VGGNet
2024年5月10日更新
在此教程中,我们将对VGGNet模型及其原理进行一个简单的介绍,并实VGGNet模型的训练和推理,目前支持数据集有:MNIST、fashionMNIST、CIFAR10等,并给用户提供一个详细的帮助文档。
目录
基本介绍
- VGGNett描述
- 创新点
- 网络结构
- VGGNet的特点
VGGNet实现
- 总体概述
- 项目地址
- 项目结构
- 训练及推理步骤
- 实例
基本介绍
VGGNet描述
VGG网络的特点是利用小的尺寸核代替大的卷积核,然后把网络做深。
VggNet一共有六种不同的网络结构,但是每种结构都有含有5组卷积,每组卷积都使用 3 * 3 的卷积核,每组卷积后进行一个 2 * 2 最大池化,接下来是三个全连接层.在训练高级别的网络时,可以先训练低级别的网络,用前者获得的权重初始化高级别的网络,可以加速网络的收敛。它得出结论:卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用。
VGGNet模型探索了卷积神经网络的深度和其性能之间的关系,通过反复的堆叠 3 * 3 的小型卷积核和 2 * 2 的最大池化层,成功的构建了16~19层深的卷积神经网络。直到目前,VGGNet依然被用来提取图像的特征。
创新点
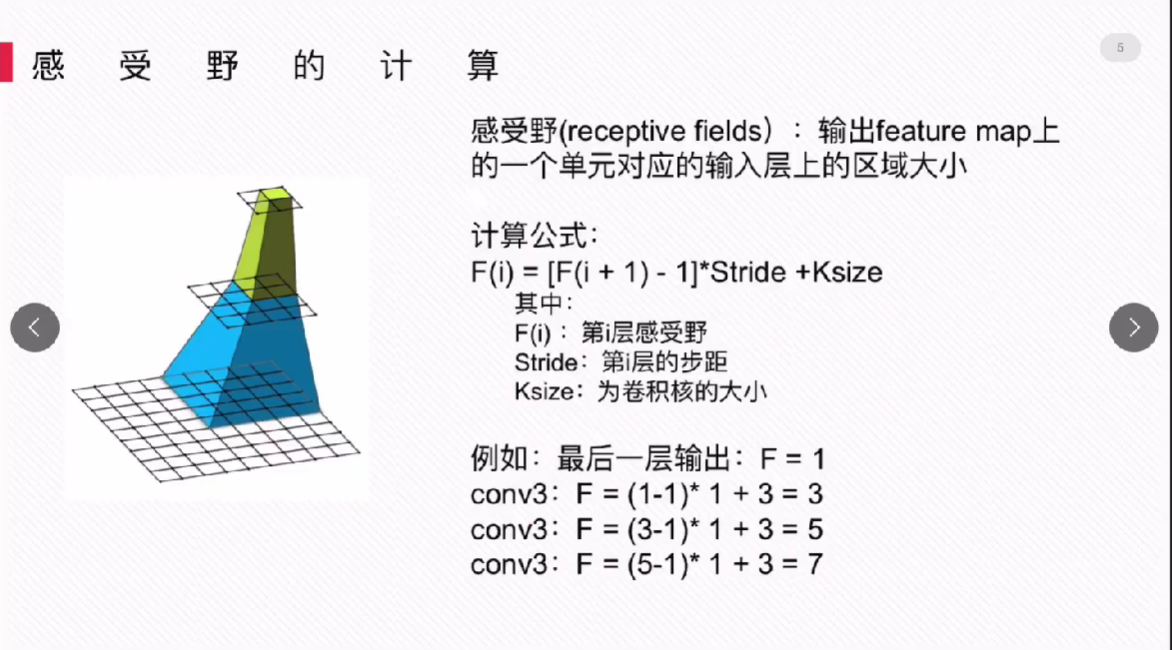
VGGNet全部使用 3 * 3 的卷积核和 2 * 2 的池化核,通过不断加深网络结构来提升性能。网络层数的增长并不会带来参数量上的爆炸,因为参数量主要集中在最后三个全连接层中。同时,两个 3 * 3 卷积层的串联相当于1个 5 * 5 的卷积层,3个 3 * 3 的卷积层串联相当于1个 7 * 7 的卷积层,即3个 3 * 3 卷积层的感受野大小相当于1个 7 * 7 的卷积层。但是3个 3 * 3 的卷积层参数量只有 7 * 7 的一半左右,同时前者可以有3个非线性操作,而后者只有1个非线性操作,经过了更多次非线性变化使得前者对于特征的学习能力更强。如下图所示,它表示两个串联 3 * 3的卷积层功能类似于一个 5 * 5 的卷积层。
