1
点击查看代码
import [pandas](https://wenku.csdn.net/doc/6412b725be7fbd1778d4940f?spm=1055.2569.3001.10083) as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
data = pd.read_csv('data.csv')
[means](https://wenku.csdn.net/doc/6401abddcce7214c316e9c60?spm=1055.2569.3001.10083) = data.mean(axis=0)
grand_mean = data.values.mean()
ss_[total](https://wenku.csdn.net/doc/31nmcu1yk4?spm=1055.2569.3001.10083) = ((data.values - grand_mean) ** 2).sum()
df_total = data.size - 1
ms_total = ss_total / df_total
ss_factor1 = ((means[:3] - grand_mean) ** 2).sum() * 3
df_factor1 = 2
ms_factor1 = ss_factor1 / df_factor1
ss_factor2 = ((means[3:6] - grand_mean) ** 2).sum() * 3
df_factor2 = 3
ms_factor2 = ss_factor2 / df_factor2
ss_interaction = (((data.groupby(['Variety', 'Fertilizer']).mean() - means.reshape(3, 3)) ** 2).sum().sum() * 3)
df_interaction = 6
ms_interaction = ss_interaction / df_interaction
ss_error = ss_total - ss_factor1 - ss_factor2 - ss_interaction
df_error = df_total - df_factor1 - df_factor2 - df_interaction
ms_error = ss_error / df_error
f_factor1 = ms_factor1 / ms_error
p_factor1 = 1 - sm.stats.f.cdf(f_factor1, df_factor1, df_error)
f_factor2 = ms_factor2 / ms_error
p_factor2 = 1 - sm.stats.f.cdf(f_factor2, df_factor2, df_error)
f_interaction = ms_interaction / ms_error
p_interaction = 1 - sm.stats.f.cdf(f_interaction, df_interaction, df_error)
print('Factor 1 (Variety): F = {:.2f}, p = {:.4f}'.format(f_factor1, p_factor1))
print('Factor 2 (Fertilizer): F = {:.2f}, p = {:.4f}'.format(f_factor2, p_factor2))
print('Interaction: F = {:.2f}, p = {:.4f}'.format(f_interaction, p_interaction))
model = ols('Yield ~ Variety + Fertilizer + Variety:Fertilizer', data).fit()
tukey = sm.stats.multicomp.pairwise_tukeyhsd(model.fittedvalues, data['Variety:Fertilizer'])
print(tukey.summary())
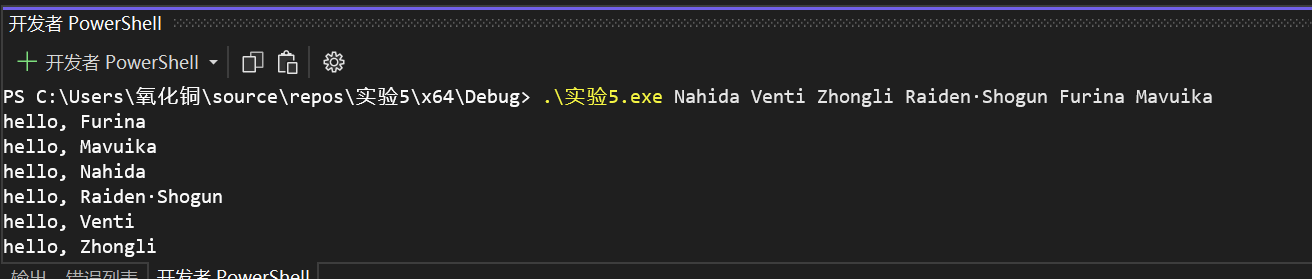
print("学号后四位:3032")
点击查看代码
import pandas as pd
import numpy as np
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
data = { 'City': np.tile(np.arange(1, 5), 12), 'Location': np.repeat(np.tile(np.arange(1, 4), 8), 4), 'Ad': np.repeat(np.tile(np.arange(1, 3), 4), 6), 'Decoration': np.repeat(np.arange(1, 3), 24), 'Sales': [ 45, 50, 48, 55, # Location 1, Ad 1, Decoration 1, 2 40, 45, 43, 52, # Location 2, Ad 1, Decoration 1, 2 38, 42, 40, 47, # Location 3, Ad 1, Decoration 1, 2 46, 54, 49, 58, # Location 1, Ad 2, Decoration 1, 2 39, 44, 41, 53, # Location 2, Ad 2, Decoration 1, 2 37, 43, 39, 48, # Location 3, Ad 2, Decoration 1, 2 ]
}
df = pd.DataFrame(data)
model = ols('Sales ~ C(Location) + C(Ad) + C(Decoration) + C(Location):C(Ad) + C(Location):C(Decoration) + C(Ad):C(Decoration) + C(Location):C(Ad):C(Decoration)', data=df).fit()
anova_results = anova_lm(model)
print(anova_results)
alpha = 0.05
significant = any(anova_results['PR(>F)'] < alpha)
if significant: print(f"在 {alpha:.2f} 的显著性水平下,至少有一组的销售量存在显著差异。")
else: print(f"在 {alpha:.2f} 的显著性水平下,销售量无显著差异。")
print("学号后四位:3032")