数据的分布和映射是数据分析中的两个重要概念。它们帮助我们理解数据的特征,并为后续的数据处理和分析提供基础。
数据的分布
定义:数据的分布描述了数据集中每个值出现的频率或概率。它提供了数据集的形状、中心趋势和离散程度的信息。
目的:通过分析数据的分布,我们可以了解数据的特征,比如数据是否对称、是否有异常值、数据的集中趋势等。
常见分布类型:
- 离散分布:数据只能取特定的、可数的值。例如,抛掷一个骰子的结果就是一个离散分布,可能的值是1、2、3、4、5和6。
- 连续分布:数据可以取一个区间内的任何值。例如,人的身高或体重就是连续分布,因为它们可以取无限多的值。
常见的数据分布:
- 均匀分布:每个值出现的概率相同。
- 二项分布:描述了在固定次数的独立实验中成功次数的分布,每次实验有两种可能的结果。
- 正态分布:也称为高斯分布,是一种对称的、钟形的连续分布,其均值、中位数和众数相同。
- 指数分布:描述了在泊松过程中事件之间的时间间隔。
- 泊松分布:描述了在固定的时间或空间间隔内事件发生的次数。
数据的映射
定义:数据的映射是指将数据从一种形式转换为另一种形式的过程。这可以包括数据的清洗、转换、归一化、标准化等。
目的:数据映射的目的是使数据更适合于分析或机器学习模型的输入。通过映射,我们可以将数据转换为更易于处理的形式,比如将分类数据转换为数值数据。
常见的数据映射方法:
- 数据清洗:去除或纠正数据集中的错误、不一致或不完整的数据。
- 数据转换:将数据从一种格式或结构转换为另一种,例如,将非结构化数据转换为结构化数据。
- 归一化:将数据缩放到一个特定的范围,通常是0到1,以便于比较和处理。
- 标准化:将数据转换为具有特定均值和标准差的分布,通常是均值为0,标准差为1的正态分布。
以下是对医疗花费预测的数据分布和映射
代码说明
-
导入库:
import pandas as pd import matplotlib.pyplot as plt import seaborn as snspandas用于数据处理和分析。matplotlib.pyplot用于绘制基本图形。seaborn是基于matplotlib的高级可视化库,提供更美观的图表。