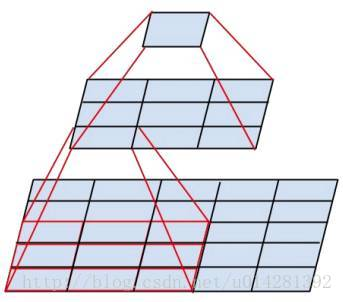
使用1*1的卷积层来增加线性变换,输出的通道数量上并没有发生改变。
1 * 1 卷积层的其他用法:1 * 1的卷积层常被用来提炼特征,即多通道的特征组合在一起,凝练成较大通道或者较小通道的输出,而每张图片的大小不变。有时 1 * 1 的卷积神经网络还可以用来替代全连接层。总结使用多个 3 * 3 卷积堆叠的作用有两个:一是在不影响感受野的前提下减少了参数;二是增加了网络的非线性。
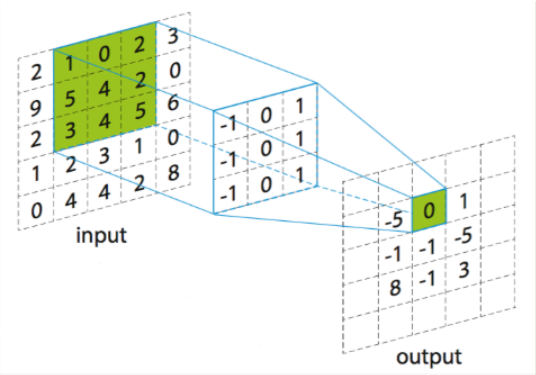
VGGNet在训练的时候先训级别A的简单网络,再复用A网络的权重来初始化后面的几个复杂模型,这样收敛速度更快。VGGNet作者总结出LRN层作用不大,越深的网络效果越好, 1 * 1的卷积也是很有效的,但是没有 3 * 3 的卷积效果好,因为 3 * 3 的网络可以学习到更大的空间特征,并且既可以保证感受视野,有能减少卷积层的参数。如下图所示:
网络结构
VGGNet的网络结构如下图所示。VGGNet包含很多级别的网络,深度从11层到19层不等,比较常用的是VGGNet-16和VGGNet-19。VGGNet把网络分成了5段,每段都把多个3*3的卷积网络串联在一起,每段卷积后面接一个最大池化层,最后面是3个全连接层和一个softmax层。
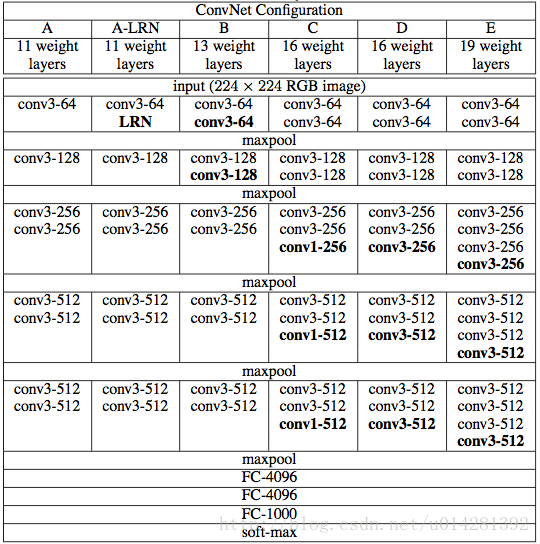
上图中的D和E即为常用的VGG-16和VGG-19,前者拥有13个核大小均为 3 * 3 的卷积层、5个最大池化层和3个全连接层,后者拥有16个核大小均为 3 * 3 的卷积层、5个最大池化层和3个全连接层。本文主要针对VGG16进行解读,可以看出VGG19只是多了3个卷积层而已,其它的和VGG-16没啥区别。
