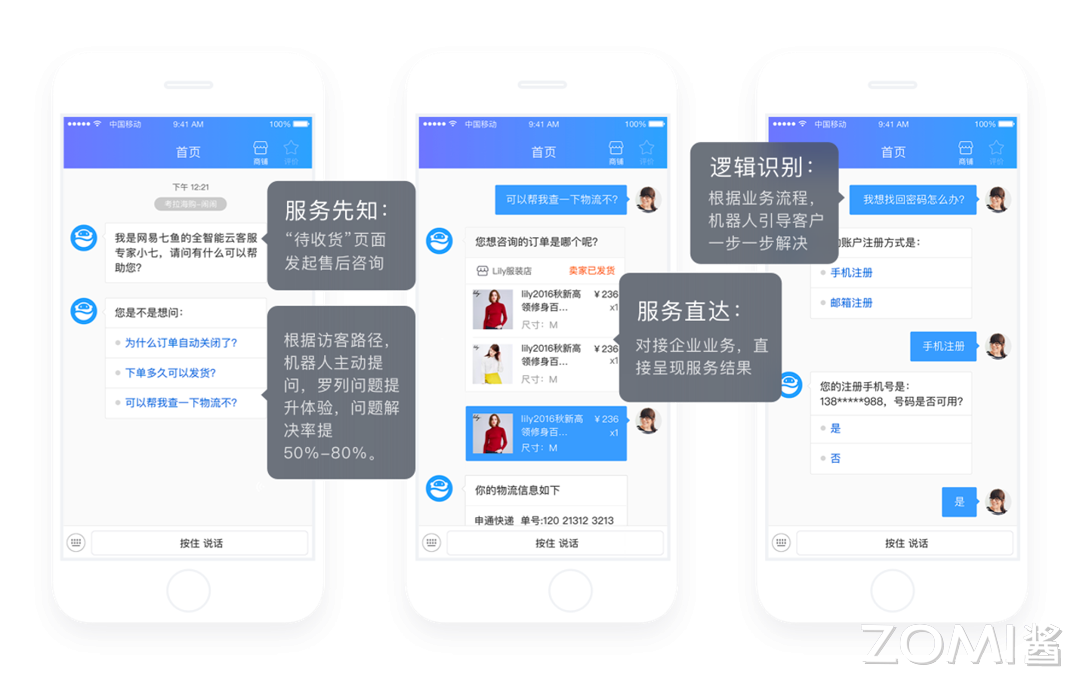
SLF4J的门面设计模式
SLF4J(Simple Logging Facade for Java)是一套日志接口,它提供了一种一致的API来使用不同的日志框架,如java.util.logging(JUL)、Logback、Log4j、Log4j 2等。SLF4J的设计基于门面(Facade)设计模式,这种设计模式为子系统中的一组接口提供一个统一的高层接口,使得子系统更容易使用。
在Java的日志系统中,存在多种不同的日志框架,每个框架都有其独特的配置和使用方式。如果开发者直接使用这些日志框架的API,当需要更换日志框架时,需要修改大量的代码。而SLF4J的出现解决了这一问题,它提供了一个统一的日志接口,开发者只需使用SLF4J的API,就可以在运行时嵌入他们想使用的日志框架。
SLF4J的这种门面设计模式不仅简化了日志框架的使用,还提高了系统的可维护性和可扩展性。通过使用SLF4J,开发者可以轻松地切换日志框架,而无需修改大量的代码。同时,SLF4J还支持多种日志框架的桥接,使得在一个系统中可以同时使用多种日志框架。
优点
简化调用:通过提供一个统一的接口,简化了对多个日志框架的调用过程,降低了系统的复杂性。
解耦:将日志记录的逻辑与具体的日志框架解耦,提高了系统的灵活性和可扩展性。
易于维护:当需要更换日志框架时,只需修改配置文件或适配器,而无需修改应用程序的源代码,降低了维护成本。
关于门面设计模式,参见:设计模式--外观模式
SLF4J的实现机制
SLF4J的核心接口是Logger,它提供了不同级别的日志记录方法,如debug、info、warn、error等。开发者通过调用LoggerFactory.getLogger()方法来获取一个Logger实例,进而使用该实例来记录日志。
SLF4J在初始化时,会根据类路径下的日志框架实现,选择一个合适的SLF4JServiceProvider类(为了替换SLF4J的1.0.x到1.7.x中的静态绑定机制),并通过该类获取具体的日志工厂(ILoggerFactory),最终创建出Logger实例。
本文源码分析使用的SLF4J的版本为2.0.16,注意与1.7.x及之前版本的实现有较大不同,注意区分。
Logger和LoggerFactory
一个典型的SLF4J使用代码如下:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class HelloWorld {
private static final Logger logger = LoggerFactory.getLogger(HelloWorld.class); public static void main(String[] args) { logger.info("Hello, World!"); logger.debug("This is a debug message."); logger.error("An error occurred."); }
}
上面代码中使用了SLF4J的两个关键组件Logger接口和LoggerFactory工具类。
通常在项目中,只会使用一种日志实现框架,这里为了演示SLF4J的原理,我们引入多个日志实现。依赖如下:
<dependencies> <!--log4j 2 实现 slf4j2--> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j2-impl</artifactId> <version>2.24.2</version> </dependency> <!--reload4j 实现 slf4j2--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-reload4j</artifactId> <version>2.0.16</version> </dependency> <!--simple 实现 slf4j2--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.16</version> </dependency> <!--logback 实现 slf4j2--> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.5.12</version> </dependency>