-
读取CSV文件:
train_df = pd.read_csv('D:/迅雷下载/第6章 医疗花费预测(1)/第6章 医疗花费预测/train.csv') test_df = pd.read_csv('D:/迅雷下载/第6章 医疗花费预测(1)/第6章 医疗花费预测/test.csv')- 使用
pd.read_csv读取训练和测试数据集。
- 使用
-
查看数据结构:
print("Train Data Head:") print(train_df.head()) print("\nTest Data Head:") print(test_df.head())- 打印数据集的前几行,以便了解数据的结构和内容。
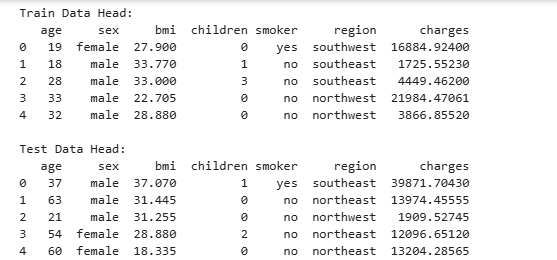
- 打印数据集的前几行,以便了解数据的结构和内容。
-
绘制年龄分布图:
plt.figure(figsize=(10, 6)) sns.histplot(train_df['age'], bins=20, kde=True) plt.title('Age Distribution') plt.xlabel('Age') plt.ylabel('Frequency') plt.show()- 使用
seaborn的histplot绘制年龄的直方图,并添加核密度估计(KDE)曲线。
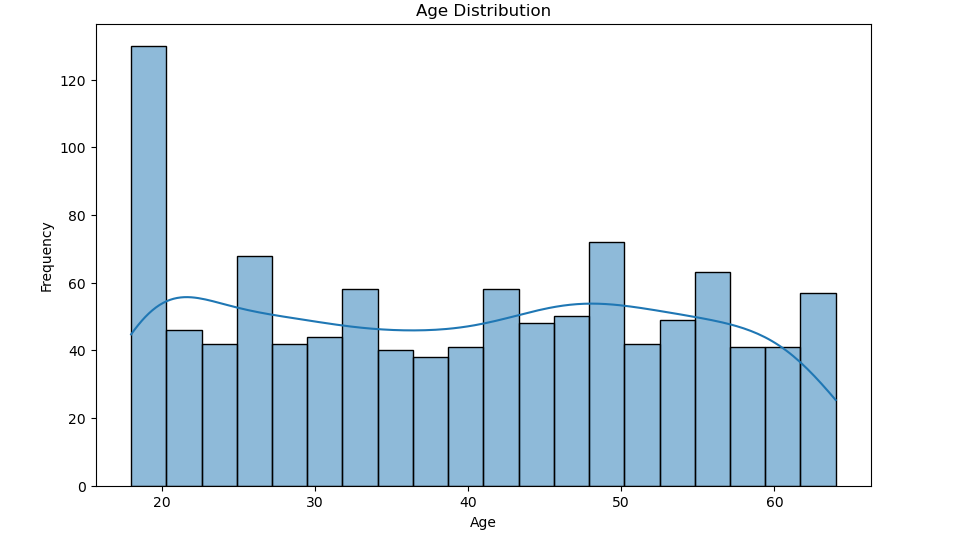
- 使用
-
绘制BMI分布图:
plt.figure(figsize=(10, 6)) sns.histplot(train_df['bmi'], bins=20, kde=True) plt.title('BMI Distribution') plt.xlabel('BMI') plt.ylabel('Frequency') plt.show()- 同样的方法绘制BMI的分布图。
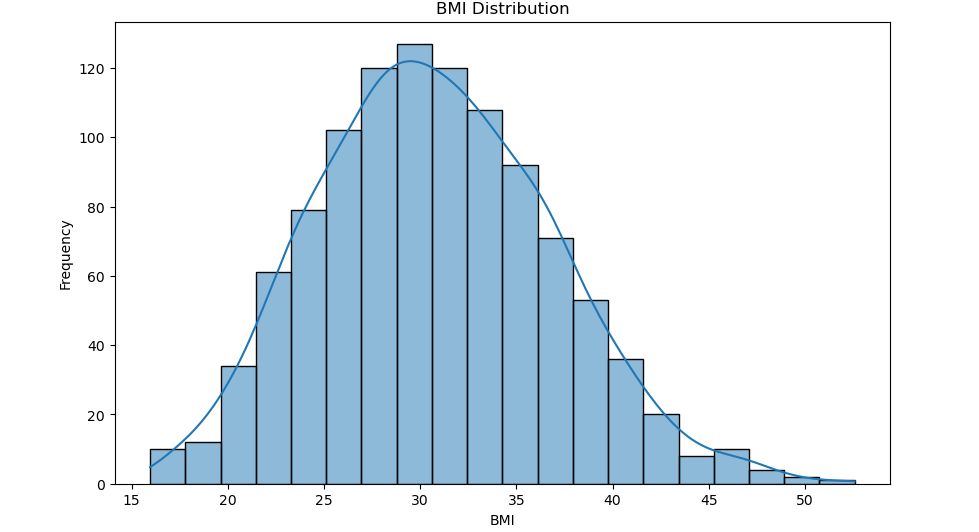
