人类是骄傲的生物。最近,关于AI是否具备推理能力的争论愈演愈烈。几个月前发布的OpenAI的o1模型引发了各种反应,有人认为它“不过是些障眼法”,也有人称之为“AI的新范式”。
AI的推理能力(或者缺乏推理能力)似乎触动了我们许多人敏感的神经。我怀疑,承认AI会“推理”被视为对人类自尊的打击,因为推理不再是人类独有的能力。
19世纪时,算术被认为是一种智力技能(嘿,你什么时候见过一头牛加两数的?)。尽管如此,我们还是不得不习惯使用比我们强得多的计算器。
我见过一些惊人的言论,从“我们即将实现通用人工智能”或“AI已达到博士水平”到完全否认AI推理能力的激进言论,比如“苹果驳斥AI革命”。
在其他文章中,我评论过马斯克粉丝宣称的AGI观点有多荒谬。而在这篇文章中,我要探讨另一端的观点:那些声称AI根本不能推理的人。
加里·马库斯(Gary Marcus),一个最直言不讳的AI否认者(我不称他们为“怀疑者”),说AI或许擅长模式识别,但缺乏“真正的推理能力”。
此外,马库斯称AI聊天机器人是“升级版的自动补全”,并为艾米丽·本德(Emily Bender)早期针对ChatGPT创造的著名贬义词“随机鹦鹉”增添了一个新名词。
那么,到底什么是“真正的推理”?我将在下文试图回答这个问题。
甚至更有声望的思想领袖,比如诺姆·乔姆斯基(Noam Chomsky),也认为AI无法“真正思考”,因为它缺乏对“意义的理解”。他还认为AI永远无法与人类在创造力和抽象思维能力上竞争。
LLM能推理吗?
在这些关于AI推理能力的激烈争论中,我们如何分辨基于事实的观点与单纯的情绪或意见?答案当然是:审视证据。
但在这场争论中,什么算作“事实”?注意,什么能被视为“事实”很大程度上取决于你如何定义“推理”,尤其当某些人进一步强调它应该是“真正的推理”时。例如,Salvatore Raieli最近在一篇文章中问道:
“大语言模型(LLMs)能真正推理吗?”
这里的关键术语是“真正的”。“推理”和“真正的推理”之间的区别是什么?我怀疑这里存在一种拟人化偏见,好像“真正的推理”实际上意味着“像我们人类一样推理,我们是这个宇宙中唯一真正会推理的生物。”
我倾向于将“推理”视为解决被公认为需要推理的问题的认知能力。这包括数学推理、常识推理、语言理解和推断。
这种定义可能有一定的循环性。但一旦我们同意与能力相关的问题集合,接下来的问题就是检查AI系统能否解决这些问题。问题在于,如我在下文所述,当前AI能够解决一个问题,却在人类看来类似的问题上惨败。
注意,在使用这个定义时,我与著名的“图灵测试”保持距离。图灵测试的目标是欺骗一群人类评委,让他们以为自己在与人类对话。如果你不了解图灵测试,可以阅读我的文章《为什么图灵测试变得过时?》
我也与那些认为AI需要“像人类一样推理”才能被认为智能的主观观点保持距离。我认为“像人类一样推理”这个表达模糊、拟人化且无用。
在本文的最后部分,我会论证现代AI完全不是“像人类一样推理”;它实际上是一种非人类或“外星”智能。
最后,还有人声称“真正的推理”是通过多个步骤进行思考,这被称为“思维链”(Chain of Thought, CoT)。
