import pandas as pd # 读取原始表 简化为仅求亏损最大的 # 路径需要双斜杠 data = pd.read_excel('D:\\work\\2\\配料统计表.xlsx',sheet_name='Sheet1') # 对数据做处理 #第一步 找到亏损类和涨出类 如果金额大于0 是亏损;否则是涨出 data_loss= data[data['差异金额']>0] #第二步 根据品类再次分组 根据差异金额做分组groupby # 找到每个品类中亏损最大的 调用max方法需要.max() 小括号不能丢 groupbyed_data_loss = data_loss.groupby('品类名称').max() # 将新数据写入新的表 groupbyed_data_loss.to_excel('D:\\work\\2\\配料统计表max1.xlsx',sheet_name='Sheet1')
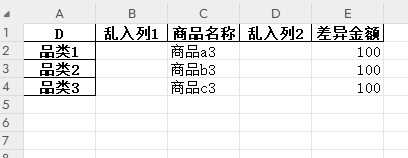
最初的表
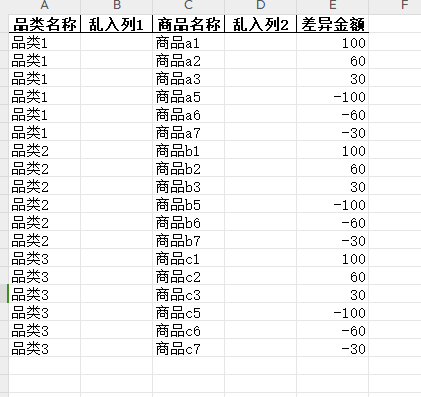
处理后将结果写入的表