现在全民AI大模型,虽然我不是算法工程师,但是作为IT从业者,多少应该了解一下。然而,论文太多,原理太难,那咱们就从实践开始,先实践看效果,再学习研究原理。
1. 存在价值及原因

简而言之:HuggingFace是菜鸟的福音,大佬的舞台,学术与工程的桥梁!
平台链接:https://huggingface.co/
2. 揭开神秘面纱
Hugging Face 是一个旨在推动自然语言处理(NLP)技术和工具发展的开源社区和公司。平台有海量的开源模型,以及数据集,致力于提供各种NLP任务中的最新技术、模型和工具,为开发者提供便捷的方式来使用、微调和部署这些技术。

2.1. 模型Model
- 自然语言处理:文本分类、文本生成,文本转语音、文本填空、文本摘要等;
- 计算机视觉:图片分类、物体识别、文本转图片、题、图片转文本、图片特征提取等;
- 音频:文本转语音、语音转文本、语音识别、语音分类等;
- 多模态:Image-Text-to-Text、Video-Text-to_text
2.2. 数据DataSet
互联网开源的一些最标准的语料库,可以用来训练或者微调你的模型,其特点为:
- 包含丰富的数据集:IMDB, CoNLL-2003和GLUE等;
- 简化数据集的下载、预处理操作;
- 提供数据集分割、采样和迭代器的功能;
2.3. 应用Space
2.4. 平台番外篇
2016年,法国创业者三名创业者Clément Delangue、Julien Chaumond 和 Thomas Wolf 在纽约成立了Hugging Face。
Hugging Face,它的第一个产品是一个聊天机器人。到2017年,Hugging Face聊天机器人拥有了独特的功能,并可以进行高效的对话。团队将其产品定位为为无聊青少年量身打造的个性鲜明的聊天机器人。2018年5月,完成种子融资。通过本轮融资,Hugging Face团队继续专注于以下领域:改进产品;建立一支优秀的工程师团队;深入研发自然语言对话,并撰写了几篇研究论文。虽然当时产品还没有带来可观的收入,但团队对核心价值和技术共享的强调为Hugging Face创造了一个转折点。
2018 年,Hugging Face迎来了关键时刻,Hugging Face的创始人在网上免费分享该应用的部分代码,其中一个重要的开源框架名为Transformers,目前已被下载超过一百万次。GitHub项目获得了上万颗星,这表明开源社区认为它很有价值。微软、谷歌和 Facebook 的研究人员一直在用它做实验,某些公司甚至在生产中使用了它。
Transformers 可用于各种任务,包括文本分类、信息提取、总结、文本生成和对话式人工智能。最终,Hugging Face团队迎来了一个转折点,将公司从一家不太赚钱的AI聊天机器人初创公司转变为未来估值十亿美元的独角兽。
在接下来的几年里,Hugging Face 团队继续专注于产品建设和社区发展,并取得了令人瞩目的成就:
- Hugging Face 已成为扩展最快的社区和使用最广泛的机器学习平台!平台上有 10 万个预训练模型和 1 万个数据集,涵盖 NLP、语音、时间序列、强化学习、计算机视觉、生物、化学等领域。Hugging Face Hub 已发展成为机器学习构建者开发、协作和部署尖端模型的家园。
- 目前有10000 多家公司使用 Hugging Face来构建机器学习技术,Hugging Face 帮助这些机器学习工程师和数据科学家团队节省了大量时间,加快了机器学习项目的进度。
- Hugging Face还领导着 BigScience,一个专注于研究和构建大语言模型的合作研讨会。这项计划汇集了来自不同领域和背景的1000多名研究人员,BigScience 致力于训练世界上最大的开源多语言模型。
Hugging Face为什么能成功?