</dependencies>
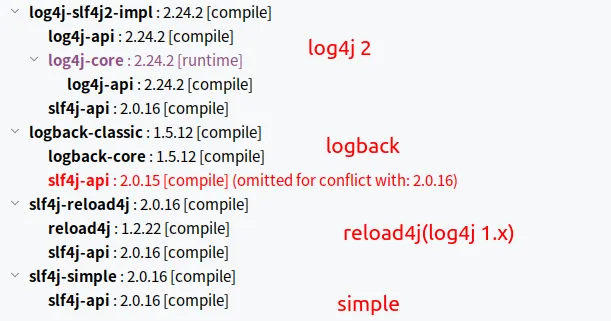
【图】项目依赖多个日志实现框架
关于日志门面和日志框架,参见:【java开发】一文理清 Java 日志框架的来龙去脉
上面的代码运行后,打印日志如下:
SLF4J(W): Class path contains multiple SLF4J providers.
SLF4J(W): Found provider [org.apache.logging.slf4j.SLF4JServiceProvider@238e0d81]
SLF4J(W): Found provider [org.slf4j.reload4j.Reload4jServiceProvider@31221be2]
SLF4J(W): Found provider [org.slf4j.simple.SimpleServiceProvider@377dca04]
SLF4J(W): Found provider [ch.qos.logback.classic.spi.LogbackServiceProvider@728938a9]
SLF4J(W): See https://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J(I): Actual provider is of type [org.apache.logging.slf4j.SLF4JServiceProvider@238e0d81]
10:23:45.599 [main] INFO org.learn.HelloWorld - Hello, World!
10:23:45.601 [main] ERROR org.learn.HelloWorld - An error occurred.
从运行日志可以看到,找到了多个SLF4J的实现框架,最终使用的是log4j 2的实现。
我们先看一下源码中Logger和LoggerFactory的描述。
Logger 接口
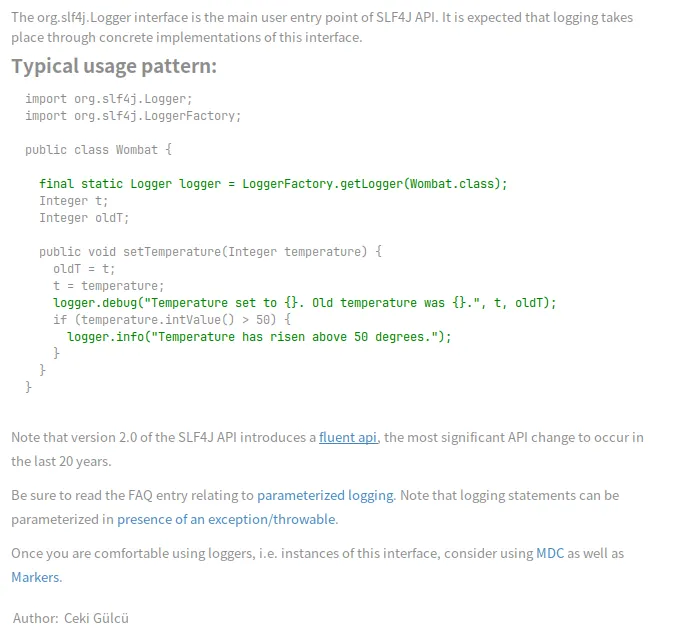
【图】Logger接口描述
org.slf4j.Logger接口是SLF4J API的主要入口点。最终日志记录将通过该接口的具体实现框架来完成。同时我们可以看到SLF4J的作者是Ceki Gülcü。
以下是关于 Logger 接口的一些关键点:
主要功能:提供了基本的日志记录方法,如 debug(), info(), warn(), error() 等,这些方法允许开发者在不同的日志级别上记录信息。
实现方式:具体的日志记录是由实现了 Logger 接口的类完成的。常见的实现包括 Logback、Log4j 和 java.util.logging(JUL)。
灵活性:通过配置文件,可以轻松地更改日志框架,而无需修改应用程序代码。
性能考虑:提供了 isDebugEnabled(), isInfoEnabled() 等方法,可以在调用日志记录方法之前检查是否启用了相应的日志级别,从而提高性能。
LoggerFactory 类
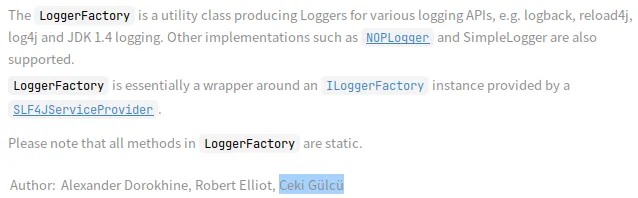
【图】LoggerFactory类描述
