本文主要会介绍 GhostNet 系列网络,在本文中会给大家带来卷积结构的改进方面的轻量化,以及与注意力(self-attention)模块的进行结合,部署更高效,更适合移动计算的 GhostNetV2。让读者更清楚的区别 V2 与 V1 之间的区别。
GhostNet V1 模型
GhostNet V1:提供了一个全新的 Ghost Module,旨在通过廉价操作生成更多的特征图。基于一组原始的特征图,作者应用一系列廉价的线性变换(cheap linear operations),以很小的代价生成许多能从原始特征发掘所需信息的 Ghost 特征图。该 Ghost 模块即插即用,通过堆叠 Ghost Module 得出 Ghost bottleneck,进而搭建轻量级神经网络——GhostNet。在 ImageNet 分类任务,GhostNet 在相似计算量情况下 Top-1 正确率达 75.7%,高于 MobileNetV3 的 75.2%。
Ghost Module
利用Ghost Module生成与普通卷积层相同数量的特征图,我们可以轻松地将Ghost Module替换卷积层,集成到现有设计好的神经网络结构中,以减少计算成本。第一、先通过普通的 conv 生成一些特征图。第二、对生成的特征图进行 cheap 操作生成冗余特征图,这步使用的卷积是 DW 卷积。第三将 conv 生成的特征图与 cheap 操作生成的特征图进行 concat 操作。如下图(b)所示,展示了 Ghost 模块和普通卷积的过程。
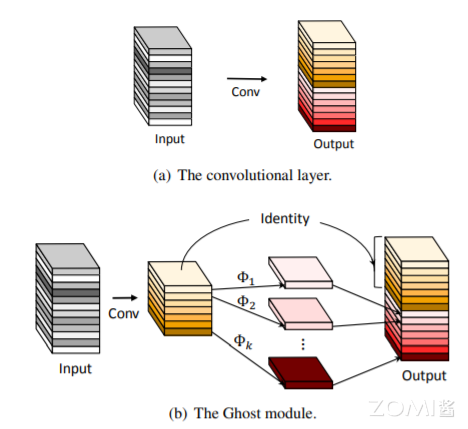
深度卷积神经网络通常引用由大量卷积组成的卷积神经网络,导致大量的计算成本。尽管最近的工作,例如 MobileNet 和 ShuffleNet 引入了深度卷积或混洗操作,以使用较小的卷积核(浮点运算)来构建有效的 CNN,其余 1×1 卷积层仍将占用大量内存和 FLOPs。鉴于主流 CNN 计算出的中间特征图中存在大量的冗余,作者提出减少所需的资源,即用于生成它们的卷积核。实际上,给定输入数据 $X∈R^{cxhxw}$,其中 c 是输入通道数,h 和 w 是高度,输入数据的宽度,分别用于生成 n 个特征图的任意卷积层的运算可表示为:
$$
Y=X*f+b
$$
其中 *是卷积运算,b 是偏差项,$Y∈R^{h'xw'xn}$ 是具有 n 个通道的输出特征图,$f∈R^{cxkxkxn}$ 是这一层中的卷积核。另外,h‘ 和 w' 分别是输出数据的高度和宽度,kxk 分别是卷积核 f 的内核大小。在此卷积过程中,由于卷积核数量 n 和通道数 c 通常非常大(例如 256 或 512),所需的 FLOPs 数量达 $n \cdot h' \cdot w' \cdot c \cdot k \cdot k$ 之多。
根据上述公式,要优化的参数数量($f$ 和 $b$ 中的参数)由输入和输出特征图的尺寸确定。如图 1 中所观察到的,卷积层的输出特征图通常包含很多冗余,并且其中一些可能彼此相似。作者指出,没有必要使用大量的 FLOP 和参数一一生成这些冗余特征图。这些原始特征图通常具有较小的大小,并由普通的卷积核生成。具体来说,$m$ 个原始特征图 $Y'∈R^{h' \times w' \times m}$ 是使用一次卷积生成的:
$$
Y'=X*f'
$$
其中 $f'∈R^{c \times k \times k \times m}$ 是使用的卷积核,$m\leq n$,为简单起见,这里省略了偏差项。超参数(例如卷积核大小,stride,padding)与普通卷积中的超参数相同,以保持输出特征图的空间大小(即 $h'$ 和 $w'$ )保持一致。为了进一步获得所需的 $n$ 个特征图,作者提出对 $Y'$ 中的每个原始特征应用一系列廉价的线性运算,以生成 s 个幻影特征图:
$$
y_{ij}=Φ_{i,j}(y'_{i}),\forall i=1,...,m,j=1,...,s
$$
其中 $Y'{i}$ 是 $Y'$ 中第 $i$ 个原始特征图,上述函数中的 $Φ$ 是第 j 个线性运算,用于生成第 jj 个特征图 $y_{ij}$ ,也就是说,$y'{i}$ 可以具有一个或多个特征图 ${y{i,j}}^{s}{j=1}$ 。最后的 $Φ$ 是用于保留原始特征图的恒等映射,通过操作,我们可以获得 $n=m\cdots$ 个特征图 $Y=[y_{11},y_{12},...,y_{ms}]$ 作为 Ghost module 的输出数据。注意,线性运算 $Φ$ 在每个通道上运行,其计算量比普通卷积少得多。实际上,Ghost module 中可能有几种不同的线性运算。
复杂度分析