表中的卷积层(conv3-kernels,其中kernels代表卷积核的个数)全部都是大小为 3 * 3、步距为1、padding为1的卷积操作(经过卷积后不会改变特征矩阵的高和宽,但是深度改变,深度的大小等于卷积核的数量)。最大池化下采样层全部都是池化核大小为2、步距为2的池化操作(每次通过最大池化下采样后特征矩阵的高和宽都会缩减为原来的一半,但是深度不变)。VGG-16的结构图如下图:
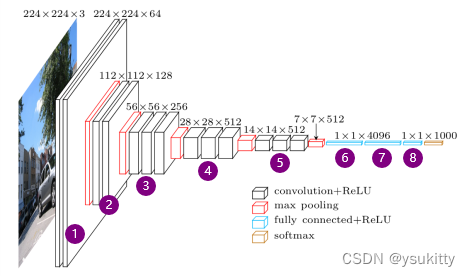
由上图所示,VGG-16架构:13个卷积层+3个全连接层(共16层,不计入池化层和Softmax),前5段卷积网络(标号1-5),主要用于提取特征;最后一段是三个全连接网络(标号6-8),主要用于分类。注意最后一个全连接层是没有激活函数的,因为它最后要使用Softmax函数对结果进行概率化。
VGGNet的特点
结构简洁
VGGNet的结构十分简洁,由5个卷积层、3个全连接层和1个softmax层构成,层与层之间使用最大池化连接,隐藏层之间使用的激活函数全都是ReLU,并且网络的参数也是整齐划一的。
使用小卷积核
VGGNet使用含有多个小型的 3 * 3 卷积核的卷积层来代替AlexNet中的卷积核较大的卷积层,采用多个小型卷积核,既能减少参数的数量,又能增强网络的非线性映射从而提升网络的表达能力。
为什么可以增加网络的非线性?我们知道激活函数的作用就是给神经网络增加非线性因素,使其可以拟合任意的函数,每个卷积操作后都会通过ReLU激活,ReLU函数就是一个非线性函数。
使用小滤波器
与AlexNet相比,VGGNet在池化层全部采用的是 2 * 2 的小滤波器,stride为2
通道数较多
