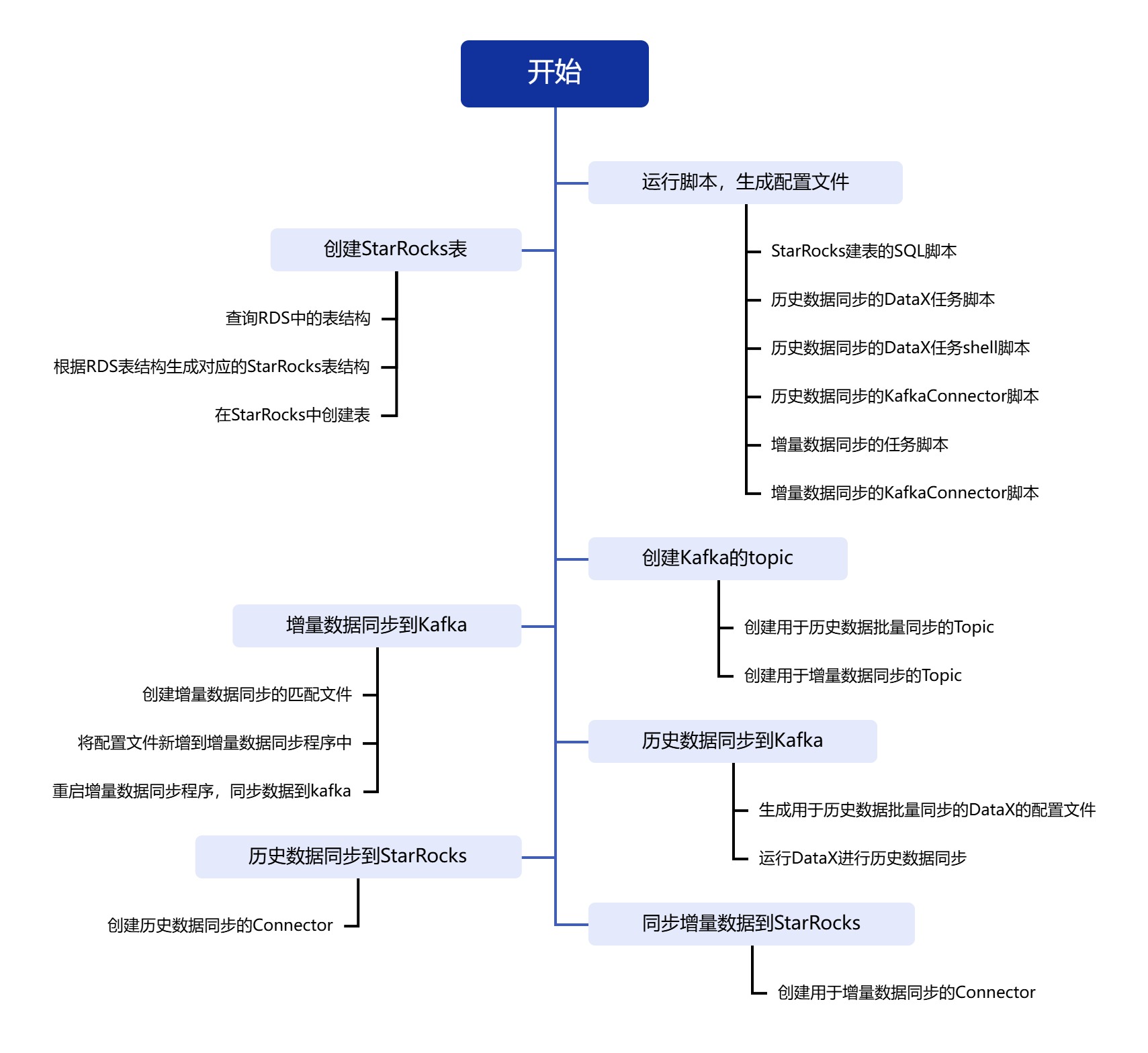
步骤
1.拿到页面源代码,然后提取子页面的链接地址,href
2.通过href拿到子页面内容,从子页面找到图片的下载地址 img->src
3.下载图片
import requests
from bs4 import BeautifulSoup
import re
import time
url="https://moetu.club/category/illustration"
header={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 QuarkPC/1.9.5.160"
}resp=requests.get(url,headers=header)
resp.encoding='utf-8'#把源代码交给bs
main_page=BeautifulSoup(resp.text,"html.parser")
archive_row=main_page.find("div",attrs={"class":"archive-row"})
obj=re.compile(f"<div class=\"post-info\">.*?<h2><a.*?href=\"(?P<address>.*?)\">(?P<title>.*?)</a></h2>",re.S)
ret=obj.finditer(str(archive_row))
for i in ret:#print(i.group("address")+i.group("title"))#拿到子页面的源代码child_page_resp=requests.get(i.group("address"),headers=header)child_page_text=child_page_resp.text#print(child_page_text)#从子页面拿到图片的下载路径child_page=BeautifulSoup(child_page_resp.text,"html.parser")p=child_page_content=child_page.find("div",attrs={"class":"entry-content"})#print(child_page_content)# obj2=re.compile(f"<img alt=.*?class=.*?data-src=\"(?P<address2>.*?)\" decoding=\"async\" src=.*?><",re.S)# ret2=obj2.finditer(str(p))# for j in ret2:# print(j.group("address2"))img=p.find("img")data=img.get("data-src")
# #下载图片img_resp=requests.get(data)
# #img_resp.content #这里拿到的是字节img_name=data.split("/")[-1]#拿到url中的最后一个/以后的内容with open("img_/"+img_name,mode="wb") as f:f.write(img_resp.content) #图片内容写入文件print("over!"+img_name)time.sleep(0.25)
print("all over!")