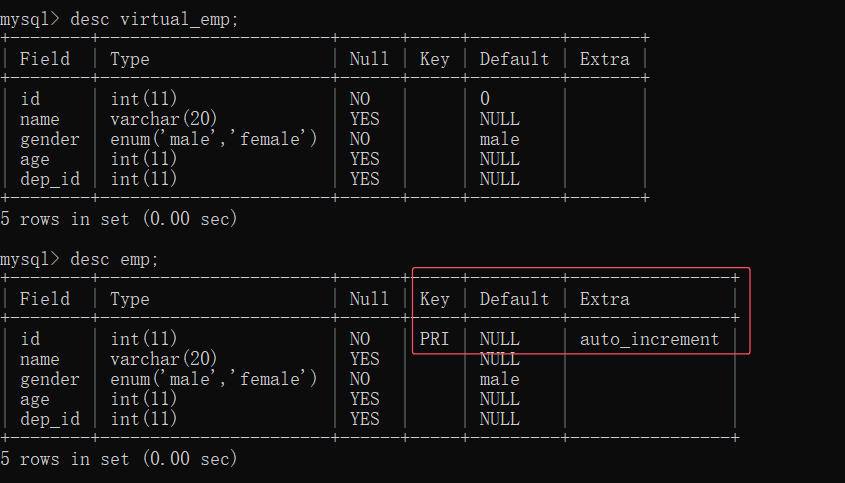
查看视图结构
删除视图 drop view 视图名;

2. 触发器
2.1 理论
(1)概念
在对表数据进行增、删、改的操作下,自动触发的功能
(2)触发器使用场景
表数据增加之前、增加之后
表数据修改之前、修改之后
表数据删除之前、删除之后
(3)创建触发器语法
create trigger 触发器名称 before/after insert/update/delete on 表名 for each row begin SQL语句 end 结束符
因为SQL语句也包含分号; 因此创建触发器之前要将结束符由 ; 修改为$$,创建完成之后再改回 ;
2.2 代码示例
(1)创建命令信息表
记录哪个用户、在哪个时间、运行了哪条命令、是成功还是失败
create table command(id int primary key auto_increment comment "主键",username varchar(32) comment "用户",cmd varchar(32) comment "命令",sub_time datetime comment "运行时间",status enum("success","failure") comment "运行状态"
);
(2)创建日志记录表
记录运行错误的命令、运行错误命令的时间
create table error_log(id int primary key auto_increment comment "主键",error_cmd varchar(64) comment "运行错误的命令",error_time datetime comment "日志时间"
);
(3)创建触发器
delimiter $$ --将默认的结束符由;改为$$
create trigger tri_after_insert_command after insert on command for each row #在command表插入数据之后触发
begin