- 赶上Transformer在AI领域爆火;
- 军阀混战,谷歌TensorFlow Bert, FaceBook PyTorch,跑一下模型需要各种环境;
- 人家是一个舞台,不是一个工具,那后来的人,也只能在这上面玩。
3. 基本操作指南
3.1. 数据选择与使用
- 语音数据集
语音数据集的特征:
- 小时数:小时数体现了数据集的大小,类似 NLP 数据集中的训练样例数量;
- 领域:数据的来源,比如有声读物、播客、YouTube 还是金融会议等;
- 说话风格:
- 叙述性(Narrated):按照给定的文本朗读
- 自发性(Spontaneous):没有固定剧本的对话
Hugging Face Hub 上最受欢迎的英语语音识别数据集整理如下:
| 数据集 | 小时数 | 领域 | 说话风格 | 大小写 | 标点 | 许可证 | 推荐用途 |
| LibriSpeech | 960 | 有声读物 | 叙述性 | ❌ | ❌ | CC-BY-4.0 | 学术基准测试 |
| Common Voice 11 | 3000 | 维基百科 | 叙述性 | ✅ | ✅ | CC0-1.0 | 非母语发言者 |
| VoxPopuli | 540 | 欧洲议会 | 演讲式 | ❌ | ✅ | CC0 | 非母语发言者 |
| TED-LIUM | 450 | TED 演讲 | 演讲式 | ❌ | ❌ | CC-BY-NC-ND 3.0 | 技术主题 |
| GigaSpeech | 10000 | 有声读物、播客、YouTube | 叙述性、自发性 | ❌ | ✅ | apache-2.0 | 多领域鲁棒性 |
| SPGISpeech | 5000 | 金融会议 | 演讲式、自发性 | ✅ | ✅ | User Agreement | 完全格式化的转写 |
| Earnings-22 | 119 | 金融会议 | 演讲式、自发性 | ✅ | ✅ | CC-BY-SA-4.0 | 口音多样性 |
