语言能打败数值回归吗?基于语言的多模态轨迹预测
语言模型在语境理解和生成表现方面表现出了令人印象深刻的能力。受语言基础模型最近成功的启发,提出了LMTraj(基于语言的多模态轨迹预测器),它将轨迹预测任务转化为一种问答问题。与将轨迹坐标序列视为连续信号的传统数值回归模型不同,将其视为文本提示等离散信号。特别地,首先将轨迹坐标的输入空间转换为自然语言空间。这里,行人的整个时间序列轨迹被转换为文本提示,场景图像通过图像字幕被描述为文本信息。然后将转换后的数值和图像数据打包到问答模板中,以用于语言模型。接下来,为了指导语言模型理解和推理高级知识,如场景背景和行人之间的社会关系,引入了一个辅助的多任务问答。然后,用提示数据训练了一个数字标记器。鼓励标记器很好地分离整数和小数部分,并利用它来捕获语言模型中连续数字之间的相关性。最后,使用数字标记器和所有问答提示来训练语言模型。在这里,提出了一种基于波束搜索的最有可能预测和一种基于温度的多模态预测,以实现确定性和随机性推断。应用改进的LMTraj,表明基于语言的模型可以成为一个强大的行人轨迹预测器,并且优于现有的基于数值的预测方法。广泛的实验表明,改进的LMTraj可以成功地理解社会关系,并在公共行人轨迹预测基准上准确地推断出多模式未来。
QA模板,用于将原始轨迹数据转换为提示,见表4-1。
表4-1 QA模板,用于将原始轨迹数据转换为提示

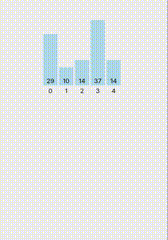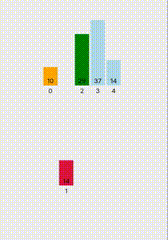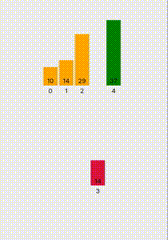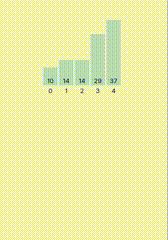
文本预训练标记器和数字数据优化标记器的比较如图4-12所示。

图4-12 文本预训练标记器和数字数据优化标记器的比较
在图4-12中,在带有黄色或白色突出显示颜色的括号下,表示相应的字母已被标记。绿色突出显示令牌包含一个6的整数。