这一想法与AI聊天机器人相关,起源于谷歌研究团队2022年的论文《思维链提示引发大语言模型的推理》。同样的想法(经过良好实施)在OpenAI的o1中被应用,这导致一些人宣称它是“AI的新范式”。
我并不反对在AI中使用CoT,比如在o1中(测试结果清楚地显示了改进)。尽管如此,我认为推理是一种认知能力,并非多步骤推理所独有。
推理也不局限于“解决复杂问题”(正如Raieli在上述文章中所说)。对我而言,推理可以是简单的也可以是复杂的,应该为每种形式设定客观的测试。
此时,你或许能看出为什么许多人认为“AI无法推理”:
• 有些人认为AI无法“真正推理”或“像人类一样思考”;
• 另一些人认为AI应该擅长“复杂推理和问题解决”,无视较简单的推理形式;
• 还有些人否认任何非多步骤推理形式的推理。
如同许多事情一样,问题的关键在于细节,而这里的细节在于如何定义所谓的“推理能力”。正如我在上文所述,这些对AI推理能力的反对意见是一种偏见,因为它们在一开始就操纵了“推理”的含义。
现在,让我们来探讨如何验证甚至测量推理。
测量智能(或其缺乏)
请记住,我们衡量认知能力的标准与欺骗毫无防备的人类、让他们以为自己“在与有灵魂的实体交流”无关,这种观点让我想起前谷歌工程师布莱克·勒莫因(Blake Lemoine)的多彩却误导性的看法,他因道德原因拒绝关闭一个“有意识的”AI聊天机器人。
不,我们的认知能力测试不应该依赖于主观印象,而应基于标准问题库,比如:
• HellaSwag和WinoGrande,用于评估常识推理能力;
• GLUE和SuperGLUE,用于评估自然语言理解;
• InFoBench,用于验证指令执行能力;
• AI2 Reasoning Challenge (ARC),其中包括思维链能力测试。
每个问题库的目标略有不同,但它们都探索了一种形式的“推理”。值得注意的是,“推理”并不是一个单一的任务,许多此类任务都可以被认定为“推理”。
从ChatGPT早期版本起,我最为震惊的一点就是它执行指令的能力。事实上,这也是让我改变对LLM推理能力看法的原因之一,正如我将在下文解释的那样。
有一天,我听到一个来自微软(当时)研究员塞巴斯蒂安·布贝克(Sebastien Bubeck,现任OpenAI)的无可辩驳的论点,关于LLM的推理能力:
如果AI不理解指令,它怎么能执行它们?
布贝克的意思不是AI声明“我理解了你的问题”,而是AI根据提示指令表现出符合要求的行为,并由人类(或外部程序)验证其行为是否正确。
如今,有了指令执行的基准测试,这一论点可以规模化。
接下来,让我们看看常识推理。常识推理被认为是人类的典型特质,不是吗?然而,事实证明,常识推理也可以通过像WinoGrande这样的基准测试来评估。
让我们看看WinoGrande问题的运作方式。大多数问题是关于代词解析的,例如:
“安问玛丽图书馆几点关门,因为她忘了。”
“她”是指安还是玛丽?
对人类来说,很容易判断“她”指的是安,因为她是提问的人。但对机器而言,这类问题可能很棘手。
显然,当使用问题库评估AI系统的认知能力时,确保系统之前没有接触过这些问题至关重要;否则会出现“数据污染”。
那么,AI在这些问题库上的表现如何?