LoggerFactory是一个工具类,用于为各种日志API(例如logback、reload4j、log4j和JDK 1.4(JUL))生成Logger。也支持诸如NOPLogger和SimpleLogger等其他实现。
实际上,LoggerFactory是围绕由SLF4JServiceProvider提供的ILoggerFactory实例的一个封装。
请注意,LoggerFactory中的所有方法都是静态的。
LoggerFactory 是 SLF4J 提供的一个实用工具类,用于生成不同日志框架的 Logger 实例。以下是对 LoggerFactory 的详细说明:
主要功能:
生成 Logger 实例:通过静态方法 getLogger() 生成 Logger 实例。
支持多种日志框架:可以生成适用于 Logback、Log4j、JDK 1.4 日志等不同日志框架的 Logger 实例。
支持其他实现:还支持 NOPLogger 和 SimpleLogger 等其他日志实现。
工作原理:
LoggerFactory 实际上是一个围绕 ILoggerFactory 实例的包装器。
ILoggerFactory 实例由 SLF4JServiceProvider 提供,后者负责根据当前环境选择合适的日志框架实现。
静态方法:
所有方法都是静态的,这意味着你可以直接通过类名调用这些方法,而不需要创建 LoggerFactory 的实例。
常用方法:
getLogger(String name):根据指定的名称获取 Logger 实例。
getLogger(Class
getILoggerFactory():获取底层的 ILoggerFactory 实例。
注意事项:
静态方法:所有方法都是静态的,因此可以直接通过 LoggerFactory 类调用。
配置文件:具体的日志框架和配置可以通过配置文件(如 logback.xml 或 log4j.properties)进行设置。
依赖管理:确保项目中包含所需的日志框架依赖,例如 Logback 或 Log4j,以便 LoggerFactory 能够正确地初始化 Logger 实例。
关于不同日志实现框架的依赖,参见:【java开发】一文理清 Java 日志框架的来龙去脉
通过 LoggerFactory,开发者可以方便地在不同的日志框架之间切换,而无需修改应用程序代码,提高了代码的可维护性和灵活性。
这里提到一个关键接口SLF4JServiceProvider,我们看下它的描述。
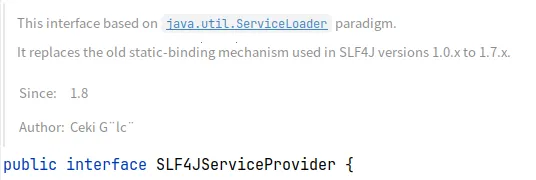
【图】SLF4JServiceProvider接口描述
这个接口基于java.util.ServiceLoader范式。
它取代了SLF4J 1.0.x到1.7.x版本中所使用的旧的静态绑定机制。这意味着,通过使用Java的服务加载器机制,SLF4J能够以一种更加灵活和动态的方式发现并加载日志实现,而不再依赖于编译时或部署时的固定配置。这种变化使得系统能够在运行时根据实际可用的日志框架来决定使用哪一个具体的Logger实现,从而提高了系统的灵活性和可扩展性。
源码分析
下面分析一下SLF4J获取Logger并打印日志的过程。主要包括三个步骤:
1、初始化:获取日志实现provider,创建日志工厂
2、获取Logger
3、使用Logger打印日志
1. 初始化LoggerFactory
初始化过程包括获取日志实现SLF4JServiceProvider,创建日志工厂。
入口是org.slf4j.LoggerFactory#getLogger(java.lang.Class<?>),源码如下:
public static Logger getLogger(Class<?> clazz) {Logger logger = getLogger(clazz.getName());if (DETECT_LOGGER_NAME_MISMATCH) {Class<?> autoComputedCallingClass = Util.getCallingClass();if (autoComputedCallingClass != null && nonMatchingClasses(clazz, autoComputedCallingClass)) {Reporter.warn(String.format("Detected logger name mismatch. Given name: \"%s\"; computed name: \"%s\".", logger.getName(),autoComputedCallingClass.getName()));Reporter.warn("See " + LOGGER_NAME_MISMATCH_URL + " for an explanation");}}return logger;}
这段代码的主要功能是获取一个与给定类名对应的日志记录器(Logger)。具体步骤如下:
1、获取日志记录器:调用 getLogger(clazz.getName()) 方法,传入类名字符串,获取一个 Logger 实例。
2、检测日志名称不匹配:如果系统属性 slf4j.detectLoggerNameMismatch 设置为 true,则进行以下检查:
获取调用类的自动计算类名 autoComputedCallingClass。
检查 autoComputedCallingClass 是否为 null,以及 clazz 和 autoComputedCallingClass 是否不匹配。
如果不匹配,记录警告信息,提示日志名称不匹配,并提供相关文档链接。
3、返回日志记录器:返回获取的 Logger 实例。
第1步的org.slf4j.LoggerFactory#getLogger(java.lang.String)源码如下:
public static Logger getLogger(String name) {ILoggerFactory iLoggerFactory = getILoggerFactory();return iLoggerFactory.getLogger(name);}public static ILoggerFactory getILoggerFactory() {return getProvider().getLoggerFactory();
}
通过org.slf4j.LoggerFactory#getProvider获取日志的实现。源码如下:
static volatile int INITIALIZATION_STATE = UNINITIALIZED;static SLF4JServiceProvider getProvider() {if (INITIALIZATION_STATE == UNINITIALIZED) {synchronized (LoggerFactory.class) {if (INITIALIZATION_STATE == UNINITIALIZED) {INITIALIZATION_STATE = ONGOING_INITIALIZATION;performInitialization();}}}switch (INITIALIZATION_STATE) {case SUCCESSFUL_INITIALIZATION:return PROVIDER;case NOP_FALLBACK_INITIALIZATION:return NOP_FALLBACK_SERVICE_PROVIDER;case FAILED_INITIALIZATION:throw new IllegalStateException(UNSUCCESSFUL_INIT_MSG);case ONGOING_INITIALIZATION:// support re-entrant behavior.// See also http://jira.qos.ch/browse/SLF4J-97return SUBST_PROVIDER;}throw new IllegalStateException("Unreachable code");}
