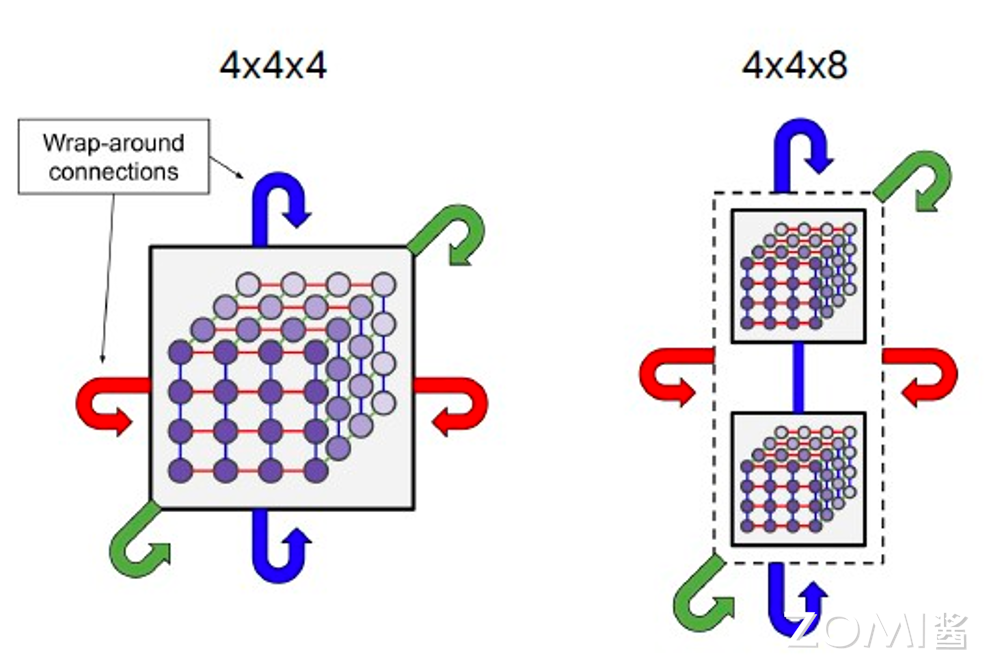
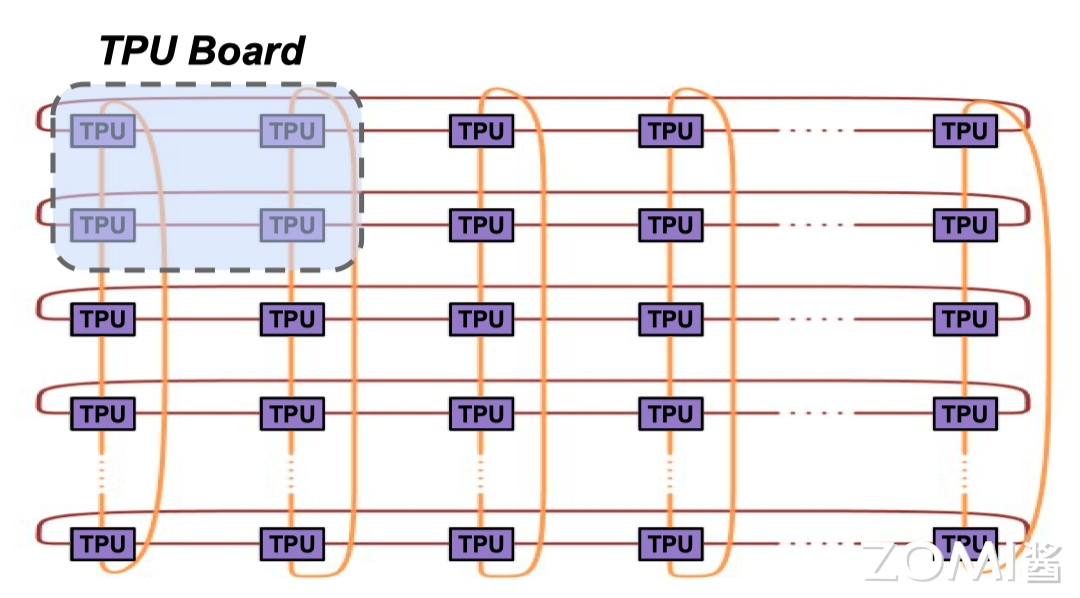
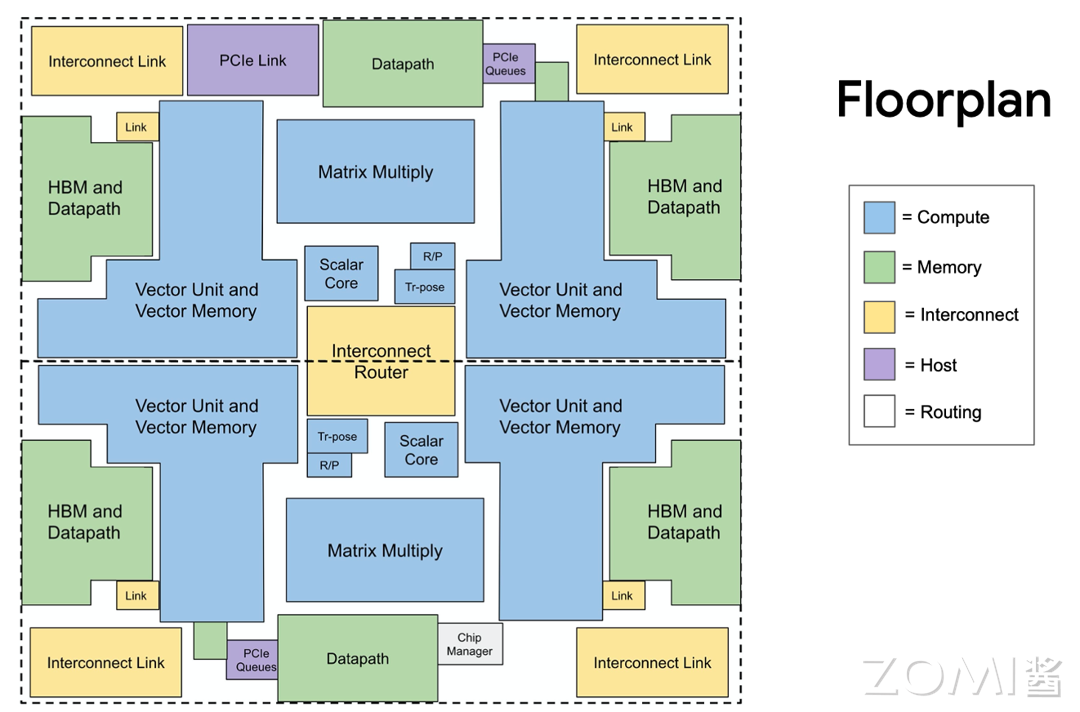
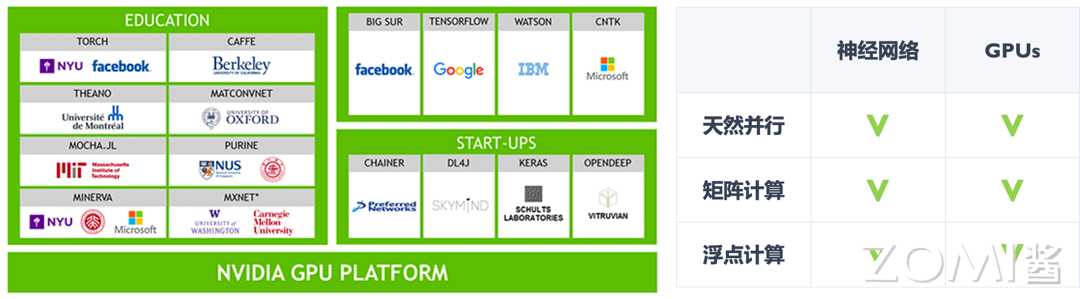
“大模型的出现颠覆了我们学习、研究和生活的方式,对于现在的年轻人来说,掌握 AI 是未来生存、工作的必要技能。”
崔家齐是一位正在北京大学工学院就读的硕士研究生,主攻机器人方向研究。机器人开发领域对交叉学科的知识融合度要求度非常高,每天都处于技术杂糅的状态里,是家齐和同学们感受最明显的挑战之一。一次上课时了解到通义灵码,让他找到了可以快速解决这个问题的方法。
“之前在北大信息科学技术学院开设的创新课程里,通义灵码的老师来做了一次分享,也让我第一次了解到大模型技术可以直接嵌入到编程环境里,我只要输入自然语言,通义灵码就可以帮我编写成片的代码,并在编程过程中为我提供代码的续写和补充,极大地提高了我们的学习和编程效率”。 崔家齐回忆起和通义灵码初次相识时的场景。
