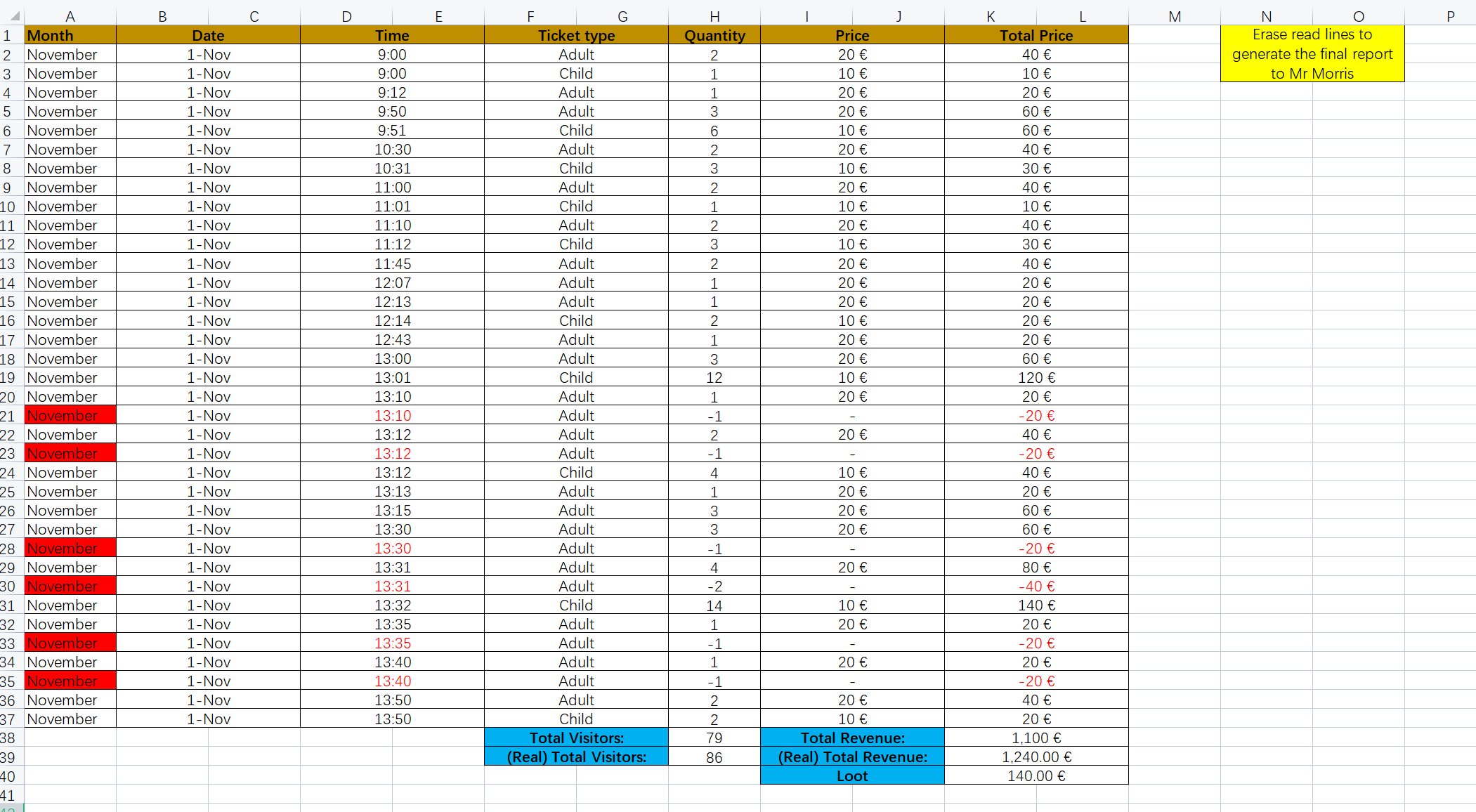
Awesome-Compositional-Zero-Shot
Papers and codes about Compositional Zero Shot Learning(CZSL) for computer vision are present on this page. Besides, the commonly-used datasets for CZSL are also introduced.