getProvider 方法的主要功能是获取当前使用的 SLF4JServiceProvider 实例。具体步骤如下:
1、初始化检查:如果 INITIALIZATION_STATE 为 UNINITIALIZED,则进行同步初始化。
2、状态切换:根据 INITIALIZATION_STATE 的值,返回相应的 SLF4JServiceProvider 实例或抛出异常。
这个方法用到了单例模式的“双重检测机制(DCL)懒汉式”写法给INITIALIZATION_STATE赋值,几个关键点:
1、INITIALIZATION_STATE被volatile修饰防止指令重排序。
2、锁的内外做了两次INITIALIZATION_STATE == UNINITIALIZED判断,防止多线程重复赋值。
关于单例模式,参见:设计模式--单例模式
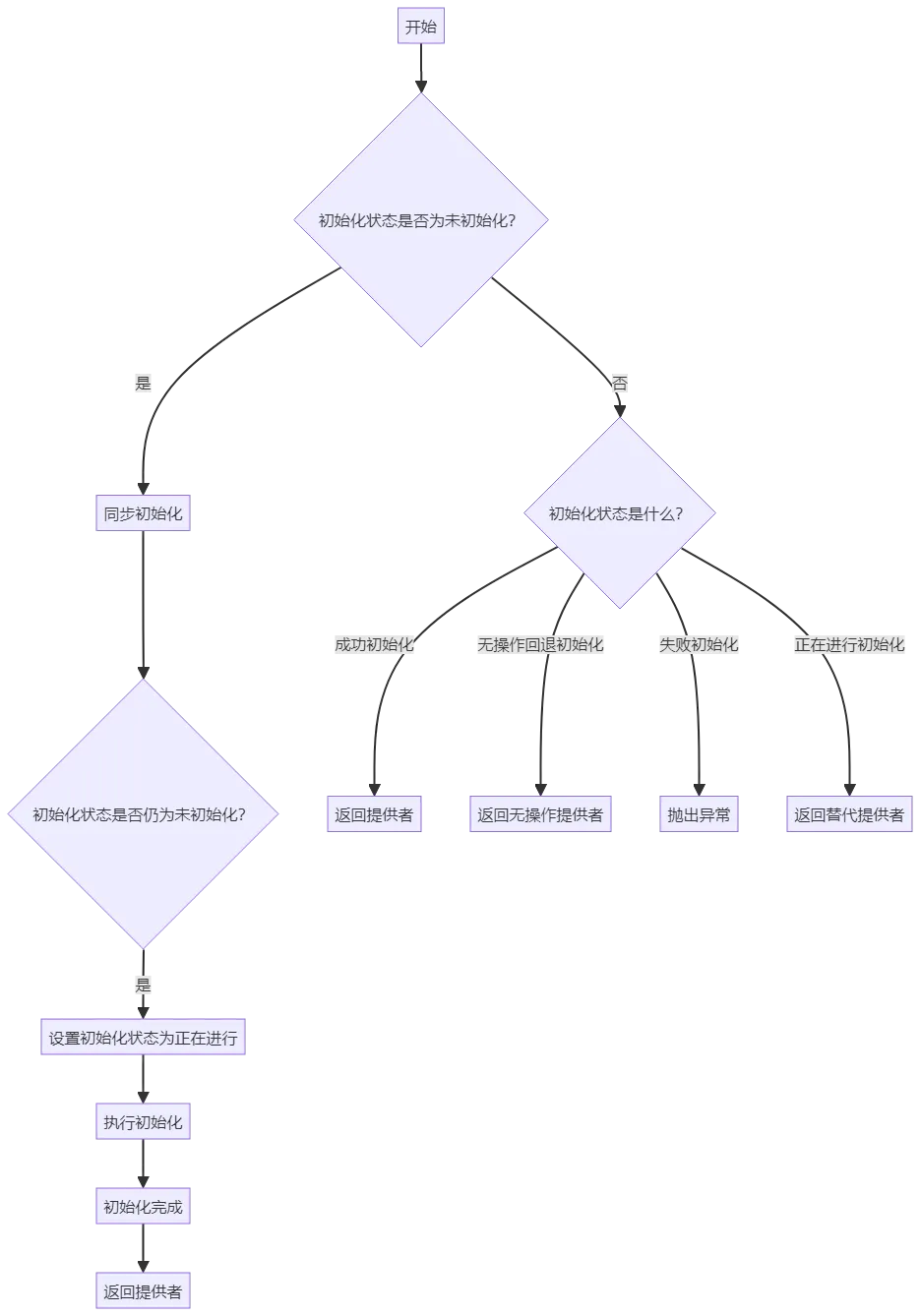
【图】getProvider代码流程图
performInitialization源码如下:
private final static void performInitialization() {bind();if (INITIALIZATION_STATE == SUCCESSFUL_INITIALIZATION) {versionSanityCheck();}
}
重点是bind方法,源码如下:
private final static void bind() {try {List<SLF4JServiceProvider> providersList = findServiceProviders();reportMultipleBindingAmbiguity(providersList);if (providersList != null && !providersList.isEmpty()) {PROVIDER = providersList.get(0);// SLF4JServiceProvider.initialize() is intended to be called here and nowhere else.PROVIDER.initialize();INITIALIZATION_STATE = SUCCESSFUL_INITIALIZATION;reportActualBinding(providersList);} else {INITIALIZATION_STATE = NOP_FALLBACK_INITIALIZATION;Reporter.warn("No SLF4J providers were found.");Reporter.warn("Defaulting to no-operation (NOP) logger implementation");Reporter.warn("See " + NO_PROVIDERS_URL + " for further details.");Set<URL> staticLoggerBinderPathSet = findPossibleStaticLoggerBinderPathSet();reportIgnoredStaticLoggerBinders(staticLoggerBinderPathSet);}postBindCleanUp();} catch (Exception e) {failedBinding(e);throw new IllegalStateException("Unexpected initialization failure", e);}