他还介绍,机器人开发每天需要接触很多新的通讯协议、控制架构等,现在即使同学们对相关领域完全不懂,也可以先通过使用通义灵码自然语言生成的代码获得提示,了解某些从未使用过的函数具体使用方法、代码架构的设计等,再结合需求进行具体编程, “之前一两周的开发工作量,我现在一两天就可以完成了”。
在感受到通义灵码带来的效率提升后,崔家齐也将这款智能编程助手推荐给了更多同学。最近,通义灵码正和他所在的实验室的师兄师弟们一起,参与到一款用于人体躯干康复的外骨骼机构项目开发中,“我们希望能够改变传统运动康复里机械臂相对单一的应用模式,通过对人体康复力的在线估计等,基于个体差异,实现针对不同康复阶段患者的、可变刚度的智能辅助机构”,家齐介绍了同学们要在这个创新项目中实现的目标。

在这个项目开发的过程中,同学们需要大量地运用代码,去实现机器人设备的控制、对人体的姿态力估计等特殊算法,而这些知识可能是之前他们并不了解的。 “在进行基本搭建时,通义灵码帮我们介绍了很多之前不熟悉领域的代码和函数的架构,此外,用它的代码优化功能还帮我们实现了集群和代码的调优,让我们整个项目可以做得很快。”