Ghost module 具有一个恒等映射和 $m \cdot (s-1) = \frac{n}{s}\cdot (s-1)$ 个线性运算,并且每个线性运算的平均内核大小 $d \times d$。理想情况下,$n \cdot (s-1)$ 个线性运算可以具有不同的形状和参数,但是特别是考虑到 CPU 或 GPU 的实用性,在线推理会受到阻碍。因此,作者建议在一个 Ghost 模块中采用相同大小的线性运算以高效实现 Ghost module。使用 Ghost module 升级普通卷积的理论加速比为:
$$
r_{s}=\frac{n\cdot h' \cdot w' \cdot c \cdot k \cdot k}{\frac{n}{s}\cdot h'\cdot w' \cdot c \cdot k \cdot k +(s-1)\cdot \frac{n}{s}\cdot h'\cdot w' \cdot d \cdot d}
$$
$$
=\frac{c\cdot k \cdot k}{\frac{1}{s}\cdot{c}\cdot{k}\cdot{k}+\frac{s-1}{s}\cdot d \cdot d} ≈\frac{s\cdot c}{s+c-1} ≈ s
$$
其中 $d \times d$ 的幅度与 $k \times k$ 相似,并且 $s\ll c$。同样,参数压缩比可以计算为:
$$
r_{c} =\frac{n\cdot c\cdot k \cdot k}{\frac{n}{s}\cdot{c}\cdot{k}\cdot{k}+(s-1)\cdot \frac{n}{s}\cdot d \cdot d} ≈\frac{s\cdot c}{s+c-1} ≈ s
$$
其实 GhostNet 的方法也很简单,无外乎就是将原本的乘法变成了两个乘法相加,然后在代码实现中,其实第二个变换是用 depthwise conv 实现的。作者在文中也提到,前面的卷积使用 pointwise 效率比较高,所以网络嫣然类似一个 mobilenet 的反过来的版本,只不过 GhostNet 采用了拼接的方式,进一步减少了计算量。Ghost module 的 pytorch 代码如下:
#Ghost 模块,以普通卷积和 DW 卷积组合而成
class GhostModule(nn.Module):def __init__(self, in_channels,out_channels,s=2, kernel_size=1,stride=1, use_relu=True):super(GhostModule, self).__init__()intrinsic_channels = out_channels//sghost_channels = intrinsic_channels * (s - 1)self.primary_conv = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=intrinsic_channels, kernel_size=kernel_size, stride=stride,padding=kernel_size // 2, bias=False),nn.BatchNorm2d(intrinsic_channels),nn.ReLU(inplace=True) if use_relu else nn.Sequential())self.cheap_op = DW_Conv3x3BNReLU(in_channels=intrinsic_channels, out_channels=ghost_channels, stride=stride,groups=intrinsic_channels)def forward(self, x):y = self.primary_conv(x)z = self.cheap_op(y)out = torch.cat([y, z], dim=1)return out
Ghost bottleneck
Ghost bottleneck 与 ResNet 中的基本残差块(Basic Residual Block)结构相似,可以认为是将 Basic Residual Block 中的卷积操作用 Ghost Module 替换得到。
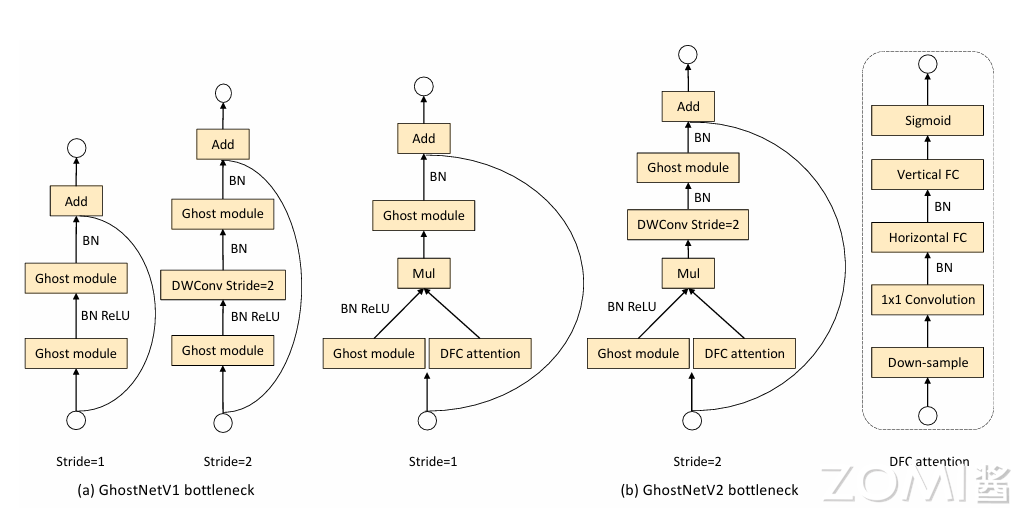
Ghost bottleneck 主要由两个堆叠的 Ghost Module 组成。第一个 Ghost Module 用于增加通道数。第二个 Ghost Module 用于减少通道数,以与 shortcut 路径匹配。然后,使用 shortcut 连接这两个 Ghost Module 的输入和输出。这里借鉴了 MobileNetV2,第二个 Ghost Module 之后不使用 ReLU 激活函数,其他层在每层之后都应用了批量归一化(BN)和 ReLU 非线性激活。作者设计了 2 种 Ghost bottleneck。如下图所示,分别对应着 stride=1 和 stride=2 的情况。Ghost bottleNeck 结构如下图所示:
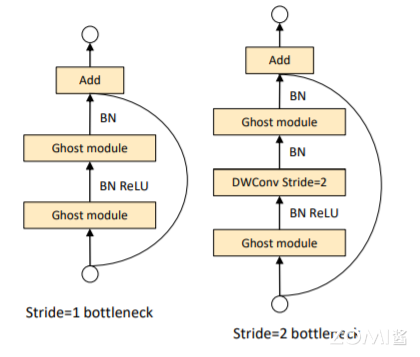
左图中,主干通路用两 Ghost Module 串联组成,其中第一个 Ghost Module 扩大通道数,第二个 Ghost Module 将通道数降低到与输入通道数一致;残差边部分与 ResNet 一样。由于 Stride=1,因此不会对输入特征图的高和宽进行压缩,其功能为加深网络的深度。
右图中,主干通路的两个 Ghost Module 之间加入了一个 Stride=2 的 DWConv,可以将特征图高和宽进行压缩,使其大小降为输入的 $\frac {1}{2}$;在残差边部分,也会添加一个步长为 2 的 DWConv 和 1x1 的 PWConv,以保证 Add 操作可以对齐。这个模块可以用来替换其他 CNN 中的下采样层(1/2)。出于效率考虑,Ghost Module 中的所有标准卷积都用 PWConv 代替。
#Ghost 瓶颈层实现
class GhostBottleneck(nn.Module):def __init__(self, in_channels,mid_channels, out_channels , kernel_size, stride, use_se, se_kernel_size=1):super(GhostBottleneck, self).__init__()self.stride = strideself.bottleneck = nn.Sequential(GhostModule(in_channels=in_channels,out_channels=mid_channels,kernel_size=1,use_relu=True),DW_Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=stride,groups=mid_channels) if self.stride>1 else nn.Sequential(),SqueezeAndExcite(mid_channels,mid_channels,se_kernel_size) if use_se else nn.Sequential(),GhostModule(in_channels=mid_channels, out_channels=out_channels, kernel_size=1, use_relu=False))if self.stride>1:self.shortcut = DW_Conv3x3BNReLU(in_channels=in_channels, out_channels=out_channels, stride=stride)else:self.shortcut = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1)def forward(self, x):out = self.bottleneck(x)residual = self.shortcut(x)out += residualreturn out
网络结构
GhostNet 主要由一堆 Ghost bottleneck 组成,其中 Ghost bottleneck 以 Ghost 模块为构建基础;
第一层是具有 16 个卷积核的标准卷积层,然后是一系列 Ghost bottleneck,通道逐渐增加。这些 Ghost bottleneck 根据其输入特征图的大小分为不同的阶段;除了每个阶段的最后一个 Ghost bottleneck 是 stride = 2,其他所有 Ghost bottleneck 都以 stride = 1 进行应用;
最后,利用全局平均池和卷积层将特征图转换为 1280 维特征向量以进行最终分类。SE 模块也用在了某些 Ghost bottleneck 中的残留层;
与 MobileNetV3 相比,这里用 ReLU 换掉了 Hard-swish 激活函数。尽管进一步的超参数调整或基于自动架构搜索的 Ghost 模块将进一步提高性能;
GhostNet V2 模型
GhostNet V2:GhostV2 的主要工作就是在 Ghost module 的基础上,添加了一个改进的注意力块。文中称为解耦全连接注意力机制 DFC(Decouplod fully connected)。它不仅可以在普通硬件上快速执行,还可以捕获远程像素之间的依赖关系。大量的实验表明,GhostNetV2 优于现有的体系结构。例如,它在具有 167M FLOPs 的 ImageNet 上实现了 75.3%的 top-1 精度,显著高于 GhostNetV1 (74.5%),但计算成本相似。
DFC 模块