if NEW.status='failure' #新记录都会被MySQL封装成NEW对象
then insert into error_log(error_cmd,error_time) values(NEW.cmd,NEW.sub_time);
end if; #if语句结尾固定搭配
end $$
delimiter ; --完成将结束符改回分号
以上 #注释的内容是在一条完整的创建触发器的语句里面,实际运行时不去掉这些注释会报错
查看触发器:
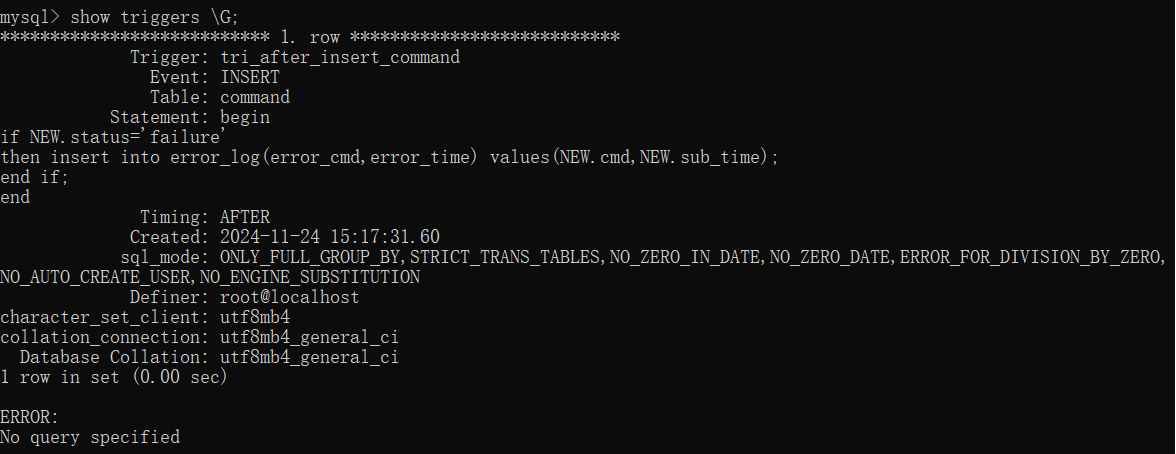
(4)向command表中插入数据,满足指定条件时,触发器运行
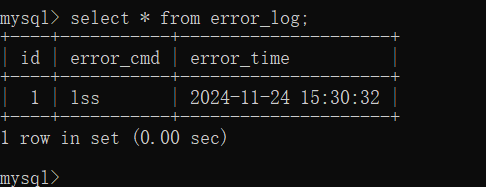
insert into command(usename, cmd, sub_time, status) values('avril', 'ls', NOW(), "success"),('lavigne', 'lss', NOW(), "failure");
"failure"的相关数据被记录到表error_log中
(5)删除触发器
drop trigger 触发器名称;

3. 事务
3.1 理论
(1) 概念
事务是指一系列相关操作的集合,这些操作被视为一个不可分割的工作单元。
一个事务可以包含多条SQL语句,这些语句要么同时执行成功,要么同时执行失败。
(2)事务的四大特性
ACID
A(Atomicity):原子性
事务被视为一个原子操作,不可再分割
要么所有的操作都成功执行,要么所有的操作都会被回滚到事务开始前的状态,确保数据的一致性。
C(Consistency):一致性
事务执行前后,数据库应保持一致的状态。
在事务开始之前和结束之后,数据库必须满足所有的完整性约束,如数据类型、关系等。
I(Isolation):隔离性
事务的执行结果对其他并发执行的事务是隔离的。
即一个事务的执行不应受到其他事务的干扰,各个事务之间应该相互独立工作,从而避免数据的不一致性。
D(Durability):持久性