}
bind() 方法的主要功能是初始化 SLF4J 的日志提供者。具体步骤如下:
1、查找服务提供者:调用 findServiceProviders() 方法获取所有可用的 SLF4JServiceProvider 列表。
2、报告多重绑定问题:调用 reportMultipleBindingAmbiguity(providersList) 方法检查是否存在多个服务提供者,并在存在时报告警告。
3、选择并初始化提供者:
如果找到至少一个服务提供者,则选择第一个提供者并调用其 initialize() 方法进行初始化。
将初始化状态设置为 SUCCESSFUL_INITIALIZATION,并报告实际绑定的服务提供者。
4、处理未找到提供者的情况:
如果没有找到任何服务提供者,则将初始化状态设置为 NOP_FALLBACK_INITIALIZATION,并报告警告信息,提示默认使用无操作(NOP)日志实现。
查找可能的静态日志绑定路径并报告被忽略的绑定。
5、清理工作:调用 postBindCleanUp() 方法进行初始化后的清理工作。
6、异常处理:捕获并处理初始化过程中可能出现的异常,记录错误信息并将初始化状态设置为 FAILED_INITIALIZATION。
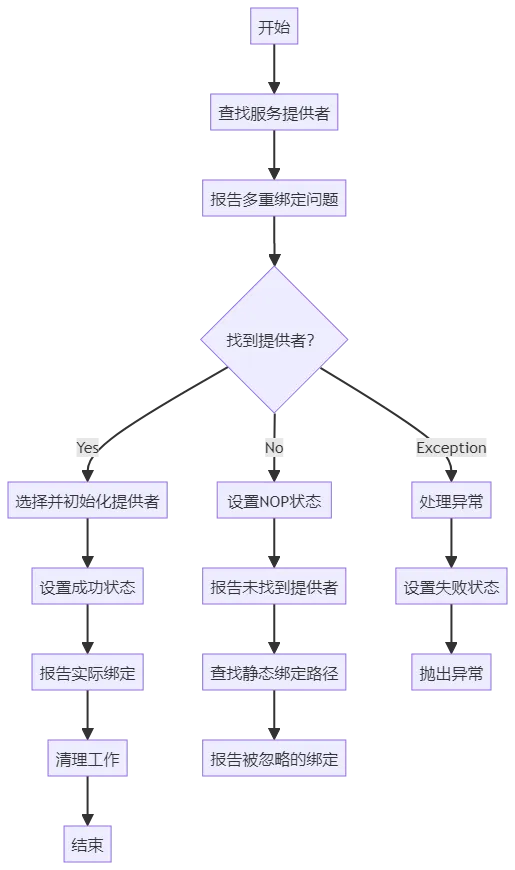
【图】bind()方法流程图
下图可看到,获取到了4个日志服务提供者:log4j 2、reload4j (log4j 1.x)、simple、logback。会选择第一个,即log4j 2作为服务提供者。
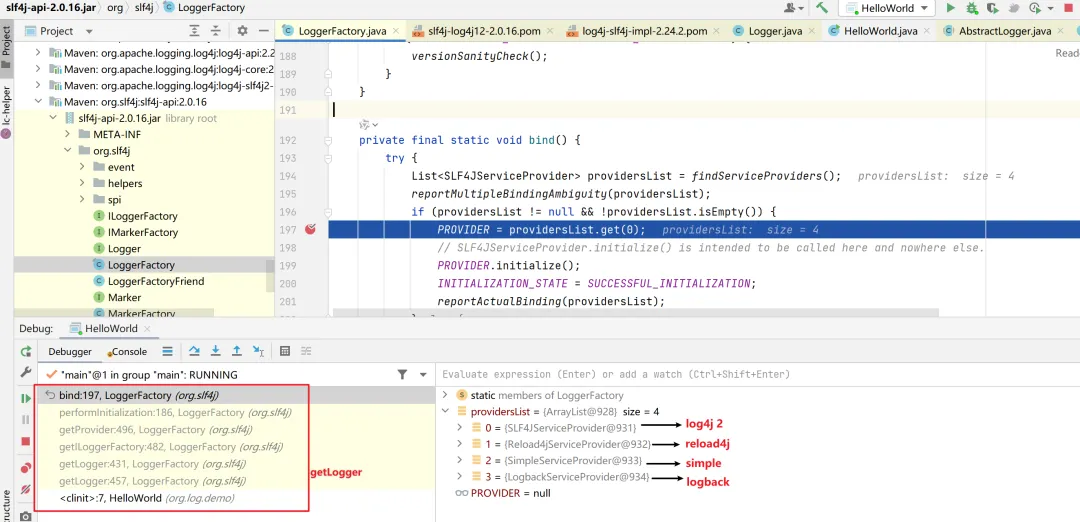
【图】bind方法调用栈以及获取到的日志服务提供者
如果有多个服务提供者,在org.slf4j.LoggerFactory#reportMultipleBindingAmbiguity方法会打印警告信息:
private static void reportMultipleBindingAmbiguity(List<SLF4JServiceProvider> providerList) {if (isAmbiguousProviderList(providerList)) {Reporter.warn("Class path contains multiple SLF4J providers.");for (SLF4JServiceProvider provider : providerList) {Reporter.warn("Found provider [" + provider + "]");}Reporter.warn("See " + MULTIPLE_BINDINGS_URL + " for an explanation.");}
}
打印日志如下:
SLF4J(W): Class path contains multiple SLF4J providers.
SLF4J(W): Found provider [org.apache.logging.slf4j.SLF4JServiceProvider@3fa77460]
SLF4J(W): Found provider [org.slf4j.reload4j.Reload4jServiceProvider@619a5dff]
SLF4J(W): Found provider [org.slf4j.simple.SimpleServiceProvider@1ed6993a]
SLF4J(W): Found provider [ch.qos.logback.classic.spi.LogbackServiceProvider@7e32c033]
SLF4J(W): See https://www.slf4j.org/codes.html#multiple_bindings for an explanation.