VGGNet的第一层有64个通道,后面的每一层都对通道进行了翻倍,最多达到了512个通道(64-128-256-512-512)。由于每个通道都代表着一个feature map,这样就使更多的信息可以被提取出来。
图像预处理
训练采用多尺度训练(Multi-scale),将原始图像缩放到不同尺寸S,然后再随机裁切 224 * 224 的图片,并且对图片进行水平翻转和随机RGB色差调整,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。
初始对原始图片进行裁剪时,原始图片的最小边不宜过小,否则裁剪到 224 * 224 的时候,就相当于几乎覆盖了整个图片,这样对原始图片进行不同的随机裁剪得到的图片就基本上没差别,就失去了增加数据集的意义。但同时也不宜过大,否则裁剪到的图片只含有目标的一小部分,也不是很好。
针对上述裁剪的问题,提出的训练图片预处理过程:
1.训练图片归一化,图像等轴重调(最短边为S)
等轴重调剪裁时的两种解决办法:
方法一:固定最小边的尺寸为256
方法二:随机从[256,512]的确定范围内进行抽样,这样原始图片尺寸不一,有利于训练,这个方法叫做尺度抖动,有利于训练集增强。 训练时运用大量的裁剪图片有利于提升识别精确率。
2.随机剪裁(每SGD一次)
3.随机水平翻转
4.RGB颜色偏移
将全连接层转换为卷积层
这个特征是体现在VGGNet的测试阶段。在进行网络测试时,将训练阶段的3个全连接层替换为3个卷积层,使测试得到的网络没有全连接的限制,能够接收任意宽和高的输入。如果后面3个层都是全连接层,那么在测试阶段就只能将测试的图像全部缩放到固定尺寸,这样就不便于多尺度测试工作的开展。
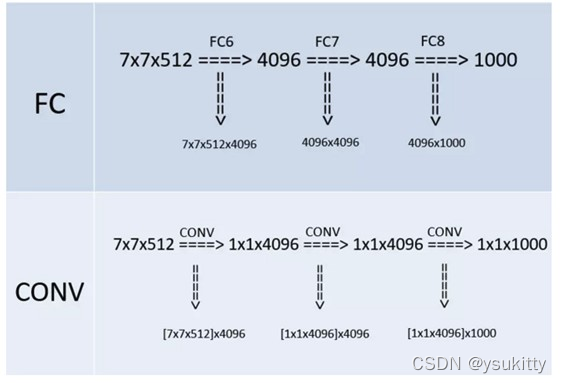
