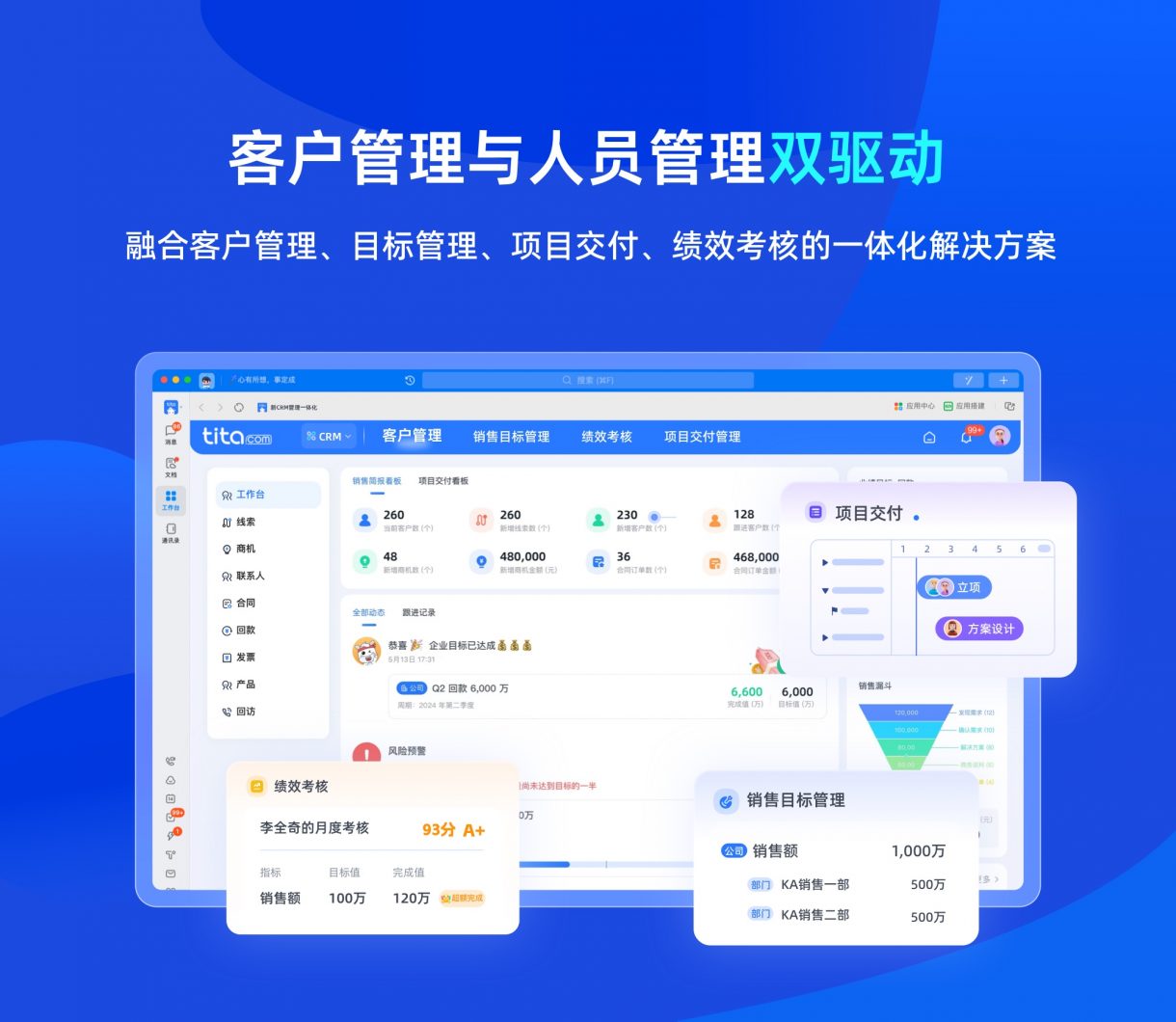
1. 让元数据为业务服务
1.1. 在过去十多年中,数据团队越来越擅长收集大量的数据
1.2. 公司如今正在收集越来越多关于其数据的数据,也就是元数据
-
1.2.1. dbt等ETL解决方案让跟踪和使用元数据变得容易,而云服务提供商则使栈中数据解决方案之间的元数据的互操作性变得更加无缝
-
1.2.2. 没有与之对应的背景信息的数据只不过是一堆数字一样,元数据本身并没有用,它只是关于其他信息的更多信息
1.3. 元数据的真正力量在于我们使用它的地点、时间和方式
- 1.3.1. 如何将它应用于我们正在试图解决的特定且亟须解决的问题
2. 通过数据发现释放元数据的价值
2.1. 数据仓库和数据湖的考量
-
2.1.1. 在过去几年中,云数据仓库和数据湖已成为现代数据栈的必备要素
-
2.1.2. 数据发现工具(或联合目录)能够提供帮助来确保你的数据环境不会变成数据沼泽
-
2.1.3. 数据湖具有无限的灵活性和可定制性,来支持广泛的用例,但随着这种更强的敏捷性而来的是与数据组织和治理相关的一系列其他问题
-
2.1.4. 随着数据运营的成熟和数据管道变得越来越复杂,传统的数据目录往往达不到你所期望的数据发现工具回答这些问题的方式
2.2. 数据目录可能淹没在数据湖甚至数据网格中
-
2.2.1. 数据目录经常被用作元数据的清单,并提供有关数据健康状况、可访问性和位置的信息
-
2.2.2. 帮助数据团队回答有关在哪里查找数据、数据代表了什么以及要如何使用数据的问题
-
2.2.3. 如果我们不知道这些数据是如何组织的,那么我们所有最好的计划(或管道)都是徒劳的
-
2.2.4. 从历史上看,许多公司都使用数据目录来加强数据质量和数据治理标准,因为他们通常依赖于数据团队手动输入和更新目录信息以跟踪数据资产的演变情况
-
2.2.5. 在数据湖中,数据是分布式的,因此很难记录数据在其生命周期过程中的演变情况
-
2.2.6. 存储在传统数据目录中的数据也难以扩展和演变,以满足分布式数据架构(如数据网格)的需求
2.3. 从传统的数据目录过渡到现代的数据发现
-
2.3.1. 随着时间的推移,了解不同数据资产之间的关系至关重要,但这中间往往缺乏传统数据目录的维度
-
2.3.2. 公司仍需要知道他们的数据存放在哪里以及谁可以访问它,并能够评估其整体健康状况
-
2.3.3. 虽然许多数据目录都有以用户界面为中心的工作流,但数据工程师需要拥有以编程方式与数据目录进行交互的灵活性
-
2.3.4. 数据可以通过多个入口点进入数据湖,而工程师需要一个能够适应该情况并说明每个入口点的数据目录