| AMI | 100 | 会议 | 自发性 | ✅ | ✅ | CC-BY-4.0 | 嘈杂语音环境 |
Hugging Face Hub 上最受欢迎的中文语音识别数据集整理如下:
| 数据集 | 小时数 | 说明 |
| Chinese_dialect | 25000 | 各种方言 |
| Mandarin chinese | 15000 | 普通话 |
| miexed_speech_chinese_english | 2000 | 普通话和英语混合 |
更多中文语音数据集,可以看这里:https://huggingface.co/datasets?modality=modality:audio&sort=trending&search=chinese
多语言语音识别数据集,省略了训练小时数列(因为这取决于每个数据集有哪些语言,占比多少),改成了每个数据集的语言数量:
| 数据集 | 语言数量 | 领域 | 说话风格 | 大小写 | 标点 | 许可证 | 推荐用途 |
| Multilingual LibriSpeech | 6 | 有声读物 | 叙述性 | ❌ | ❌ | CC-BY-4.0 | 学术基准测试 |
| Common Voice 13 | 108 | 维基百科文本和众筹的言语 | 叙述性 | ✅ | ✅ | CC0-1.0 | 多样化的发言者集合 |
| VoxPopuli | 15 | 欧洲议会 | 自发性 | ❌ | ✅ | CC0 | 欧洲语言 |
| FLEURS | 101 | 欧洲议会 | 自发性 | ❌ | ❌ | CC-BY-4.0 | 多语言评估 |
2. 文本数据集
| 数据集 | 数据集描述 |
| IMDB数据集 | 大型电影评论数据集,为用户提供了超过5万条的电影评论 |
| Amazon Polarity数据集 | 该数据集包含来自亚马逊的超过3500万条产品评论 |
| Common Voice数据集 | 此数据集是音频数据和文本数据的混合。包含超过9000小时的录音信息及其书面记录文本 |