指一旦事务提交(commit)成功,它对数据库的改变就是永久性的,即使系统随后发生故障,这些改变也不会丢失。
持久性确保了在事务成功提交后,即使系统崩溃或电源故障,数据仍然会被保留在数据库中。
3.2 代码示例
(1)创建表,准备数据
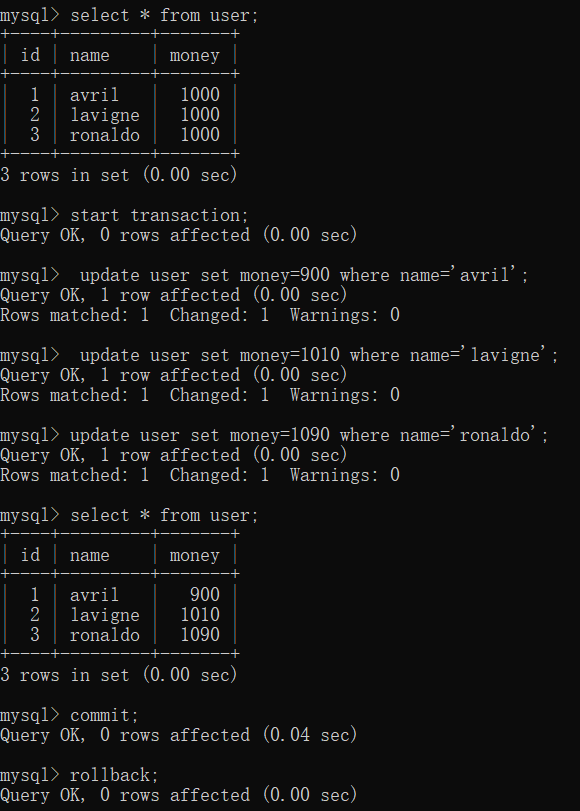
create table user(id int primary key auto_increment,name varchar(32),money int
)insert into user(name, money) values('avril', 1000),('lavigne', 1000),('ronaldo', 1000);
(2)事务操作
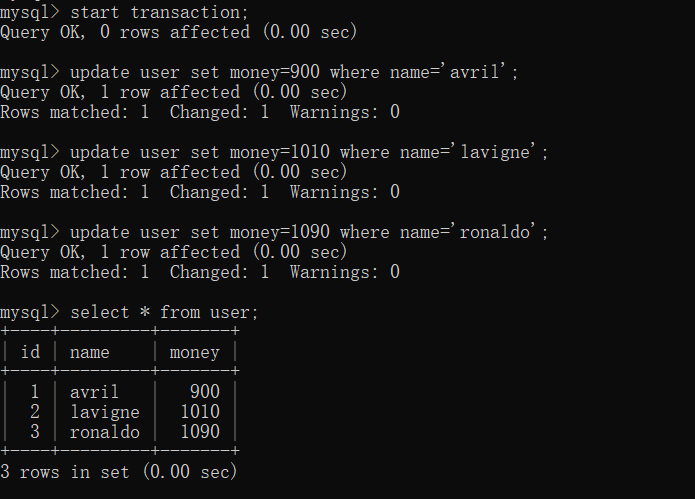
[1]开启一个事务
start transaction;
[2]在事务里面编写SQL语句
update user set money=900 where name='avril';
update user set money=1010 where name='lavigne';
update user set money=1090 where name='ronaldo';
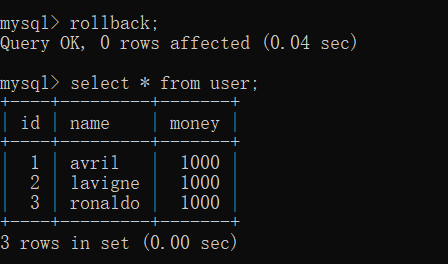
[3]事务回滚:返回执行事务操作之前的数据库状态
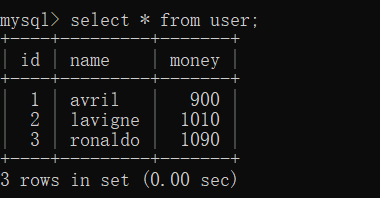
rollback;
[4]提交事务:类比于将数据从内存保存到硬盘中,事务提交之后无法回滚
commit;
4. 存储过程
4.1 理论
(1)概念
存储过程类比于python中的自定义函数
存储过程的内部包含了一系列可以执行的SQL语句,位于MySQL的服务端中;可以通过调用存储过程触发内部的SQL语句
存储过程是关系型数据库中存储的一组预定义的SQL语句集合,可以接收参数并返回结果
(2)语法
delimiter $$
create procedure 存储过程名称(形参1,形参2...)