Papers
2024
| Title | Venue | Dataset | CODE | 可用性 | |
|---|---|---|---|---|---|
| Imaginary-Connected Embedding in Complex Space for Unseen Attribute-Object Discrimination | TPAMI 2024 | MIT-States & UT-Zappos & C-GQA | CODE | 无代码 | |
| Disentangling Before Composing: Learning Invariant Disentangled Features for Compositional Zero-Shot Learning | TPAMI 2024 | UT-Zappos & C-GQA & AO-CLEVr | CODE | 效果差 | |
| Simple Primitives With Feasibility- and Contextuality-Dependence for Open-World Compositional Zero-Shot Learning | TPAMI 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| C2C: Component-to-Composition Learning for Zero-Shot Compositional Action Recognition | ECCV 2024 | C-GQA & Sth-com | CODE | 与视频有关? | |
| Prompting Language-Informed Distribution for Compositional Zero-Shot Learning | ECCV 2024 | MIT-States & C-GQA & VAW-CZSL | CODE | 创新点是使用了大模型,难以基于此改进? | |
| MRSP: Learn Multi-representations of Single Primitive for Compositional Zero-Shot Learning | ECCV 2024 | MIT-States UT-Zappos & Clothing16K | - | ||
| Understanding Multi-compositional learning in Vision and Language models via Category Theory | ECCV 2024 | MIT-States & UT-Zappos & C-GQA | CODE | 无代码 | |
| Beyond Seen Primitive Concepts for Attributes-Objects Compositional Learning | CVPR 2024 | MIT-States & C-GQA & VAW-CZSL | - | ||
| Context-based and Diversity-driven Specificity in Compositional Zero-Shot Learning | CVPR 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| Troika: Multi-Path Cross-Modal Traction for Compositional Zero-Shot Learning | CVPR 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| Retrieval-Augmented Primitive Representations for Compositional Zero-Shot Learning | AAAI 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| ProCC: Progressive Cross-primitive Compatibility for Open-World Compositional Zero-Shot Learning | AAAI 2024 | MIT-States & UT-Zappos & C-GQA | CODE | 指标奇怪? | |
| Revealing the Proximate Long-Tail Distribution in Compositional Zero-Shot Learning | AAAI 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| A Dynamic Learning Method towards Realistic Compositional Zero-Shot Learning | AAAI 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| Continual Compositional Zero-Shot Learning | IJCAI 2024 | UT-Zappos & C-GQA | - | ||
| CSCNET: Class-Specified Cascaded Network for Compositional Zero-Shot Learning | ICASSP 2024 | MIT-States & C-GQA | CODE | 无代码 | |
| Learning Conditional Prompt for Compositional Zero-Shot Learning | ICME 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| PMGNet: Disentanglement and entanglement benefit mutually for compositional zero-shot learning | CVIU 2024 | UT-Zappos & C-GQA & VAW-CZSL | - | ||
| LVAR-CZSL: Learning Visual Attributes Representation for Compositional Zero-Shot Learning | TCSVT 2024 | MIT-States & UT-Zappos & C-GQA | CODE | 可参考 | |
| Agree to Disagree: Exploring Partial Semantic Consistency against Visual Deviation for Compositional Zero-Shot Learning | TCDS 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| Compositional Zero-Shot Learning using Multi-Branch Graph Convolution and Cross-layer Knowledge Sharing | PR 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| Visual primitives as words: Alignment and interaction for compositional zero-shot learning | PR 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| Mutual Balancing in State-Object Components for Compositional Zero-Shot Learning | PR 2024 | MIT-States & UT-Zappos & C-GQA | - | ||
| GIPCOL: Graph-Injected Soft Prompting for Compositional Zero-ShotLearning | WACV 2024 | MIT-States & UT-Zappos & C-GQA | CODE | 代码不可用 | |