3. DataSet使用
# 导入数据集
from datasets import load_dataset加载托管的数据集:
dataset = load_dataset("imdb")加载远程数据集:
url = "https://github.com/crux82/squad-it/raw/master/"
data_files = {"train": url + "SQuAD_it-train.json.gz","test": url + "SQuAD_it-test.json.gz",
}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")加载本地数据集:
load_dataset("csv",data_files="my_file.csv")3.2. 模型选择与使用
Model选择
- 步骤一:根据关键字搜索模型
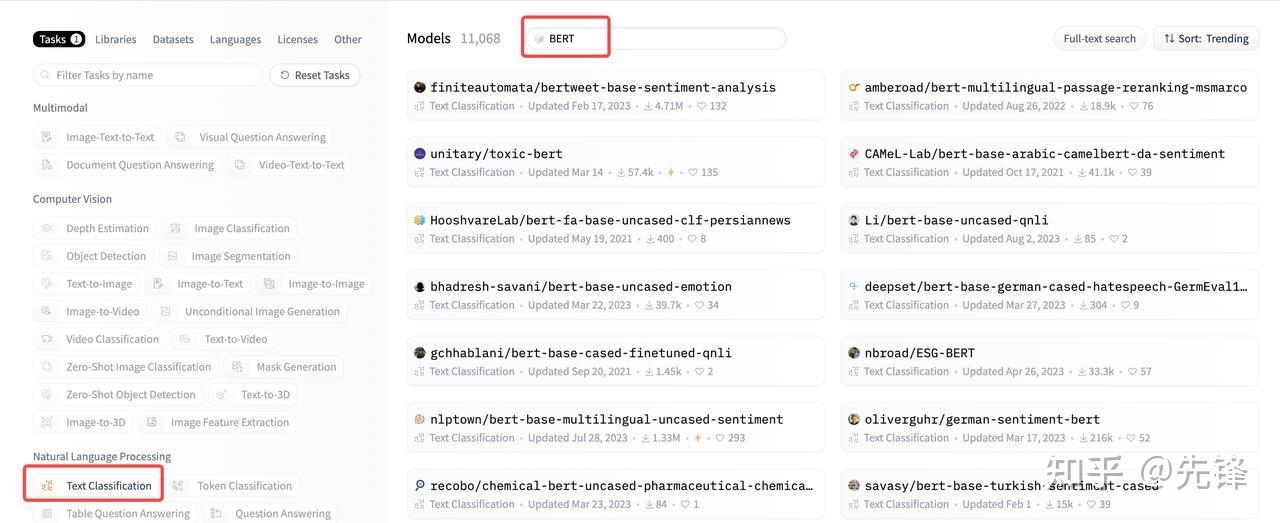
- 步骤二:看看效果
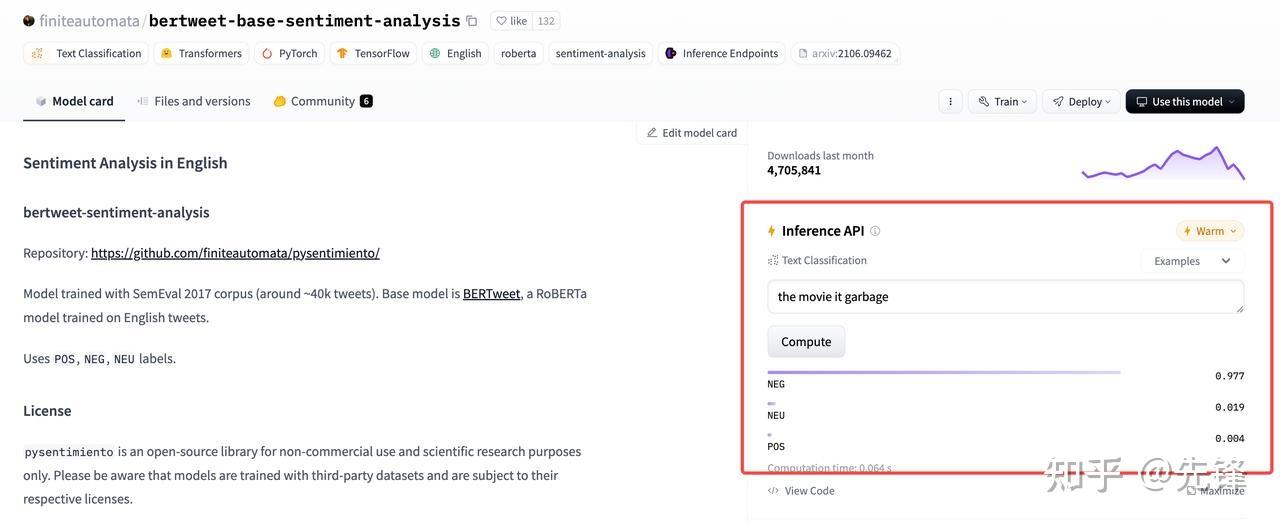
- 步骤三:查询协议
- 步骤四:开始使用
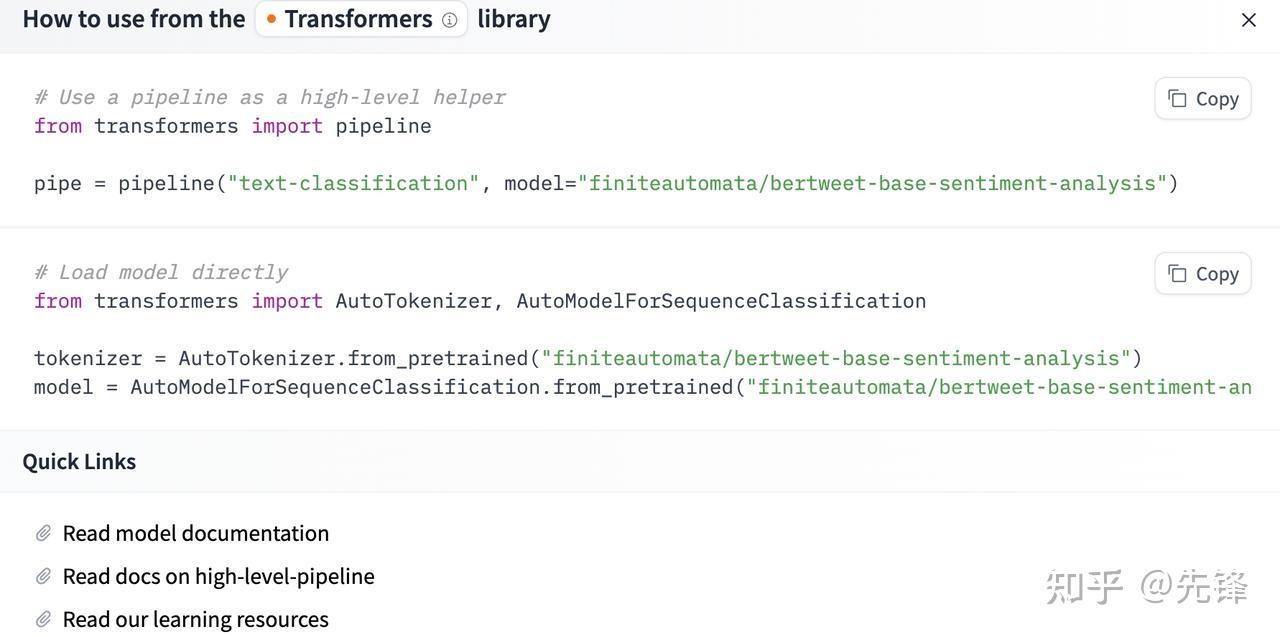
- 步骤五:微调模型
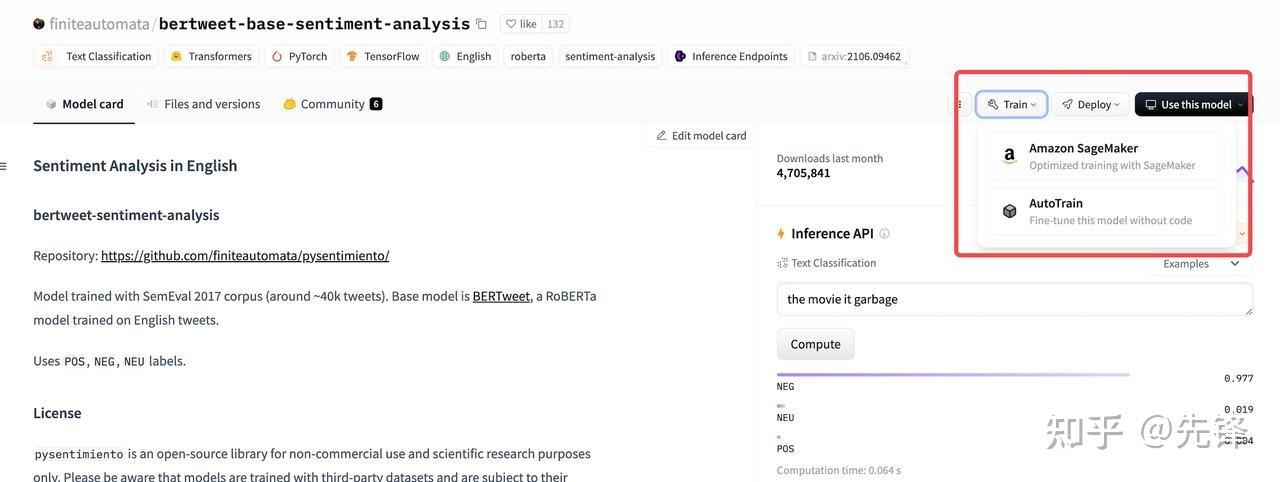
Model使用
Transformers 库中最基本的对象是 pipeline() 函数。它将模型与其必要的预处理和后处理步骤连接起来,使我们能够通过直接输入任何文本并获得最终的答案:
from transformers import pipelineclassifier = pipeline("sentiment-analysis")
classifier("I think hugging face is a good platform")输出如下:
No model was supplied, defaulted to distilbert/distilbert-base-uncased-finetuned-sst-2-english and revision af0f99b (https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english).
Using a pipeline without specifying a model name and revision in production is not recommended.
[{'label': 'POSITIVE', 'score': 0.9997380375862122}]pipeline将三步合在一起: preprocessing, passing the inputs through the model, and postprocessing:
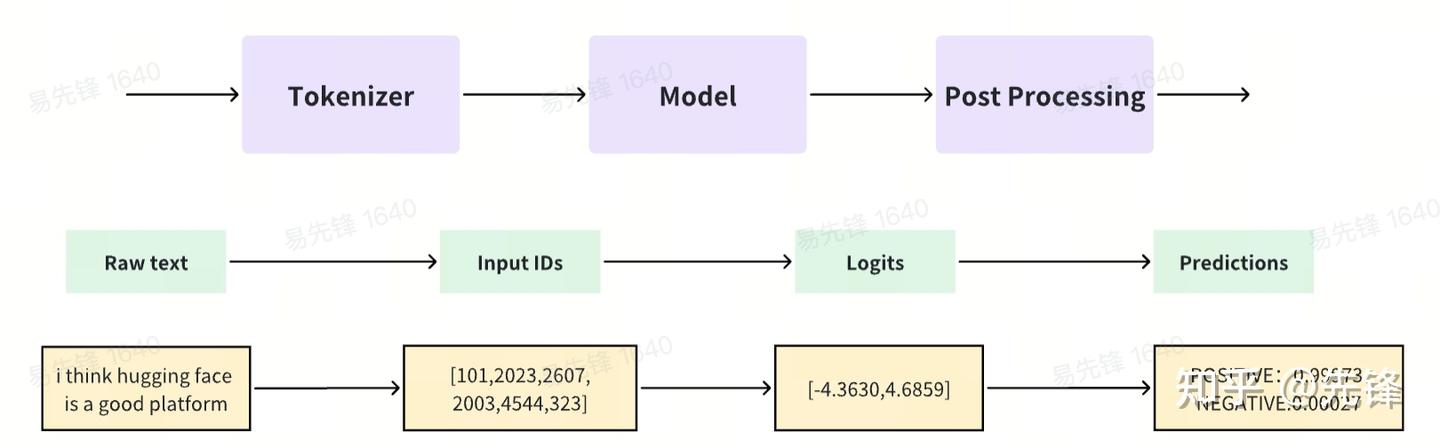
将一些文本传递到pipeline时涉及三个主要步骤:
- 文本被预处理为模型可以理解的格式。
- 预处理的输入被传递给模型。
- 模型处理后输出最终人类可以理解的结果。
3.3. 选择评价指标
查看有哪些评价指标:
from datasets import list_metrics
metrics_list = list_metrics()
len(metrics_list)
print(metrics_list)输出:274个,具体为:
['accuracy', 'bertscore', 'bleu', 'bleurt', 'brier_score', 'cer', 'character', 'charcut_mt', 'chrf', 'code_eval', 'comet', 'competition_math', 'confusion_matrix', 'coval', 'cuad',.....]