之后会调用log4j 2提供者的初始化方法org.apache.logging.slf4j.SLF4JServiceProvider#initialize,该方法实现了SLF4J的接口org.slf4j.spi.SLF4JServiceProvider#initialize。源码如下:
public void initialize() {markerFactory = new Log4jMarkerFactory();loggerFactory = new Log4jLoggerFactory(markerFactory);mdcAdapter = new Log4jMDCAdapter();
}
在该方法中创建了Log4jLoggerFactory实例。
接着回到bind的org.slf4j.LoggerFactory#reportActualBinding方法,会打印信息到控制台,输出实际选择的服务提供者。
private static void reportActualBinding(List<SLF4JServiceProvider> providerList) {// impossible since a provider has been foundif (providerList.isEmpty()) {throw new IllegalStateException("No providers were found which is impossible after successful initialization.");}if (isAmbiguousProviderList(providerList)) {Reporter.info("Actual provider is of type [" + providerList.get(0) + "]");} else {SLF4JServiceProvider provider = providerList.get(0);Reporter.debug(CONNECTED_WITH_MSG + provider.getClass().getName() + "]");}
}
输出日志(选择了log4j 2作为服务提供者):
SLF4J(I): Actual provider is of type [org.apache.logging.slf4j.SLF4JServiceProvider@3fa77460]
这时,初始化就完成了,成功会将初始化状态INITIALIZATION_STATE设置为SUCCESSFUL_INITIALIZATION。
然后返回到方法org.slf4j.LoggerFactory#getProvider,判断状态为SUCCESSFUL_INITIALIZATION后返回提供者。
返回到org.slf4j.LoggerFactory#getILoggerFactory方法,调用获取到的提供者的getLoggerFactory方法,返回ILoggerFactory。从上面分析,我们知道选择的是log4j 2,因此会调用它的org.apache.logging.slf4j.SLF4JServiceProvider#getLoggerFactory方法返回ILoggerFactory。该方法重写了SLF4J的org.slf4j.spi.SLF4JServiceProvider#getLoggerFactory。
public ILoggerFactory getLoggerFactory() {return loggerFactory;
}