公平比较的一个障碍是,每个AI公司使用不同的问题库进行测试,我怀疑他们选择那些自己的系统表现最佳的测试。这可能就是为什么目前最常用的比较是基于人类投票的“聊天机器人竞技场”,而不是基于问题库的测试。这又让我们回到了图灵测试的缺陷……
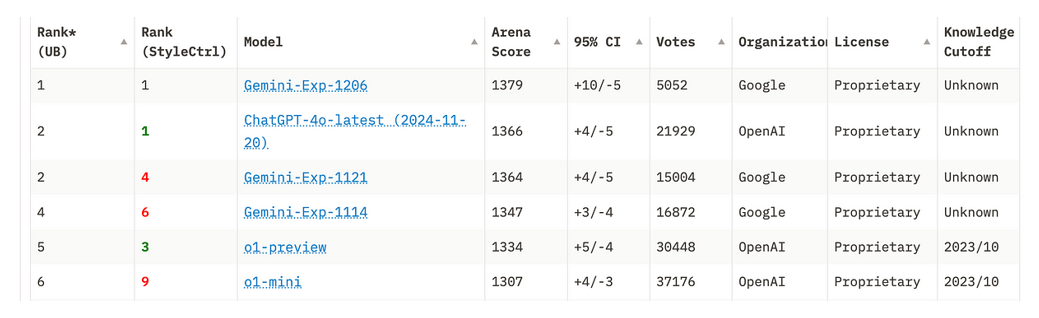
聊天机器人竞技场排名(截至2024年12月10日)
在HellaSwag中,Gemini Pro 1.5的准确率达到92.5%,而GPT-4 Turbo达到96%。
OpenAI 1,Google 0。
在MMLU(类似于GLUE测试)中,GPT-4的准确率约为87%,而Gemini Ultra达到90%。
OpenAI 1,Google 1。
我们可以继续这种比较,但事实上,最先进的LLM在性能上相差无几。一个原因是顶级AI专家在公司间的不断流动,这是一场没有止境的洗牌。
关键是,当今最好的LLM拥有无法简单归因于好运或记忆的认知能力。这就是为什么在我看来,臭名昭著的“随机鹦鹉”一词几乎毫无意义。
一种外星智能
当遇到像现代AI这样的智能形式时,我们人类有时会感到困惑甚至惊讶,这是有原因的(这里指基于LLM的AI)。
在最近的一篇文章中,我展示了人类智能与现代AI的差异,具体包括:
-
人类有情感;机器只是假装有情感。
-
人类要么理解,要么不理解。
-
机器不会犹豫。
这三者都反映了AI与人类的显著差异,但这里我重点讨论第二点,因为它与推理最为相关。
当我们人类产生“顿悟”时,那是一种“确定性”的理解,不相关的细节不会动摇这种理解。但对机器而言,情况却并非如此。
苹果研究人员最近发表的一篇论文(苹果通常避讳公开研究以保护机密性)引发了强烈反响(好评居多)。该论文展示了LLM在推断任务中的根本局限性。
他们在测试数学推理时,使用了一种特殊的基准评估方法,并进行了有趣的实验。比如,在测量系统对一组查询的表现后,他们进行了所谓的无关修改,如更改名称和数字或引入无关项。然后发现,当重新运行查询时,系统表现显著下降。
为什么修改无关信息会导致性能大幅下降?在人类的类似情况下,几乎总能识别出哪些是相关信息,哪些是无关信息,并忽略无关内容。而机器往往难以做到这一点,尽管在许多情况下能正确处理,但性能依然显著下降。
苹果的实验无可辩驳。然而,如何解读这些发现则是见仁见智的问题。
当得出结论时,我发现苹果研究人员和其他人一样有偏见。他们说,例如,“当前的LLM无法进行真正的逻辑推理。”我猜你能发现这句话中的关键词;当然是“真正的”。我们又一次将人类推理视为唯一的“真实”形式。
结语
大多数对AI推理的否定依赖于一种偏见,通常与“AI应像人类一样推理”的假设有关。如果不是,它就不算推理,或者不被承认是推理。
归根结底,这一切都取决于我们如何定义“AI能够推理”。
有人将模式匹配与完全不能“真正推理”划上等号,即使在大多数情况下AI给出了正确答案。
这就像说,任何通过模式匹配完成的都“不算推理”。但如果AI在许多——而非所有——推理测试中给出正确答案呢?如果AI在逐步提高解决推理问题的准确率,无论它是否使用模式匹配?
再次强调,我看到我们的“人类自尊”在作祟。我们人类是宇宙的主宰,不是吗?所以,我们的推理应该是唯一有效的推理方式。我们已经被计算器、国际象棋中的深蓝(Deep Blue)、围棋中的AlphaGo超越了一次又一次。而现在,我们的一般推理能力又被“规模化模式匹配”设备所挑战。
我们是坚持以“人类为中心”的观点,认为自己是宇宙的主宰,还是采纳一种更谦逊、更现实的理解:承认人类是美妙但有限的生物,可以与其他形式的智能互动?