为什么这样替换之后就可以处理任意尺寸的输入图像了呢?因为 1 * 1 卷积一个很重要的作用就是调整通道数。如果下一层输入的特征图需要控制通道数为N,那么设置N个1×1卷积核就可以完成通道数的调整。比如最后需要1000个神经元用于分出1000个类别,那就在最后一层的前面使用1000个 1 * 1 的卷积核,这样的到的结果就是(1, 1, 1000)正好可以匹配。
VGGNet实现
总体概述
本项目旨在实现VGGNet模型,并且支持多种数据集,目前该模型可以支持单通道的数据集,如:MNIST、FashionMNIST等数据集,也可以支持多通道的数据集,如:CIFAR10、SVHN等数据集。模型最终将数据集分类为10种类别,可以根据需要增加分类数量。训练轮次默认为4轮,同样可以根据需要增加训练轮次。单通道数据集训练4~5轮就可以达到较高的精确度,而对于多通道数据,建议训练轮次在10轮以上,精确度才较为理想,可以达到90%以上。
项目地址
- 模型仓库:MindSpore/hepucuncao/VGGNet
项目结构
项目的目录分为两个部分:学习笔记README文档,以及ResNet模型的模型训练和推理代码放在train文件夹下。
├── train # 相关代码目录│ ├── train.py # VGGNet模型训练代码│ └── test.py # LeNet5模型推理代码└── README.md
训练及推理步骤
- 1.首先运行train.py初始化VGGNet网络的各参数
- 2.同时train.py会接着进行模型训练,要加载的训练数据集和测试训练集可以自己选择,本项目可以使用的数据集来源于torchvision的datasets库。相关代码如下:
#下载数据集
data_train = datasets.数据集名称(root="下载路径", transform=transform, train=True, download=True)
data_test = datasets.数据集名称(root="下载路径", transform=transform, train=False, download=True)# 加载数据集