-
2.3.5. 与数据在输入前进行清洗和处理的数据仓库不同,数据湖在不对端到端健康状况做任何假设的情况下就接收了原始数据
-
2.3.5.1. 如果没有数据发现工具和数据沿袭,那么数据湖中的故障可能会变得混乱且难以诊断
-
2.3.5.2. 在数据湖中,可以通过多种方式与数据进行交互,而数据目录必须能够提供对正在使用的内容和未使用内容的理解
-
-
2.3.6. 数据发现,换句话说,联合数据目录,是一种植根于Dehghani数据网格模型中提出的分布式面向领域架构的新方法
-
2.3.7. 填补了传统数据目录不足的空白
-
2.3.7.1. 跨数据湖的自动化扩展
2.3.7.1.1. 使用机器学习,数据发现工具来自动跟踪表级和字段级沿袭,映射上游和下游的依赖关系
-
2.3.7.2. 提供对数据健康状况的实时可见性
2.3.7.2.1. 数据发现工具提供对数据当前状态的实时可见性,而不是其“编目”或理想状态
-
2.3.7.3. 利用数据沿袭了解数据的业务影响
2.3.7.3.1. 数据发现工具的灵活性和动态性让其成为将数据沿袭带入数据湖的理想载体,让你能够在正确的时间获得正确的信息,并在诸多可能的输入和输出之间建立联系
-
2.3.7.4. 支持跨领域自助式服务的数据发现
2.3.7.4.1. 数据发现工具还支持自助式服务,让人们无须专门的支持团队即可轻松利用和理解他们的数据
-
2.3.7.5. 确保跨数据湖的治理和优化
2.3.7.5.1. 现代数据发现工具让公司不仅可以了解在数据生命周期中正在使用、消费、存储和弃用哪些数据,还可以了解这些过程是如何进行的
-
-
2.3.8. 数据发现工具还可以让利益相关方轻松识别出最重要的数据资产(也就是经常被查询的数据),以及那些未被使用的数据资产
- 2.3.8.1. 一些最好的数据目录越来越多地采用分布式特定领域的数据发现,为团队提供了在数据生命周期的各个阶段完全信任并利用数据所需的可见性
-
2.3.9. 如果你不信任数据,那么无论数据多具有“可发现性”也没什么用
- 2.3.9.1. 尽早确定数据质量在公司数据之旅中的优先级会很有帮助,以避免不必要且带来麻烦的数据宕机
3. 决定何时开始处理公司的数据质量问题
3.1. 更关心要怎样才能推动采集数据,让这个事启动并运行起来
3.2. 构建数据平台是一个多阶段的过程,而数据团队必须兼顾数十个相互竞争的优先事项
3.3. 如果公司不使用或不信任你的数据,那么你为数据平台统治而制定的最佳计划就成为白日梦
3.4. 七个领先指标
-
3.4.1. 在最近迁移到云端
-