返回的org.slf4j.ILoggerFactory实现类是Log4jLoggerFactory。
这样在org.slf4j.LoggerFactory#getLogger(String)方法中就获取到了实际的日志工厂类。
2. 获取Logger
接着iLoggerFactory.getLogger(name)返回org.slf4j.Logger的实现类Log4jLogger。
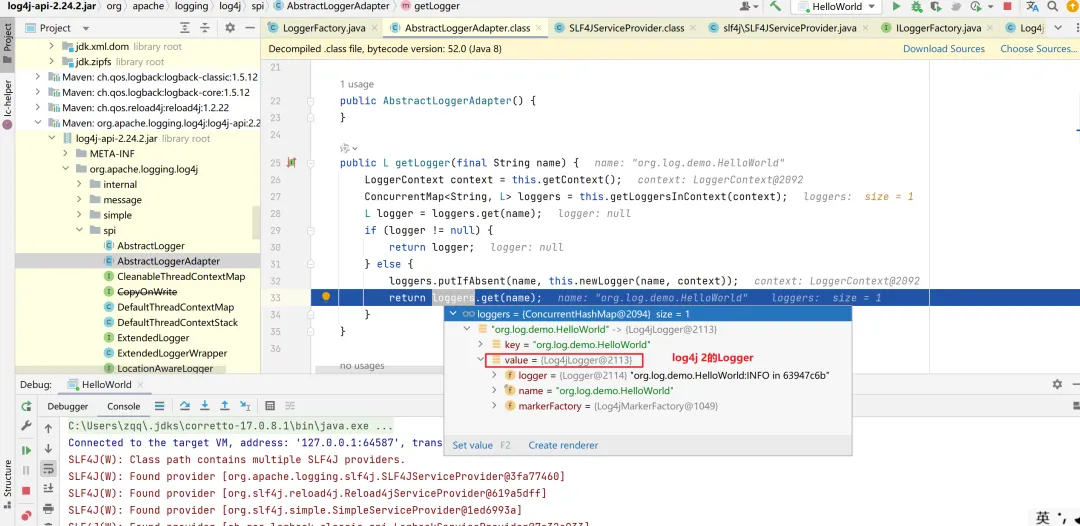
【图】Logger的实现类Log4jLogger
在测试代码中可以看到,已经获取到了Logger的实现类Log4jLogger。
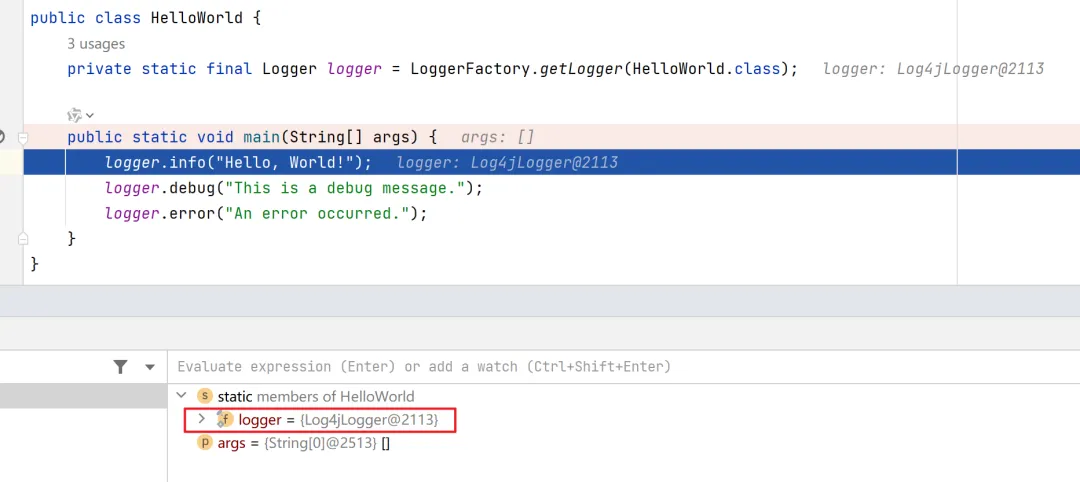
ILoggerFactory接口及其getLogger(String name)方法体现了工厂模式的设计模式。
关于工厂模式,参见:[设计模式--工厂模式探索:简单工厂、工厂方法、抽象工厂](https://mp.weixin.qq.com/s?__biz=MzkxNTczNjc4Mg==&mid=2247483917&idx=1&sn=b7ed60b8a1f1c94f67712327d63c09e7&scene=21#wechat_redirect)
3. 打印日志
根据上面的分析,此时已经获取到了Logger,即Log4jLogger,接着就是调用它的info()、debug()、error()方法打印日志,这里以info()方法为例进行分析。
org.slf4j.Logger#info(String)实现方法是org.apache.logging.slf4j.Log4jLogger#info(String)。源码如下:
public void info(final String format) {logger.logIfEnabled(FQCN, Level.INFO, null, format);
}
接着看下org.apache.logging.log4j.spi.AbstractLogger#logIfEnabled(java.lang.String, org.apache.logging.log4j.Level, org.apache.logging.log4j.Marker, java.lang.String)方法,源码如下:
public void logIfEnabled(final String fqcn, final Level level, final Marker marker, final String message) {if (this.isEnabled(level, marker, message)) {this.logMessage(fqcn, level, marker, message);}
}
最后是调用org.apache.logging.log4j.core.appender.OutputStreamManager#flush方法输出到目的终端(控制台或者文件)。
public synchronized void flush() {flushBuffer(byteBuffer);flushDestination();
}
logger.info的完整调用栈如下图所示:
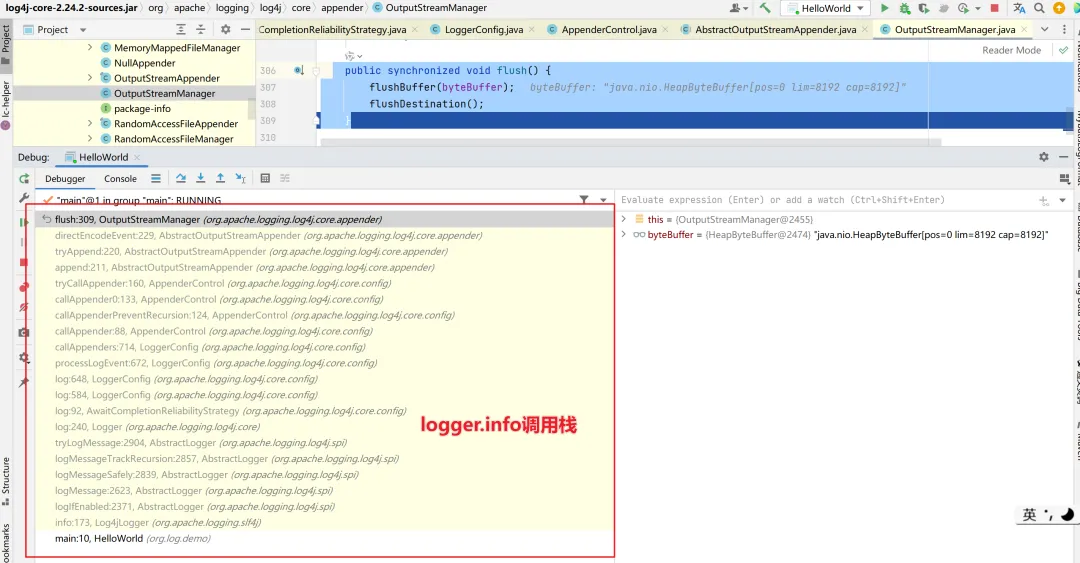
【图】log4j 2的logger.info方法调用栈
至此SLF4J使用log4j 2作为日志实现输出日志的源码分析就结束了。对于其他日志实现框架,如logback等,可参考上面分析进行源码阅读。原理类似。
更多内容,请关注公众号程序员Ink
个人观点,仅供参考