虽然自注意力操作可以很好地建模长距离依赖,但是部署效率低。相比自注意力机制,具有固定权重的 FC 层更简单,更容易实现,也可以用于生成具有全局感受野的 attention maps。
给定特征图 $Z ∈ R ^{H \times W\times C}$,它可以看作 hw 的 tokens,记作 $z_{i}\in R^{C}$,也就是 $Z={z_{11},z_{12},...,z_{hw}}$。FC 层生成 attention map 的公式表达如下:
$$
a_{hw} = \sum_{h',w'} F_{h,w,h',w'}\odot z_{h',w'}\tag{1}
$$
其中,$\odot$ 表示 element-wise multiplication,F 是 FC 层中可学习的权重,$A={a_{11},a_{12},...,a_{HW}}$。根据上述公式,将所有 tokens 与可学习的权重聚合在一起以提取全局信息,该过程比经典的自注意力简单的多。然而,该过程的计算复杂度仍然是二次方,特征图的大小为 $\mathcal{O}({H{2}W{2}})$,这在实际情况下是不可接受的,特别是当输入的图像是高分辨率时。
例如,对于 4 层的 GhostNet 网络的特征图具有 3136 $(56 \times 56)$ 个 tokens,这使得计算变得 attention maps 异常复杂。实际上,CNN 中的特征图通常是低秩的,不需要将不同空间位置的所有输入和输出的 tokens 密集地连接起来。特征的 2D 尺寸很自然地提供一个视角,以减少 FC 层的计算量,也就是根据上述公式分解为两个 FC 层,分别沿水平方向和垂直方向聚合特征,其公式表达如下:
$$
a'{hw} =\sum{H}F{h,h'w}\odot z,h=1,2,...,H,w=1,2,...,W \tag{2}
$$
$$
a_{hw} =\sum_{w'=1}{W}F{w,hw'}\odot z,h=1,2,...,H,w=1,2,...,W \tag{3}
$$
其中,$F^{H}$ 和 $F^{W}$ 是变换的权重。输入原始特征 Z,并依次应用公式(2)和公式(3),分别提取沿两个方向的长距离依赖关系。作者将此操作称为解耦全连接注意力(decoupled fully connected attention,DFC attention),其信息流如下图所示:
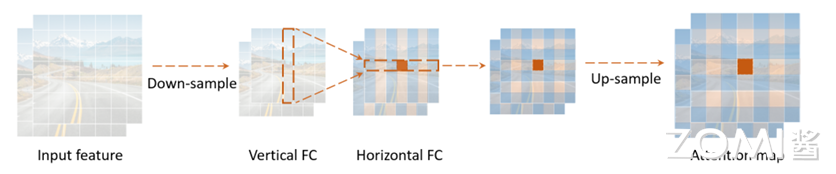
由于水平和垂直方向变换的解耦,注意力模块的计算复杂度可以降低到 $\mathcal{O}(H{2}W+HW)$ 对于 full attention (公式 1),正方形区域内的所有 patches 直接参与被聚合 patch 的计算。在 DFC attention 中,一个 patch 直接由其垂直方向和水平方向的 patch 进行聚合,而其他 patch 参与垂直线/水平线上的 patch 的生成,与被聚合的 token 有间接关系。因此,一个 patch 的计算也涉及到正方形区域的所有 patchs。
公式(2)和公式(3)是 DFC attention 的一般表示,分别沿着水平和垂直方向聚合像素。通过共享部分变换权重,可以方便地使用卷积操作实现,省去了影响实际推理速度的耗时张量的 reshape 操作和 transpose 操作。为了处理不同分辨率的输入图像,卷积核的大小可以与特征图的大小进行解耦,也就是在输入特征上依次进行两个大小为 $1 \times K_{H}$ 和 $ K_{W} \times 1$ 的 DWConv 操作。当用卷积操作时,DFC attention 理论上的计算复杂度为 $\mathcal{O}(K_{H}HW+K_{W}HW)$。这种策略得到了 TFLite 和 ONNX 等工具的良好支持,可以在移动设备上进行快速推理。
class GhostModuleV2(nn.Module):def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True,mode=None,args=None):super(GhostModuleV2, self).