家齐进一步介绍了在提升团队协作效率方面,通义灵码也有帮助。 参与项目的同学会按照通义灵码智能生成的整体项目框架做分工,每个人负责一部分,提升工作上的同步效率,并阶段性地将各自编写的文件交给通义灵码汇总成整体的工程性文件,较好地实现了从总体计划到分工,再到整合的过程。
谈到对未来的规划,崔家齐表示将继续深入目前领域的研究,并希望推动机器人在实际场景的落地应用,“随着机器人技术越来越成熟,它和人之间的交互形式可以更多样。自己在这个领域学习了比较长的时间,后面也计划从科研的角度、工业的角度继续做机器人的开发和深入研究。也希望继续和通义灵码一起去实现更大的工程。”

2024 年起,通义灵码已先后与北京、上海、西安、南京等城市十余所高校联合举办高校训练营、路演&巡展、AI 通识课等,帮助数十万名同学打开“AI 时代下的开发者成长指南”。 接下来,通义灵码还将与阿里云云工开物计划一起,向超过 100 所高校师生分享通义灵码背后的技术解析、指导具体实践操作。
未来,通义灵码将助力千万如家齐一样的大学生、青年开发者投入到科技创新中,让更多梦想照进现实的速度更快一点。如果你希望通义灵码来到你的学校,欢迎通过评论留言告讨我们。如果你也有和通义灵码的故事,欢迎邮件联系:yx260241@alibaba-inc.com