加载评价指标:
from datasets import load_metric
metric = load_metric('wer')4. 搓搓激动的小手
4.1. 验证想法

- 首先,Image-to-text,把图片转换为文字;
- 然后,Generate Text,生成故事;
- 最后,text-to-audio,文字转换为语音
图片转换为文字
from transformers import pipelinedef img2text(url):image_to_text = pipeline("image-to-text",model="Salesforce/blip-image-captioning-base")text = image_to_text(url)[0]["generated_text"]print(text)return textimg2text("basketball.jpg")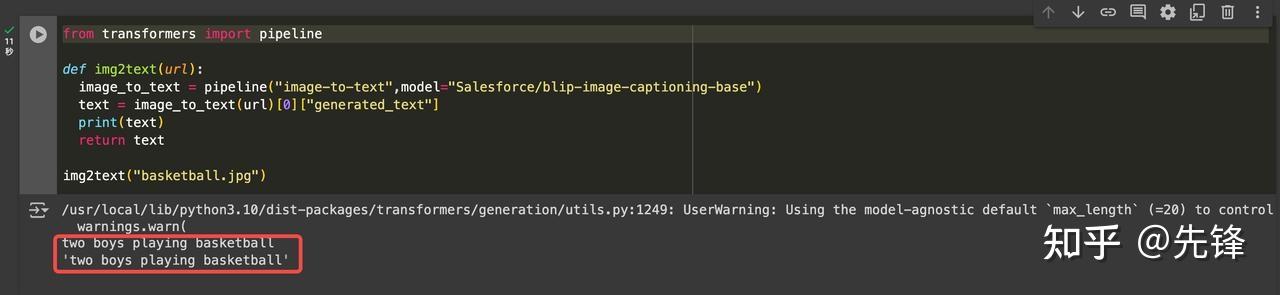
故事生成
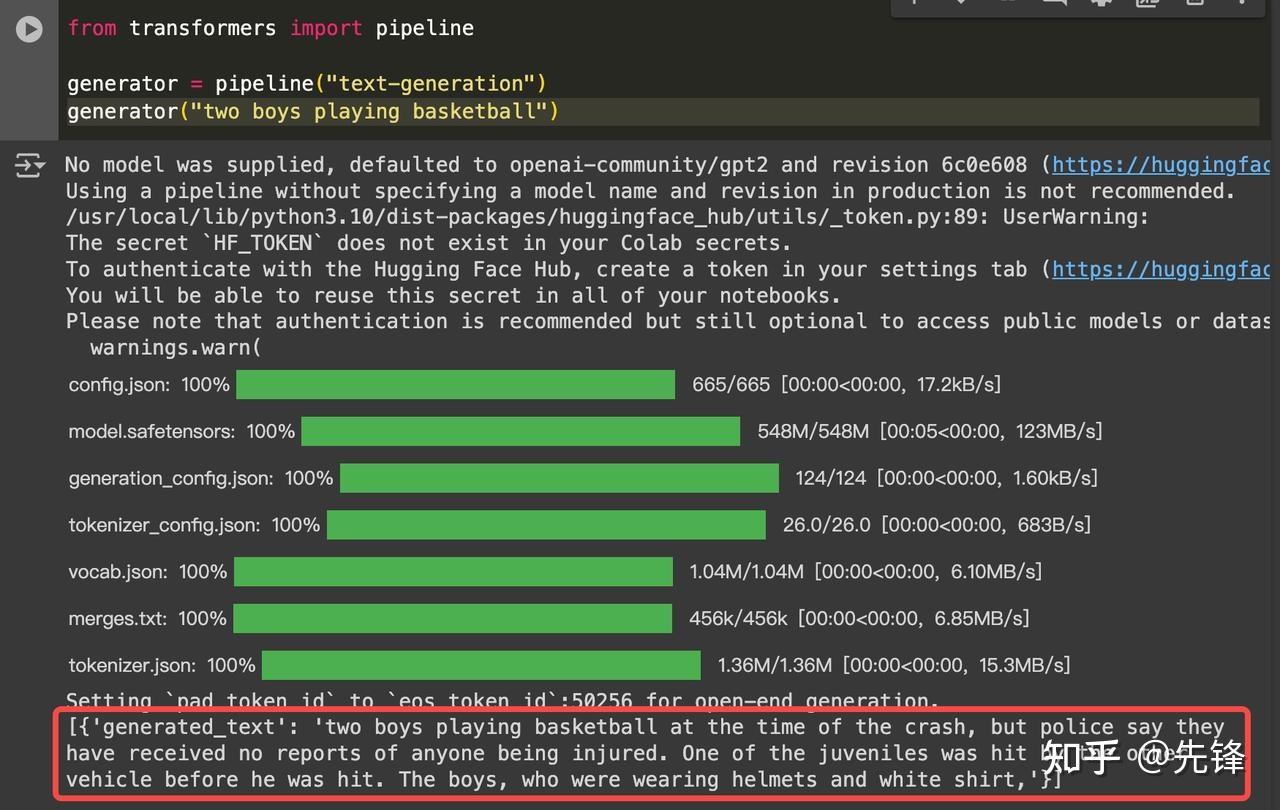
生成内容如下:
Two boys playing basketball at the time of the crash, but police say they have received no reports of anyone being injured. One of the juveniles was hit by the other vehicle before he was hit. The boys, who were wearing helmets and white shirt
文字转语音
from transformers import pipeline
from datasets import load_dataset
import soundfile as sf
import torchsynthesiser = pipeline("text-to-speech", "microsoft/speecht5_tts")embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embedding = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
# You can replace this embedding with your own as well.speech = synthesiser("Two boys playing basketball at the time of the crash, but police say they have received no reports of anyone being injured. One of the juveniles was hit by the other vehicle before he was hit. The boys, who were wearing helmets and white shirt", forward_params={"speaker_embeddings": speaker_embedding})sf.write("speech.wav", speech["audio"], samplerate=speech["sampling_rate"])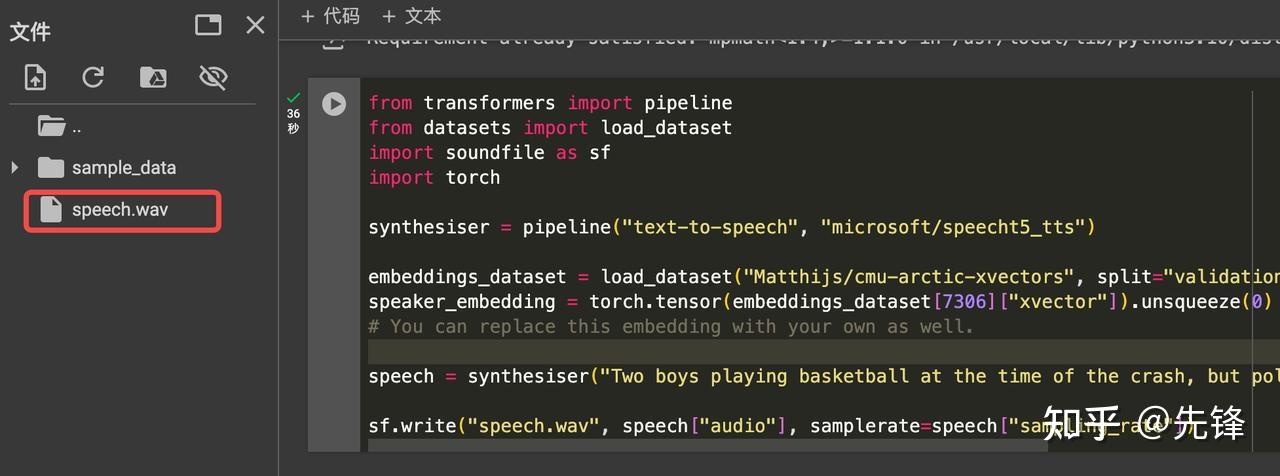
4.2 微调模型