beginsql语句;
end$$
delimiter ;
4.2 代码示例
(1)创建存储过程
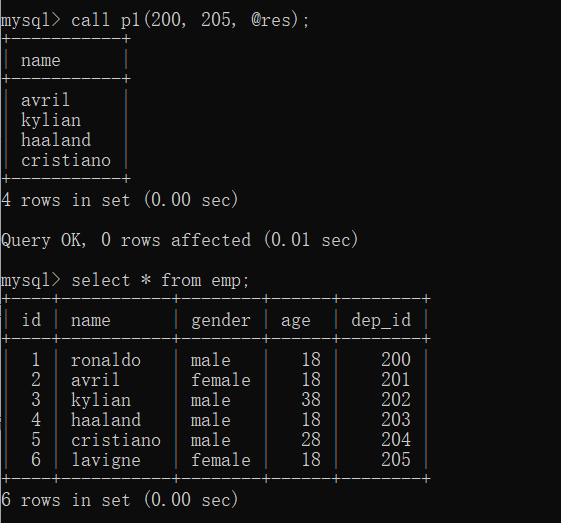
delimiter $$create procedure p1(in m int, # in表示这个参数必须只能是传入不能被返回出去in n int,out res int # out表示这个参数可以被返回出去,inout表示即可以传入也可以被返回
)
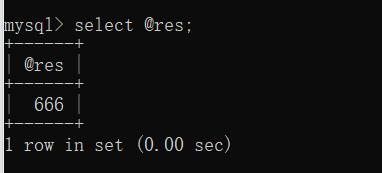
beginselect name from emp where dep_id > m and dep_id <n;set res = 666; # 设置res变量的值,用来标识当前的存储过程代码确实执行了
end $$delimiter ;
(2)调用存储过程
调用存储过程时,传入必要的参数,获取结果
查看存储过程具体信息
show create procedure p1;
查看所有存储过程
show procedure status;
删除存储过程
drop procedure p1;
5. 内置函数
MySQL的内置函数只能在SQL语句中使用
CONCAT(str1, str2, ...): 将多个字符串拼接成一个字符串
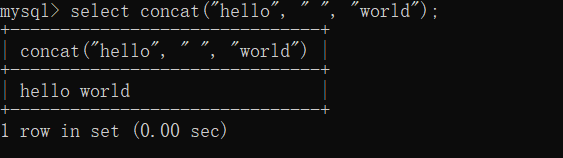
SUBSTRING(str, start, length): 切片
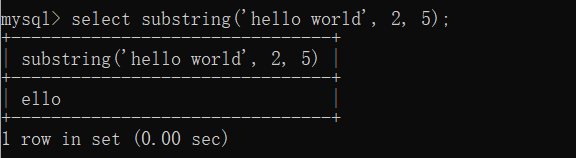
UPPER(str): 将字符串转换为大写
LOWER(str): 将字符串转换为小写
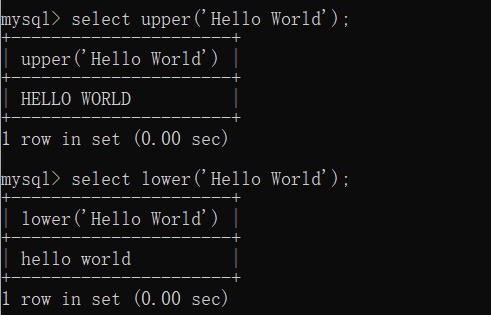
LENGTH(str): 返回字符串的长度
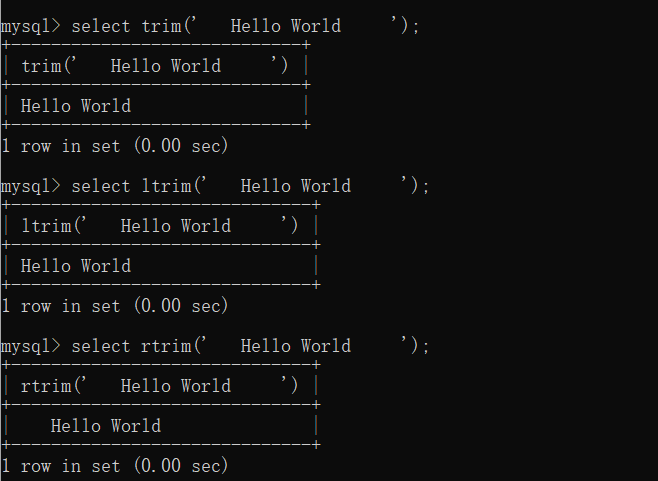
Trim、LTrim、RTrim: 移除指定字符
TRIM()函数可以删除字符串开头和结尾处的所有指定字符。
LTRIM()和RTRIM()分别只删除开头和结尾的指定字符。
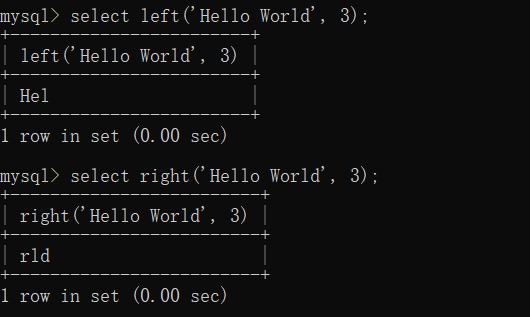
Left、Right: 获取左右起始指定个数字符
日期和时间函数:
NOW(): 返回当前日期和时间。
CURDATE(): 返回当前日期。
CURTIME(): 返回当前时间。
DATE_FORMAT(date, format): 格式化日期。
数值函数:
ROUND(num, decimals): 对数值进行四舍五入。
FLOOR(num): 返回不大于给定数值的最大整数。
CEILING(num): 返回不小于给定数值的最小整数。
ABS(num): 返回给定数值的绝对值。
6. 流程控制
# MySQL if判断
if 条件 then
子代码
elseif 条件 then
子代码
else
子代码
end if;# MySQL while循环
DECLARE num INT ;
SET num = 0 ;