__init__()self.mode=modeself.gate_fn=nn.Sigmoid()if self.mode in ['original']:self.oup = oupinit_channels = math.ceil(oup / ratio) new_channels = init_channels*(ratio-1)self.primary_conv = nn.Sequential( nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),nn.BatchNorm2d(init_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)self.cheap_operation = nn.Sequential(nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),nn.BatchNorm2d(new_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)elif self.mode in ['attn']: self.oup = oupinit_channels = math.ceil(oup / ratio) new_channels = init_channels*(ratio-1)self.primary_conv = nn.Sequential( nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),nn.BatchNorm2d(init_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)self.cheap_operation = nn.Sequential(nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),nn.BatchNorm2d(new_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),) self.short_conv = nn.Sequential( nn.Conv2d(inp, oup, kernel_size, stride, kernel_size//2, bias=False),nn.BatchNorm2d(oup),nn.Conv2d(oup, oup, kernel_size=(1,5), stride=1, padding=(0,2), groups=oup,bias=False),nn.BatchNorm2d(oup),nn.Conv2d(oup, oup, kernel_size=(5,1), stride=1, padding=(2,0), groups=oup,bias=False),nn.BatchNorm2d(oup),) def forward(self, x):if self.mode in ['original']:x1 = self.primary_conv(x)x2 = self.cheap_operation(x1)out = torch.cat([x1,x2], dim=1)return out[:,:self.oup,:,:] elif self.mode in ['attn']: res=self.short_conv(F.avg_pool2d(x,kernel_size=2,stride=2)) x1 = self.primary_conv(x)x2 = self.cheap_operation(x1)out = torch.cat([x1,x2], dim=1)return out[:,:self.oup,:,:]*F.interpolate(self.gate_fn(res),size=(out.shape[-2],out.shape[-1]),mode='nearest') 增强 Ghost 模块
Ghost Module 中只有 m 个特征与其他像素交互,这影响了 Ghost Module 提取空间信息(spatial information)的能力。因此,作者使用 DFC attention 来增强 Ghost Module 的输出特征 Y ,从而来捕获不同空间像素之间的长距离依赖关系。输入特征 $X \in R^{h \times w \times c}$ 被送入两个分支,一个是 Ghost Module 分支,用于输出特征 Y,另一个是 DFC attention Module 分支,用于生成 attention map,记作 $A$。
回想一下,在经典的自注意力中,线性变换层将输入特征图转换为计算 attention maps 的 query 和 key。类似的,作者实现一个 $1 \times 1$ 的卷积操作,将 Ghost Module 分支的输入 $X$ 转换为 DFC module 分支的输入 $Z$。两个分支输出的乘积,即为最终输出 $O\in {R}^{H \times W\times C}$ 可以表示为:
$$
\mathcal{O} = Sigmoid(A)\odot V(X)
$$
其中,$\odot$ 表示 element-wise multiplication,$A$ 是 attention map,Sigmoid 是归一化函数以缩放到 ( 0 , 1 ) 范围。$ \mathcal{V}()$ 表示 Ghost Module,$X $ 为输入特征。则信息聚合过程如下图所示:
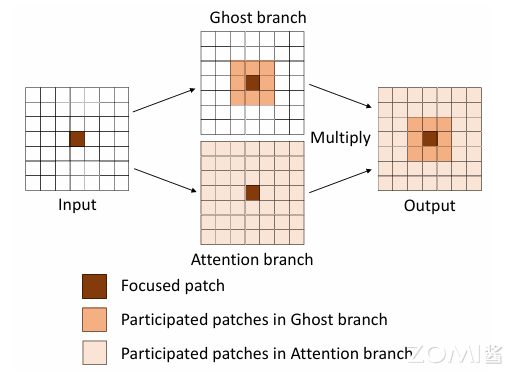
使用相同的输入特征,Ghost Module 和 DFC attention 是两个从不同角度提取信息的并行分支。输出特征是它们逐元素的信息,其中包含来自 Ghost Module 的特性和 DFC attention 的信息。每个 attention value 涉及到大范围的 patches,以便输出的特征可以包含这些 patches 的信息。
模型结构实现
为了减小 DFC attention 模块所消耗的计算量,本文对 DFC 这条支路上的特征进行下采样,在更小的特征图上执行一系列变换。同时,本文发现,对一个逆 bottleneck 结构而言,增强“expressiveness”(bottleneck 中间层)比“capacity”(bottleneck 输出层)更加有效,因此在 GhostNetV2 只对中间特征做了增强。GhostNetV2 的 bottleneck 如下图所示。
class GhostBottleneckV2(nn.Module): def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,stride=1, act_layer=nn.ReLU, se_ratio=0.,layer_id=None,args=None):super(GhostBottleneckV2, self).__init__()has_se = se_ratio is not None and se_ratio > 0.self.stride = stride# Point-wise expansionif layer_id<=1:self.ghost1 = GhostModuleV2(in_chs, mid_chs, relu=True,mode='original',args=args)else:self.ghost1 = GhostModuleV2(in_chs, mid_chs, relu=True,mode='attn',args=args) # Depth-wise convolutionif self.stride > 1:self.conv_dw = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride=stride,padding=(dw_kernel_size-1)//2,groups=mid_chs, bias=False)self.bn_dw = nn.BatchNorm2d(mid_chs)# Squeeze-and-excitationif has_se:self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)else:self.se = Noneself.ghost2 = GhostModuleV2(mid_chs, out_chs, relu=False,mode='original',args=args)# shortcutif (in_chs == out_chs and self.stride == 1):self.shortcut = nn.Sequential()else:self.shortcut = nn.Sequential(nn.Conv2d(in_chs, in_chs, dw_kernel_size, stride=stride,padding=(dw_kernel_size-1)//2, groups=in_chs, bias=False),nn.BatchNorm2d(in_chs),nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),nn.BatchNorm2d(out_chs),)def forward(self, x):residual = xx = self.ghost1(x)if self.stride > 1:x = self.conv_dw(x)x = self.bn_dw(x)if self.se is not None:x = self.se(x)x = self.ghost2(x)x += self.shortcut(residual)return x
如果您想了解更多AI知识,与AI专业人士交流,请立即访问昇腾社区官方网站https://www.hiascend.com/或者深入研读《AI系统:原理与架构》一书,这里汇聚了海量的AI学习资源和实践课程,为您的AI技术成长提供强劲动力。不仅如此,您还有机会投身于全国昇腾AI创新大赛和昇腾AI开发者创享日等盛事,发现AI世界的无限奥秘~
转载自:https://www.cnblogs.com/ZOMI/articles/18561178