实验二:逻辑回归算法实现与测试
一、实验目的
深入理解对数几率回归(即逻辑回归的)的算法原理,能够使用 Python 语言实现对数
几率回归的训练与测试,并且使用五折交叉验证算法进行模型训练与评估
二、实验内容
(1)从 scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注意同分布取样);
(2)使用训练集训练对数几率回归(逻辑回归)分类算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验二的部分。
三、算法步骤、代码、及结果
1. 算法伪代码
步骤1: 加载iris数据集
步骤2: 划分数据集为训练集和测试集(留出法,1/3作为测试集)
步骤3: 初始化逻辑回归模型
步骤4: 使用训练集训练逻辑回归模型
步骤5: 使用五折交叉验证评估模型性能(准确度、精度、召回率和F1值)
步骤6: 使用测试集测试模型性能
步骤7: 输出训练和测试结果(准确率、精度、召回率和F1值)
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
# 导入所需的库
from sklearn.datasets import load_iris # 用于加载数据集
from sklearn.model_selection import train_test_split, cross_val_score # 用于数据划分和交叉验证
from sklearn.linear_model import LogisticRegression # 逻辑回归模型
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 评估指标
# 加载iris数据集
iris = load_iris()
X, y = iris.data, iris.target
# 使用留出法将数据集划分为训练集和测试集,测试集占1/3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3, random_state=42)
# 初始化逻辑回归模型,max_iter设置为200以确保收敛
logreg = LogisticRegression(max_iter=200)
# 使用训练集训练逻辑回归模型
logreg.fit(X_train, y_train)
# 使用五折交叉验证评估模型性能,这里我们关注的是准确度
cv_scores = cross_val_score(logreg, X_train, y_train, cv=5, scoring='accuracy')
# 在训练集上评估模型性能
accuracy = accuracy_score(y_train, logreg.predict(X_train)) # 准确率
precision = precision_score(y_train, logreg.predict(X_train), average='macro') # 精度(查准率)
recall = recall_score(y_train, logreg.predict(X_train), average='macro') # 召回率(查全率)
f1 = f1_score(y_train, logreg.predict(X_train), average='macro') # F1值
# 打印训练集的性能指标
print(f"交叉验证平均准确率: {cv_scores.mean():.2f} +/- {cv_scores.std():.2f}")
print(f"训练集准确率: {accuracy:.2f}")
print(f"训练集精度(查准率): {precision:.2f}")
print(f"训练集召回率(查全率): {recall:.2f}")
print(f"训练集F1值: {f1:.2f}")
调用库方法(函数参数说明)
- train_test_split(X, y, test_size=1/3, random_state=42): 划分数据集为训练集和测试集,test_size参数指定测试集的比例,random_state用于确保结果的可重复性。
- LogisticRegression(max_iter=200): 初始化逻辑回归模型,max_iter参数指定最大迭代次数。
- cross_val_score(model, X, y, cv=5, scoring='accuracy'): 进行交叉验证,cv参数指定折数,scoring参数指定评分标准。
- accuracy_score(y_true, y_pred): 计算准确率,y_true为真实标签,y_pred为预测标签。
- precision_score(y_true, y_pred, average='macro'): 计算精度,average参数指定平均方法。
- recall_score(y_true, y_pred, average='macro'): 计算召回率,average参数指定平均方法。
- f1_score(y_true, y_pred, average='macro'): 计算F1值,average参数指定平均方法。
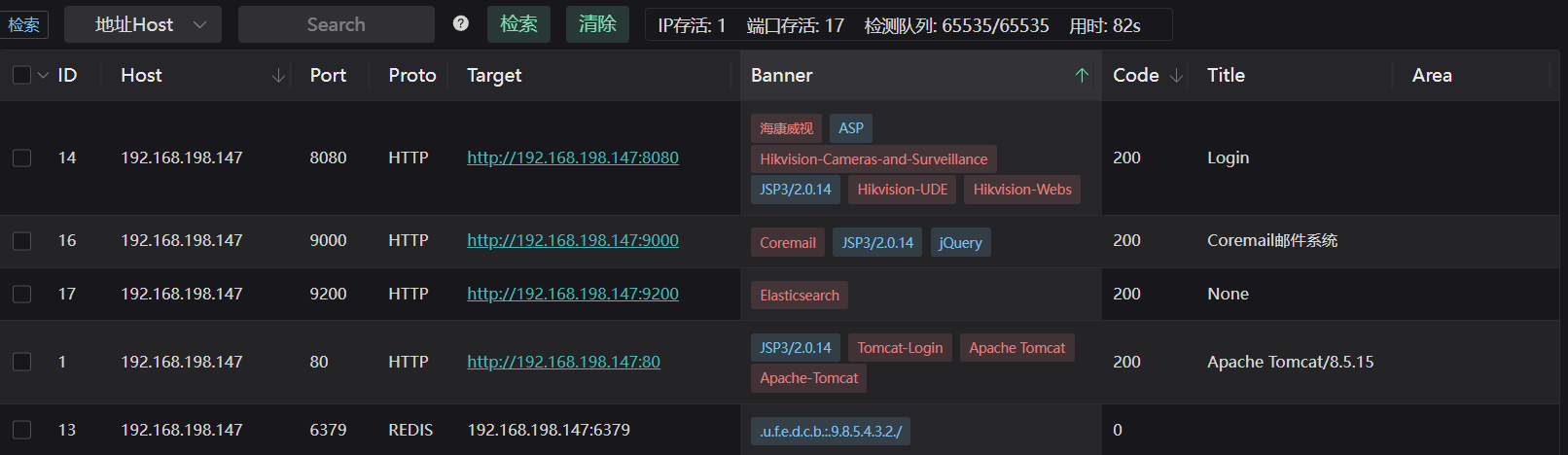
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
四、实验结果分析
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
- 对比分析
训练集与测试集性能对比:
准确率对比:比较模型在训练集和测试集上的准确率,检查是否有过拟合或欠拟合的现象。如果训练集的准确率远高于测试集,可能存在过拟合;如果测试集的准确率远高于训练集,可能存在数据泄露或模型欠拟合。
精度、召回率和F1值对比:同样,对比这些指标在训练集和测试集上的表现,分析模型在不同数据集上的稳定性和一致性。
交叉验证结果分析:
稳定性:通过五折交叉验证得到的标准差可以衡量模型性能的稳定性。如果标准差较小,说明模型在不同训练集划分下的性能较为稳定;如果标准差较大,则模型性能可能对数据划分敏感。
参数调整的影响:
如果在实验中调整了逻辑回归模型的参数(例如正则化强度、最大迭代次数等),可以对比不同参数设置下的性能,分析哪些参数对模型性能有显著影响。
不同分类阈值的影响:
逻辑回归模型的分类阈值默认为0.5,但这个阈值是可以调整的。对比不同阈值下的性能指标,可以找到最优的分类阈值。
模型泛化能力:
通过比较训练集和测试集的性能,可以评估模型的泛化能力。一个好的模型应该在训练集上有较高的准确率,同时在未见过的测试集上也能保持较好的性能。
数据不平衡的影响:
如果数据集中的类别分布不均匀,需要分析这对模型性能的影响。可以通过调整类别权重或使用其他技术来处理数据不平衡问题,并对比处理前后的性能差异。


![[CSP2020-J4] 直播获奖](https://img-blog.csdnimg.cn/img_convert/5c8cf286e7bf2c08f859b337286669e9.png)