| CAILA: Concept-Aware Intra-Layer Adapters for Compositional Zero-Shot Learning | WACV 2024 | MIT-States & UT-Zappos & C-GQA | - |
2023
| Title | Venue | Dataset | CODE | |
|---|---|---|---|---|
| Distilled Reverse Attention Network for Open-world Compositional Zero-Shot Learning | ICCV 2023 | MIT-States & UT-Zappos & C-GQA | - | |
| Hierarchical Visual Primitive Experts for Compositional Zero-Shot Learning | ICCV 2023 | MIT-States & C-GQA &VAW-CZSL | CODE | |
| Do Vision-Language Pretrained Models Learn Composable Primitive Concepts? | TMLR 2023 | MIT-States | CODE | |
| Reference-Limited Compositional Zero-Shot Learning | ICMR 2023 | RL-CZSL-ATTR & RL-CZSL-ACT | CODE | |
| Learning Conditional Attributes for Compositional Zero-Shot Learning | CVPR 2023 | MIT-States & UT-Zappos & C-GQA | CODE | |
| Learning Attention as Disentangler for Compositional Zero-shot Learning | CVPR 2023 | Clothing16K & UT-Zappos & C-GQA | CODE | |
| Decomposed Soft Prompt Guided Fusion Enhancing for Compositional Zero-Shot Learning | CVPR 2023 | MIT-States & UT-Zappos & C-GQA | CODE | |
| Learning to Compose Soft Prompts for Compositional Zero-Shot Learning | ICLR 2023 | MIT-States & UT-Zappos & C-GQA | CODE | |
| Compositional Zero-Shot Artistic Font Synthesis | IJCAI 2023 | SSAF & Fonts | CODE | |
| Hierarchical Prompt Learning for Compositional Zero-Shot Recognition | IJCAI 2023 | MIT-States & UT-Zappos & C-GQA | - | |
| Leveraging Sub-Class Discrimination for Compositional Zero-shot Learning | AAAI 2023 | UT-Zappos & C-GQA | CODE | |
| Dual-Stream Contrastive Learning for Compositional Zero-Shot Recognition | TMM 2023 | MIT-States & UT-Zappos | - | |
| Isolating Features of Object and Its State for Compositional Zero-Shot Learning | TETCI 2023 | MIT-States & UT-Zappos & C-GQA | - | |
| Learning Attention Propagation for Compositional Zero-Shot Learning | WACV 2023 | MIT-States & UT-Zappos & C-GQA | - |
2022
| Title | Venue | Dataset | CODE | |
|---|---|---|---|---|
| A Decomposable Causal View of Compositional Zero-Shot Learning | TMM 2022 | MIT-States & UT-Zappos | CODE | |
| KG-SP: Knowledge Guided Simple Primitives for Open World Compositional Zero-Shot Learning | CVPR 2022 | MIT-States & UT-Zappos & C-GQA | CODE | |
| Disentangling Visual Embeddings for Attributes and Objects | CVPR 2022 | MIT-States & UT-Zappos & VAW-CZSL | CODE | |
| Siamese Contrastive Embedding Network for Compositional Zero-Shot Learning | CVPR 2022 | MIT-States & UT-Zappos & C-GQA | CODE | |
| On Leveraging Variational Graph Embeddings for Open World Compositional Zero-Shot Learning | ACM MM 2022 | MIT-States & UT-Zappos & C-GQA | - | |
| 3D Compositional Zero-shot Learning with DeCompositional Consensus | ECCV 2022 | C-PartNet | CODE | |
| Learning Invariant Visual Representations for Compositional Zero-Shot Learning | ECCV 2022 | UT-Zappos & AO-CLEVr & Clothing16K | CODE | |
| Learning Graph Embeddings for Open World Compositional Zero-Shot Learning | TPAMI 2022 | MIT-States & UT-Zappos & C-GQA | - | |
| Bi-Modal Compositional Network for Feature Disentanglement | ICIP 2022 | MIT-States & UT-Zappos | - |
2021
| Title | Venue | Dataset | CODE | |
|---|---|---|---|---|
| Learning Graph Embeddings for Compositional Zero-Shot Learning | CVPR 2021 | MIT-States & UT-Zappos & C-GQA | CODE | |
| Open World Compositional Zero-Shot Learning | CVPR 2021 | MIT-States & UT-Zappos | CODE | |
| Independent Prototype Propagation for Zero-Shot Compositionality | NeurIPS 2021 | AO-Clevr & UT-Zappos | CODE | |