3.4.1.1. 无论出于何种原因进行迁移,你都必须在保持速度的同时建立对数据平台的信任
-
3.4.1.2. 应该花更多的时间来构建数据管道,而不是把时间用在编写测试以防止出现问题上
-
-
3.4.2. 数据栈随着更多的数据源、更多的表和更高的复杂性而扩展
-
3.4.2.1. 数据产品的规模不是投资数据质量的唯一标准,但的确是一个重要因素
-
3.4.2.2. 投资数据可观测性前应该拥有多少数据源、数据管道和数据表方面并没有硬性规定,但一个较好的指导原则是拥有50张以上的表
-
3.4.2.3. 重要的考虑因素是数据栈增长的速度
-
-
3.4.3. 数据团队正在扩充
-
3.4.3.1. 雇用更多的数据专家,并将现代工具应用到你的数据栈中
-
3.4.3.2. 技术债将随时间慢慢积累,而你的数据团队将投入大量时间来清洗数据问题
-
-
3.4.4. 团队至少花费了30%的时间来解决数据质量问题
- 3.4.4.1. 数据工程师花费了太多的宝贵时间来修复问题而不是进行创新
-
3.4.5. 团队拥有比一年前更多的数据消费者
-
3.4.5.1. 数据为你的招聘决策、产品功能和预测分析提供了支持
-
3.4.5.2. 快速增长会导致业务相关方对数据的依赖程度增加,数据需求变得更加多样化,而最终导致需要更多的数据
-
3.4.5.3. 更多的数据也会带来更大的责任,因为不良数据进入你的数据生态系统的可能性也增加了
-
3.4.5.4. 越是数据驱动型的组织反而越会有更多的数据消费者来发现数据中出现的任何错误
-
-
3.4.6. 公司正在转向自助式服务分析模型
-
3.4.6.1. 公司正在转向自助式服务分析模型,以便为数据工程师腾出时间,并允许每个业务用户直接访问数据并与之进行交互
-
3.4.6.2. 到最后如果你的最终用户不信任数据,那么转向自助式服务分析模型的目的就会落空
-
3.4.6.3. 随着数据越来越成为数据驱动型组织日常运营不可或缺的一部分,对可靠数据的需求只会增加
-
3.4.6.4. 两种类型的数据质量问题
3.4.6.4.1. 你可以预测的(已知的未知)
3.4.6.4.2. 你不能预测的(未知的未知)
-
-
3.4.7. 数据是客户价值主张的关键部分
-
3.4.7.1. 每个应用程序都将很快成为一个数据应用程序
-
3.4.7.2. 当没有优先考虑数据质量时,数据团队和你的客户就会遭受损失
-
3.5. 数据质量源于信任
-
3.5.1. 组织需要信任他们的数据来为利益相关方提供干净可靠的数据
-
3.5.2. 宝贵的工程时间就会被浪费在救火数据宕机上,你为成为数据驱动型公司所做出的努力也会随着时间的推移而受阻,业务用户也将失去对数据的信任