我们选择微调一个语音识别模型,选择一个语音识别模型,以及微调的数据集:
- Whisper: https://huggingface.co/openai/whisper-small
- Common-voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0/viewer/zh-CN
处理微调数据
我们选择用common_voice来进行微调,这是一个多语言数据集,查看数据集划分信息:
>>> from datasets import get_dataset_split_names>>> get_dataset_split_names("mozilla-foundation/common_voice_13_0","zh-CN")
['train', 'validation', 'test', 'other', 'invalidated']导入数据:
from datasets import load_dataset, DatasetDictcommon_voice = DatasetDict()
common_voice["train"] = load_dataset("mozilla-foundation/common_voice_13_0", "zh-CN", split="train+validation"
)
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_13_0", "zh-CN", split="test"
)common_voice = common_voice.select_columns(["audio", "sentence"])print(common_voice)Pre-process the data set:
from transformers import WhisperProcessorprocessor = WhisperProcessor.from_pretrained("openai/whisper-small", language="zh", task="transcribe"
)from datasets import Audiosampling_rate = processor.feature_extractor.sampling_rate
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=sampling_rate))开始微调训练
从whisper-small模型,开始微调训练:
from transformers import WhisperForConditionalGenerationmodel = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
from functools import partial# 在训练期间不使用缓存,因为它和梯度检查点不兼容
model.config.use_cache = False# 为生成设置语言和任务,并重新启用缓存
model.generate = partial(model.generate, language="zh", task="transcribe", use_cache=True