- 同样的方法绘制BMI的分布图。
-
绘制费用分布图:
plt.figure(figsize=(10, 6)) sns.histplot(train_df['charges'], bins=20, kde=True) plt.title('Charges Distribution') plt.xlabel('Charges') plt.ylabel('Frequency') plt.show()- 绘制医疗费用的分布图。
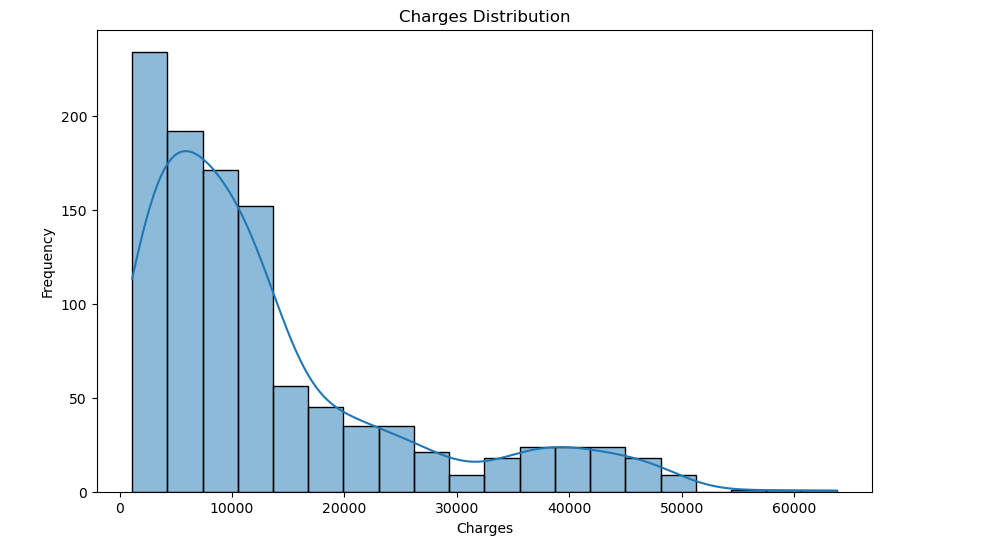
- 绘制医疗费用的分布图。
-
数据映射:
train_df['sex'] = train_df['sex'].map({'male': 0, 'female': 1}) test_df['sex'] = test_df['sex'].map({'male': 0, 'female': 1})train_df['smoker'] = train_df['smoker'].map({'yes': 1, 'no': 0}) test_df['smoker'] = test_df['smoker'].map({'yes': 1, 'no': 0})region_mapping = {'northeast': 0, 'northwest': 1, 'southeast': 2, 'southwest': 3} train_df['region'] = train_df['region'].map(region_mapping) test_df['region'] = test_df['region'].map(region_mapping)- 将性别、吸烟状态和区域信息映射为数值,以便后续分析和建模。
-
查看映射后的数据:
print("\nTrain Data Head (After Mapping):") print(train_df.head()) print("\nTest Data Head (After Mapping):") print(test_df.head())- 打印映射后的数据集前几行以确认映射成功。