data_loader_train = DataLoader(dataset=data_train, batch_size=batch_size, shuffle=True)
data_loader_test = DataLoader(dataset=data_test, batch_size=batch_size, shuffle=True)只需把数据集名称更换成你要使用的数据集(datasets中的数据集),并修改下载数据集的位置(默认在根目录下,如果路径不存在会自动创建)即可,如果已经提前下载好了则不会下载,否则会自动下载数据集。注意:程序要对数据进行变换,先对图像的尺寸进行修改为224*224,然后再转换成张量;如果是多通道数据集,要先将图像数据转换为灰度图像,其他步骤和单通道数据集相同。同时,程序会将每一个训练轮次的训练过程中的损失值打印出来,每隔51个batch打印一次,损失值越接近0,则说明训练越成功。同时,每一轮训练结束后程序会打印出本轮测试的平均损失值和平均精度。特别地,该程序在训练完毕后会打印出训练总耗时,同时展示出训练损失值、训练精度和测试精度随着训练轮次增多而变化的曲线,在训练完毕后显示在屏幕上。
- 3.由于train.py代码会将精确度最高的模型权重保存下来,以便推理的时候直接使用最好的模型,因此运行train.py之前,需要设置好保存的路径,相关代码如下:
torch.save(net.state_dict(), '保存路径')默认保存路径为根目录,可以根据需要自己修改路径,如果该文件路径不存在,程序会自动创建。- 4.保存完毕后,我们可以运行test.py代码,同样需要加载数据集(和训练过程的数据相同),步骤同2。同时,我们应将保存的最好模型权重文件加载进来,相关代码如下:
model.load_state_dict(torch.load("文件路径"))文件路径为最好权重模型的路径,注意这里要写绝对路径,并且windows系统要求路径中的斜杠应为反斜杠。另外,程序中创建了一个classes列表来获取分类结果,分类数量由列表中数据的数量来决定,可以根据需要来增减,相关代码如下:
classes=["0","1",..."n-1",
]要分成n个类别,就写0~n-1个数据项。- 5.最后是推理步骤,程序会选取测试数据集的前n张图片进行推理,并打印出每张图片的预测类别和实际类别,若这两个数据相同则说明推理成功。同时,程序会将选取的图片显示在屏幕上,相关代码如下:
for i in range(n): #取前n张图片X,y=test_dataset[i][0],test_dataset[i][1]show(X).show()#把张量扩展为四维X=Variable(torch.unsqueeze(X, dim=0).float(),requires_grad=False).to(device)model.eval() # 设置模型为评估模式with torch.no_grad():pred = model(X)predicted,actual=classes[torch.argmax(pred[0])],classes[y]print(f'predicted:"{predicted}",actual:"{actual}"')推理图片的数量即n取多少可以自己修改,但是注意要把显示出来的图片手动关掉,程序才会打印出这张图片的预测类别和实际类别。实例
这里我们以最经典的MNIST数据集为例:
运行train.py之前,要加载好要训练的数据集,如下图所示:
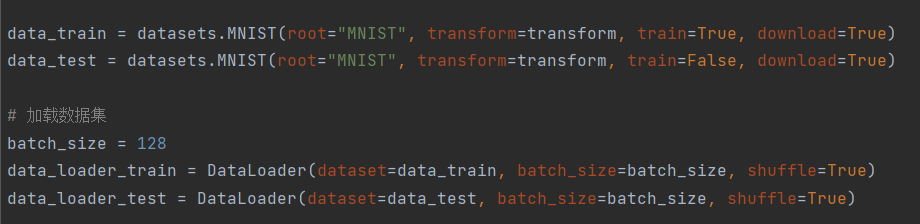
以及训练好的最好模型权重best_model.pth的保存路径:

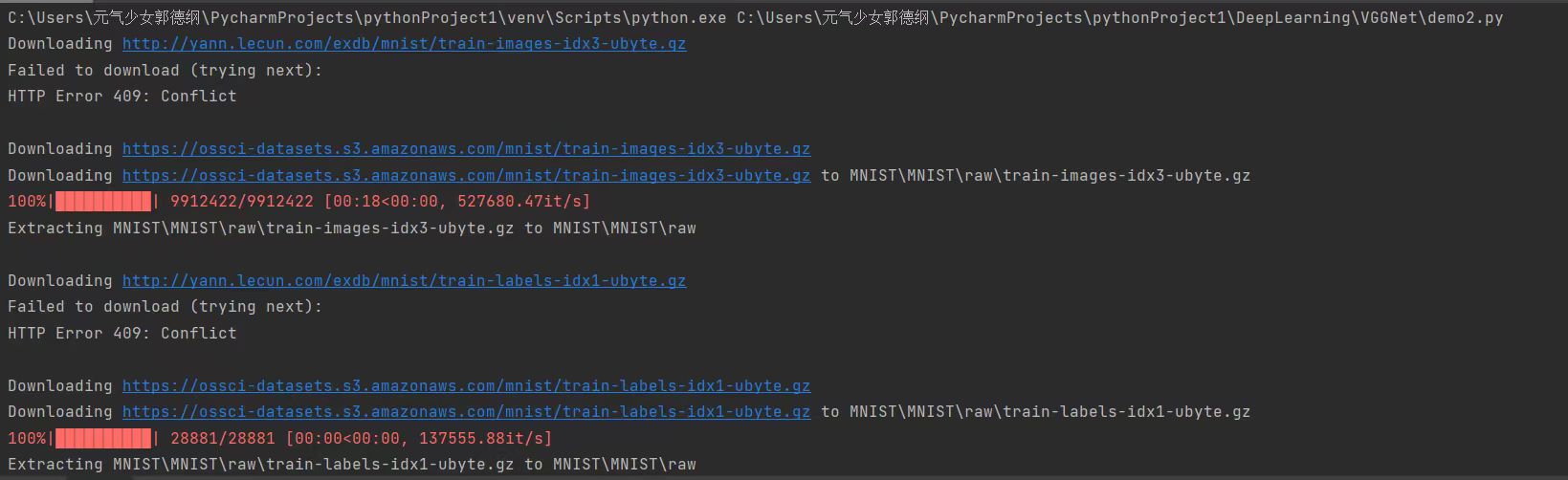