| Revisiting Visual Product for Compositional Zero-Shot Learning | NeurIPS 2021 | MIT-States & UT-Zappos & C-GQA | - | |
| Learning Single/Multi-Attribute of Object with Symmetry and Group | TPAMI 2021 | MIT-States & UT-Zappos | CODE | |
| Relation-aware Compositional Zero-shot Learning for Attribute-Object Pair Recognition | TMM 2021 | MIT-States & UT-Zappos | CODE | |
| A Contrastive Learning Approach for Compositional Zero-Shot Learning | ICMI 2021 | MIT-States & UT-Zappos & Fashion200k | - |
2020
| Title | Venue | Dataset | CODE | |
|---|---|---|---|---|
| Symmetry and Group in Attribute-Object Compositions | CVPR 2020 | MIT-States & UT-Zappos | CODE | |
| Learning Unseen Concepts via Hierarchical Decomposition and Composition | CVPR 2020 | MIT-States & UT-Zappos | - | |
| A causal view of compositional zero-shot recognition | NeurIPS 2020 | UT-Zappos & AO-Clevr | CODE | |
| Compositional Zero-Shot Learning via Fine-Grained Dense Feature Composition | NeurIPS 2020 | DFashion & AWA2 & CUB & SUN | CODE |
2019
| Title | Venue | Dataset | CODE | |
|---|---|---|---|---|
| Adversarial Fine-Grained Composition Learning for Unseen Attribute-Object Recognition | ICCV 2019 | MIT-States & UT-Zappos | - | |
| Task-Driven Modular Networks for Zero-Shot Compositional Learning | ICCV 2019 | MIT-States & UT-Zappos | CODE | |
| Recognizing Unseen Attribute-Object Pair with Generative Model | AAAI 2019 | MIT-States & UT-Zappos | - |
2018
| Title | Venue | Dataset | CODE | |
|---|---|---|---|---|
| Attributes as Operators: Factorizing Unseen Attribute-Object Compositions | CVPR 2018 | MIT-States & UT-Zappos | CODE |
2017
| Title | Venue | Dataset | CODE | |
|---|---|---|---|---|
| From Red Wine to Red Tomato: Composition with Context | CVPR 2017 | MIT-States & UT-Zappos | CODE |
Datasets
Most CZSL papers usually conduct experiments on MIT-States and UT-Zappos datasets. However, as CZSL receives more attention, some new datasets are proposed and used in recent papers, such as C-GQA, AO-CLEVr, etc.
MIT-States
Introduced by Isola et al. in Discovering States and Transformations in Image Collections.
The MIT-States dataset has 245 object classes, 115 attribute classes and ∼53K images. There is a wide range of objects (e.g., fish, persimmon, room) and attributes (e.g., mossy, deflated, dirty). On average, each object instance is modified by one of the 9 attributes it affords.
Source:http://web.mit.edu/phillipi/Public/states_and_transformations/index.html
UT-Zappos
Introduced by Yu et al. in Fine-Grained Visual Comparisons with Local Learning.
UT Zappos50K (UT-Zap50K) is a large shoe dataset consisting of 50,025 catalog images collected from Zappos.com. The images are divided into 4 major categories — shoes, sandals, slippers, and boots — followed by functional types and individual brands. The shoes are centered on a white background and pictured in the same orientation for convenient analysis.
Source:https://vision.cs.utexas.edu/projects/finegrained/utzap50k/
C-GQA
Introduced by Naeem et al. in Learning Graph Embeddings for Compositional Zero-shot Learning.
Compositional GQA (C-GQA) dataset is curated from the recent Stanford GQA dataset originally proposed for VQA. C-GQA includes 413 attribute classes and 674 object classes, contains over 9.5k compositional labels with diverse compositional classes and clean annotations, making it the most extensive dataset for CZSL.
Source:https://github.com/ExplainableML/czsl
AO-CLEVr
Introduced by Atzmon et al. in A causal view of compositional zero-shot recognition.