- 打印映射后的数据集前几行以确认映射成功。
-
绘制性别分布图:
plt.figure(figsize=(10, 6)) sns.countplot(x='sex', data=train_df) plt.title('Sex Distribution') plt.xlabel('Sex (0: Male, 1: Female)') plt.ylabel('Count') plt.show()- 使用
countplot绘制性别的分布图。
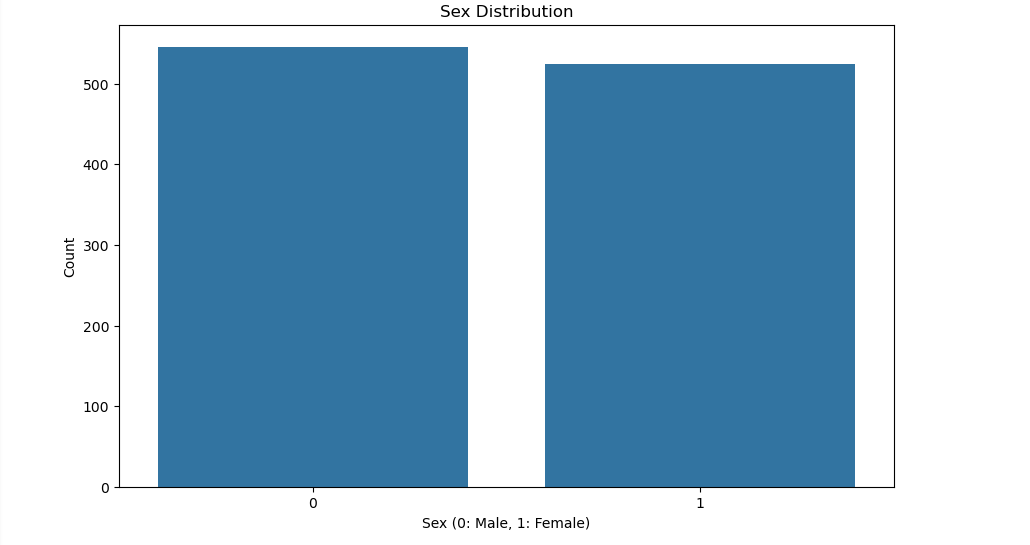
- 使用
-
绘制吸烟状态分布图:
plt.figure(figsize=(10, 6)) sns.countplot(x='smoker', data=train_df) plt.title('Smoker Distribution') plt.xlabel('Smoker (0: No, 1: Yes)') plt.ylabel('Count') plt.show()- 绘制吸烟状态的分布图。
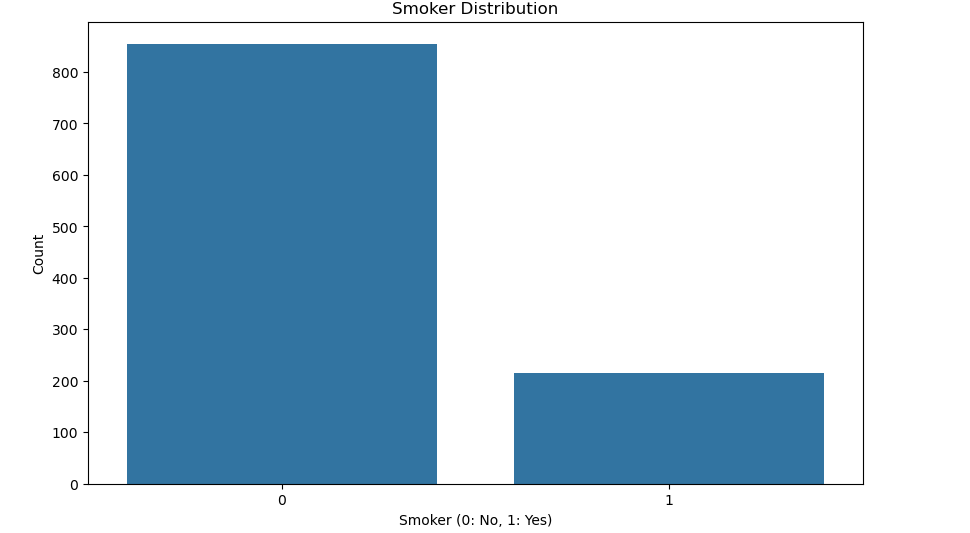
- 绘制吸烟状态的分布图。
-
绘制区域分布图:
plt.figure(figsize=(10, 6)) sns.countplot(x='region', data=train_df) plt.title('Region Distribution') plt.xlabel('Region (0: Northeast, 1: Northwest, 2: Southeast, 3: Southwest)') plt.ylabel('Count') plt.show()- 绘制不同区域的分布图。

- 绘制不同区域的分布图。
总结
这个示例展示了如何使用Python进行数据分析与可视化,涵盖了数据读取、数据结构查看、数据分布分析和数据映射等步骤。通过这些可视化图表,可以更直观地理解数据的特征和分布情况,为后续的分析和建模打下基础。


.assets/wps138.jpg)