雪花算法适用于高并发、分布式系统中生成唯一标识符。通过合理的位数设计,确保了ID的唯一性和有序性,非常适合需要快速生成唯一ID的场景。
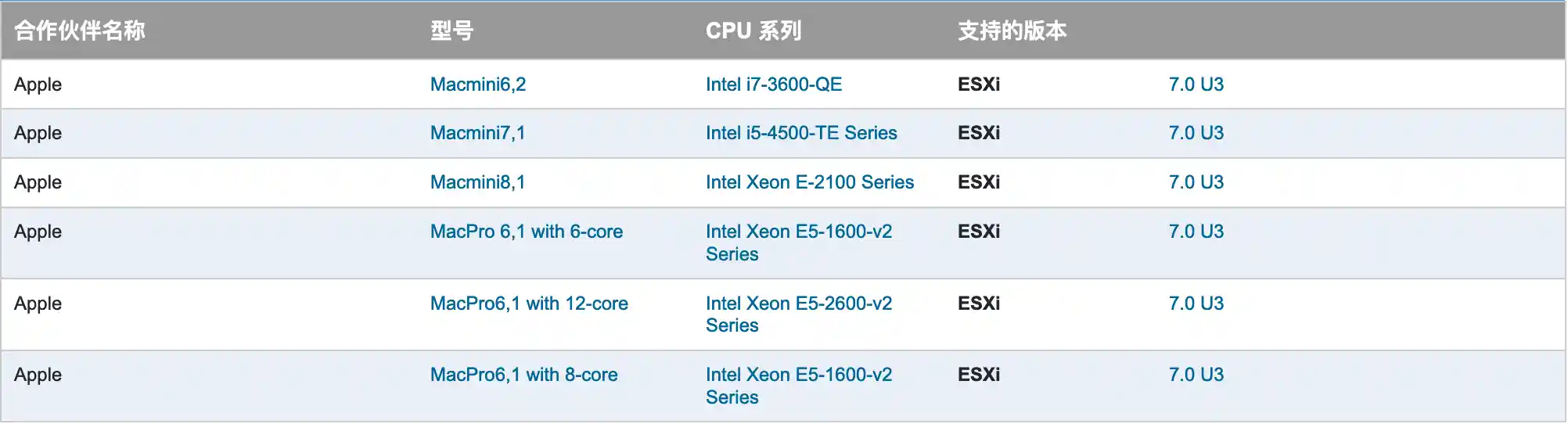
雪花算法是一种分布式唯一ID生成算法,由Twitter开发。它生成的ID是64位的整数,具有时间排序的特性。其结构如下:
```
| 1 bit | 41 bits | 10 bits | 12 bits |
|-------|------------------|------------------|------------------|
| sign | timestamp | datacenter id | worker id | sequence |
```
- **sign(1 bit)**:始终为0,因为雪花算法不需要负数。
- **timestamp(41 bits)**:自定义纪元(如2021年1月1日)以来的毫秒数,最多可以支持69年的时间。
- **datacenter id(10 bits)**:数据中心 ID,最多支持1024个数据中心。
- **worker id(10 bits)**:工作机器 ID,最多支持1024个工作节点。
- **sequence(12 bits)**:在同一毫秒内生成的序列号,最多支持4096个 ID。
### 雪花算法 Java 实现
public class SnowflakeIdGenerator { // 基本参数 private final static long EPOCH = 1609459200000L; // 自定义的开始时间(2021-01-01 00:00:00) private final static long WORKER_ID_BITS = 10; // 工作机器ID占用的位数 private final static long DATACENTER_ID_BITS = 10; // 数据中心ID占用的位数 private final static long SEQUENCE_BITS = 12; // 序列号占用的位数// 计算各部分的位移 private final static long WORKER_ID_SHIFT = SEQUENCE_BITS; // 序列号位移 private final static long DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS; // 数据中心ID位移 private final static long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS; // 时间戳位移// 生成掩码 private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS); // 最大工作机器ID private final static long MAX_DATACENTER_ID = ~(-1L << DATACENTER_ID_BITS); // 最大数据中心ID private final static long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS); // 序列号掩码private long workerId; // 工作机器ID private long datacenterId; // 数据中心ID private long sequence = 0; // 序列号初始值 private long lastTimestamp = -1; // 上一次生成ID的时间戳public SnowflakeIdGenerator(long workerId, long datacenterId) { if (workerId > MAX_WORKER_ID || workerId < 0) { throw new IllegalArgumentException("workerId必须在0到" + MAX_WORKER_ID + "之间"); } if (datacenterId > MAX_DATACENTER_ID || datacenterId < 0) { throw new IllegalArgumentException("datacenterId必须在0到" + MAX_DATACENTER_ID + "之间"); } this.workerId = workerId; this.datacenterId = datacenterId; }private long currentTimeMillis() { return System.currentTimeMillis(); // 获取当前时间戳(毫秒) }public synchronized long generateId() { long timestamp = currentTimeMillis(); // 获取当前时间戳if (timestamp < lastTimestamp) { throw new RuntimeException("时钟向后移动,无法生成ID"); }if (lastTimestamp == timestamp) { sequence = (sequence + 1) & SEQUENCE_MASK; // 在同一毫秒内序列号加1 if (sequence == 0) { // 序列号已满,等待下一毫秒 while (timestamp <= lastTimestamp) { timestamp = currentTimeMillis(); } } } else { sequence = 0; // 重置序列号 }lastTimestamp = timestamp; // 更新上一次时间戳// 生成ID return ((timestamp - EPOCH) << TIMESTAMP_SHIFT) | (datacenterId << DATACENTER_ID_SHIFT) | (workerId << WORKER_ID_SHIFT) | sequence; }// 示例:创建一个雪花算法实例并生成ID public static void main(String[] args) { long workerId = 1; // 机器ID long datacenterId = 1; // 数据中心ID SnowflakeIdGenerator generator = new SnowflakeIdGenerator(workerId, datacenterId);// 生成10个ID for (int i = 0; i < 10; i++) { System.out.println(generator.generateId()); } } }
### 代码说明:
1. **类定义**:`SnowflakeIdGenerator` 是生成唯一ID的类。
2. **基本参数**:
- `EPOCH`:定义开始时间(自1970年1月1日以来的毫秒数)。
- `WORKER_ID_BITS`、`DATACENTER_ID_BITS`、`SEQUENCE_BITS`:分别定义工作机器ID、数据中心ID和序列号占用的位数。
3. **位移计算**:
- `WORKER_ID_SHIFT`、`DATACENTER_ID_SHIFT`、`TIMESTAMP_SHIFT`:用于计算ID各个部分的位移。
4. **掩码计算**:
- `MAX_WORKER_ID`、`MAX_DATACENTER_ID`、`SEQUENCE_MASK`:用于限制机器ID、数据中心ID和序列号的最大值。
5. **构造方法**:
- `SnowflakeIdGenerator(long workerId, long datacenterId)`:初始化工作机器ID和数据中心ID,检查其合法性。
6. **时间戳获取**:
- `currentTimeMillis()`:获取当前时间的毫秒数。
7. **ID生成**:
- `generateId()`:生成唯一的ID,处理序列号自增和时间戳更新,确保在高并发情况下生成不重复的ID。
8. **主方法**:
- `main(String[] args)`:创建 `SnowflakeIdGenerator` 实例并生成10个唯一的ID。
更多实用教程资源:http://sj.ysok.net/jydoraemon 访问码:JYAM