WHILE num < 10 DO
SELECT num ;
SET num = num + 1 ;
END WHILE ;
7. 索引
7.1 索引的概念
索引(在MySQL中也叫做“键(key)”)是存储引擎用于快速找到记录的一种数据结构,这也是索引最基本的功能。
索引对于良好的性能非常关键。
数据量越大时,索引对性能的影响也越重要,好的索引可以将查询性能提高几个数量级。
在数据量较小且负载较低时,不恰当的索引对性能的影响可能还不明显,但是在数据量逐渐增大时,糟糕的索引会使MySQL的性能急剧的下降。
索引优化是查询性能优化最有效的手段。
如果想要在一本书中找到某个特定主题,一般会先看书的目录,找到对应的页码,然后直接翻到对应的页码即可查看。
在MySQL中,存储引擎用类似的方法使用索引
首先在索引中找到对应的值
然后根据匹配的索引记录找到对应的数据行。
简单的说,数据库索引类似于书前面的目录,能加快数据库的查询速度。
7.2 MySQL中索引的类型
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建 对应列的索引。
索引在MySQL中也叫键,是存储引擎用于快速查找记录的一种数据结构
主键约束(PRIMARY KEY)
唯一约束(UNIQUE)
index key
外键约束(FOREIGN KEY)
foreign key
不是用来加速查询的
primary key/unique key
不仅可以加速查询速度,还具有对应的约束条件
index key
只有加速查询速度的功能
7.3 索引的本质
通过不蹲的缩小想要的数据范围筛选出最终的结果
同时将随机事件(一页一页的翻)变成顺序时间(先找目录再找数据)
也就是说我们有了索引机制,我们可以总是用一种固定的方式查询数据
7.4 索引的缺点
当表中有大量数据存在的前提下,创建索引的速度回非常慢
在索引创建完毕后,对表的查询性能会大幅度的上升,但是写的性能也会大幅度下降
不要随意地创建索引
7.5 索引的使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
数据量较大,且经常对这些列进行条件查询。
该数据库表的插入操作,及对这些列的修改操作频率较低。
索引会占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。


![[Vue] Watch and WatchEffect](https://img2024.cnblogs.com/blog/364241/202411/364241-20241128214729992-1238412898.png)


![[游记]CSP2024 游记](https://cdn.luogu.com.cn/upload/image_hosting/nm2e9kcb.png)
![[笔记]动态规划优化(斜率优化,决策单调性优化)](https://cdn.luogu.com.cn/upload/image_hosting/rd4wpk3v.png)