)设置训练参数:
from transformers import Seq2SeqTrainingArgumentstraining_args = Seq2SeqTrainingArguments(output_dir="./whisper-small-xianfeng", # 在 HF Hub 上的输出目录的名字per_device_train_batch_size=16,gradient_accumulation_steps=1, # 每次 batch size 下调到一半就把这个参数上调到两倍learning_rate=1e-5,lr_scheduler_type="constant_with_warmup",warmup_steps=50,max_steps=500, # 如果您有自己的 GPU 或者 Colab 付费计划,上调到 4000gradient_checkpointing=True,fp16=True,fp16_full_eval=True,evaluation_strategy="steps",per_device_eval_batch_size=16,predict_with_generate=True,generation_max_length=225,save_steps=500,eval_steps=500,logging_steps=25,report_to=["tensorboard"],load_best_model_at_end=True,metric_for_best_model="wer",greater_is_better=False,push_to_hub=True,
)开始训练:
from transformers import Seq2SeqTrainertrainer = Seq2SeqTrainer(args=training_args,model=model,train_dataset=common_voice["train"],eval_dataset=common_voice["test"],data_collator=data_collator,compute_metrics=compute_metrics,tokenizer=processor,
)trainer.train()训练效果如下所示:
5. 学习资料
| 资料名 | 资料说明 |
| Hugging Face Hub 和开源生态介绍 | Hugging Face中文社区负责人,对于Hugging Face的介绍和分享视频 |
| AI 快速发展年,来自 Hugging Face 的开源最新进展 | HuggingFace机器学习工程师,对于HuggingFace的进展分享和介绍视频 |
| Hugging Face NLP Course | 官方课程,包含NLP基本介绍,相关数据集介绍,以及如何微调一个模型 |
| Hugging Face Audio Course | 官方课程,包含音频基础知识,音频数据处理,transformer结构,语音识别,从文本到语音 |
| https://huggingface.co/docs | 官方介绍文档 |
参考资料
https://huggingface.co/ByteDance
NLP Projects to Boost Your Resume
Natural Language Processing with Hugging Face and Transformers