这里我们设置训练轮次为4,由于没有提前下载好数据集,所以程序会自动下载在/data目录下,运行结果如下图所示:
最好的模型权重保存在设置好的路径中:

从下图最后一轮的损失值和精确度可以看出,训练的成果已经是非常准确的了,并且程序会打印出训练的总耗时,VGGNet模型由于网络模型计算步骤相较之前的卷积模型更复杂,所以在cpu上训练的时间会比较长,对cpu的占用也比较大。
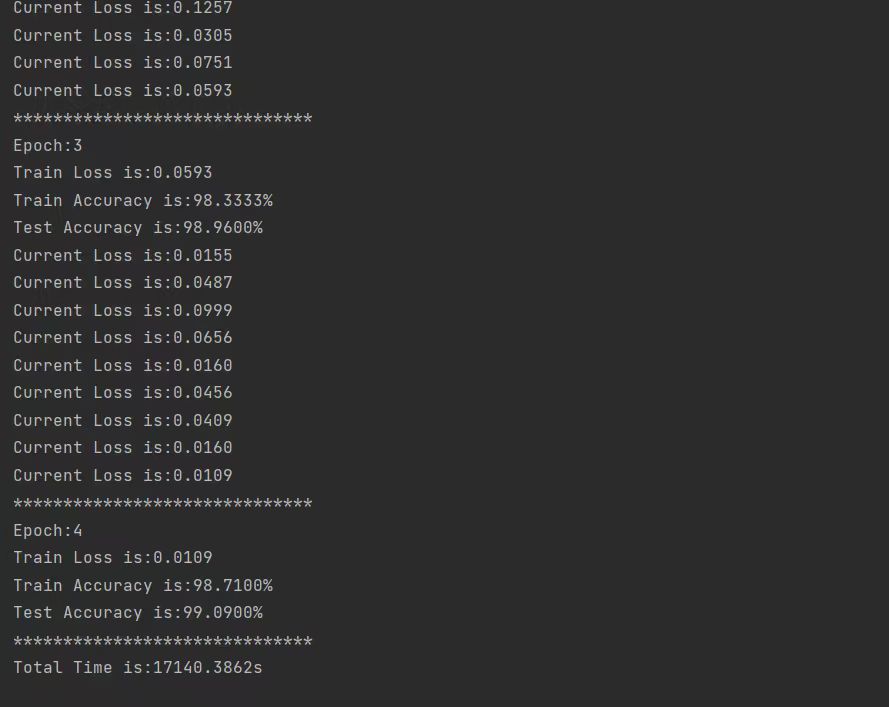
特别地,程序会弹出一个图像,展示了训练损失值、训练精度和测试精度随着训练轮次增多而变化的曲线。由图可以看出训练过程中的损失值是存在波动的,但是训练和测试的精度一直呈上升的趋势,且在第二轮训练过后精确值就很接近于100%了。
最后我们运行test.py程序,首先要把train.py运行后保存好的best_model.pth文件加载进来,设置的参数如下图所示:

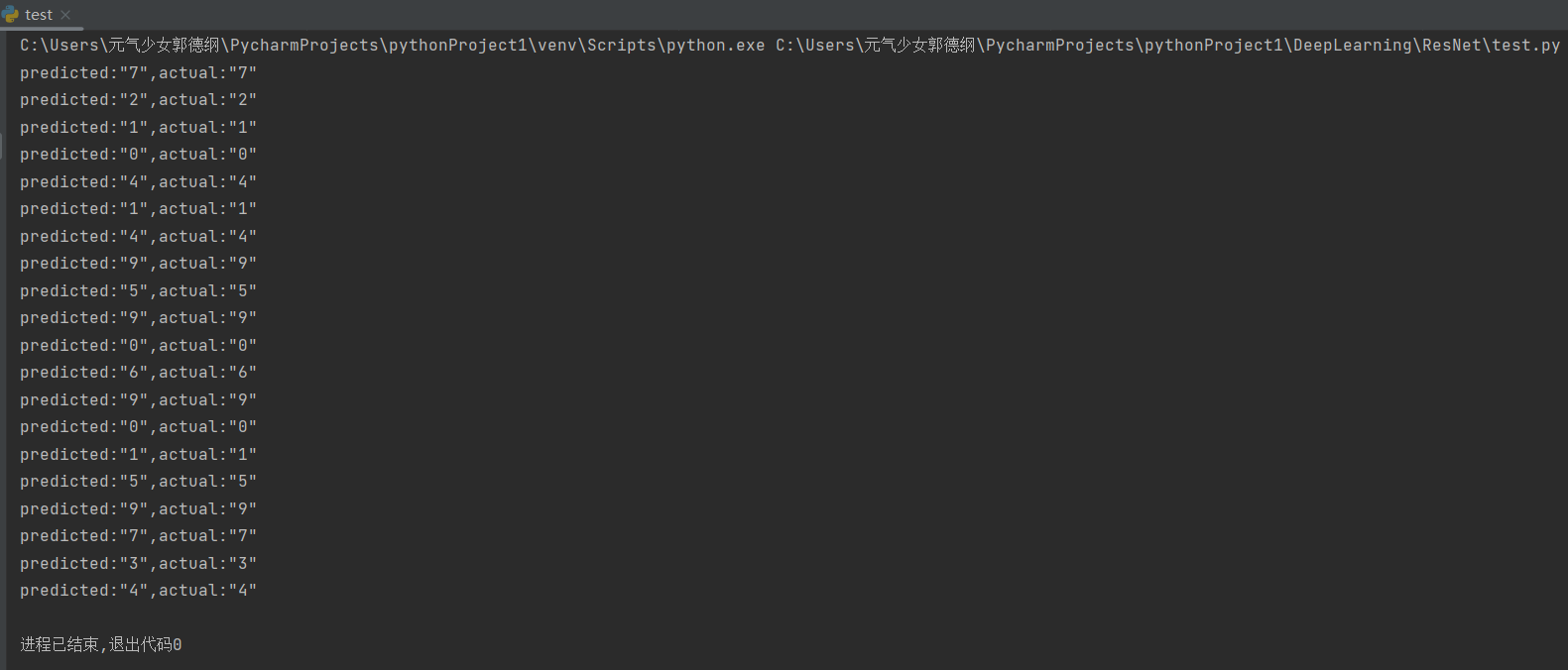
这里我们设置推理测试数据集中的前20张图片,每推理一张图片,都会弹出来显示在屏幕上,要手动把图片关闭才能打印出预测值和实际值:
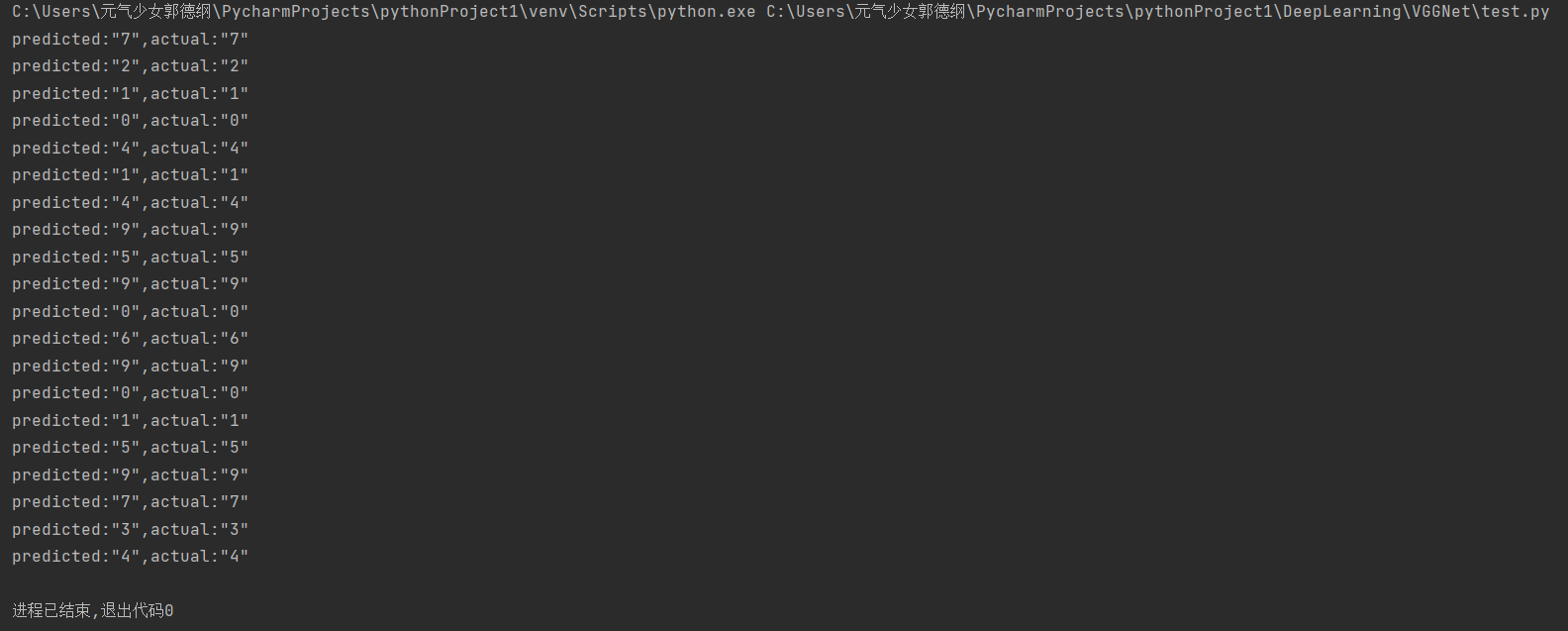
由下图最终的运行结果我们可以看出,推理的结果是较为准确的,预测值和真实值都是相匹配的,大家可以增加推理图片的数量以测试模型的准确性。
其他数据集的训练和推理步骤和MNIST数据集大同小异,唯一不同的是多通道数据集的数据变换操作,需要先转换为灰度图像。


![[QT] MAC使用Qt Creator运行程序如何仅运行一个进程?](https://images.cnblogs.com/cnblogs_com/RioTian/2326543/o_241212043953_image-20241212123730665.png)