AO-CLEVr is a new synthetic-images dataset containing images of "easy" Attribute-Object categories, based on the CLEVr. AO-CLEVr has attribute-object pairs created from 8 attributes: { red, purple, yellow, blue, green, cyan, gray, brown } and 3 object shapes {sphere, cube, cylinder}, yielding 24 attribute-object pairs. Each pair consists of 7500 images. Each image has a single object that consists of the attribute-object pair. The object is randomly assigned one of two sizes (small/large), one of two materials (rubber/metallic), a random position, and random lightning according to CLEVr defaults.
Source:https://github.com/nv-research-israel/causal_comp
VAW-CZSL
Introduced by Nirat Saini et al. in Disentangling Visual Embeddings for Attributes and Objects.
VAW-CZSL, a subset of VAW, which is a multilabel attribute-object dataset. Sample one attribute per image, leading to much larger dataset in comparison to previous datasets. The images in the VAW dataset come from the Visual Genome dataset which is also the source of the images in the GQA and the VG-Phrasecut datasets.
Source:https://github.com/nirat1606/OADis.
Compositional PartNet
Introduced by Naeem et al. in 3D Compositional Zero-shot Learning with DeCompositional Consensus.
Compositional PartNet (C-PartNet) is refined from PartNet with a new labeling scheme that relates the compositional knowledge between objects by merging and renaming the repeated labels. The relabelled C-PartNet consists of 96 parts compared to 128 distinct part labels in the original PartNet.
Source:https://github.com/ferjad/3DCZSL
Results
Experimental results of some methods on the two most commonly-used datasets(MIT-States, UT-Zappos) and the most challenging dataset(C-GQA) are collected and presented.
All the results are obtained under the setting of Closed World Generalized Compositional Zero-Shot Learning. The current optimal metrics are in bold.
MIT-States
| Method | Seen | Unseen | HM | AUC |
|---|---|---|---|---|
| DECA | 32.2 | 27.4 | 20.3 | 6.6 |
| OADis | 31.1 | 25.6 | 18.9 | 5.9 |
| SCEN | 29.9 | 25.2 | 18.4 | 5.3 |
| CVGAE | 28.5 | 25.5 | 18.2 | 5.3 |
| Co-CGE | 31.1 | 5.8 | 6.4 | 1.1 |
| CGE | 32.8 | 28.0 | 21.4 | 6.5 |
| BMP-Net | 32.9 | 19.3 | 16.5 | 4.3 |
| CompCos | 25.3 | 24.6 | 16.4 | 4.5 |
| SymNet(CVPR) | 24.4 | 25.2 | 16.1 | 3.0 |
| SymNet(TPAMI) | 26.2 | 26.3 | 16.8 | 4.5 |
| HiDC | - | 15.4 | 15.0 | - |
| AdvFineGrained | - | 13.5 | 14.0 | - |
| TMN | 20.2 | 20.1 | 13.0 | 2.9 |
| GenModel | 24.8 | 13.4 | 11.2 | 2.3 |
| AttrAsOp | 14.3 | 17.4 | 9.9 | 1.6 |
| RedWine | 20.7 | 17.9 | 11.6 | 2.4 |
UT-Zappos
| Method | Seen | Unseen | HM | AUC |
|---|---|---|---|---|
| DECA | 64.0 | 68.8 | 51.7 | 37.0 |
| IVR(fixed) | 56.9 | 65.5 | 46.2 | 30.6 |
| OADis | 59.5 | 65.5 | 44.4 | 30.0 |
| SCEN | 63.5 | 63.1 | 47.8 | 32.0 |
| CVGAE | 65.0 | 62.4 | 49.8 | 34.6 |
| ProtoProp | 62.1 | 65.5 | 50.2 | 34.7 |
| Co-CGE | 62.0 | 44.3 | 40.3 | 23.1 |
| CGE | 64.5 | 71.5 | 60.5 | 33.5 |
| BMP-Net | 83.9 | 60.9 | 56.9 | 44.7 |
| CompCos | 59.8 | 62.5 | 43.1 | 28.7 |
| SymNet(TPAMI) | 10.3 | 56.3 | 24.1 | 26.8 |
| HiDC | - | 53.4 | 52.4 | - |
| CAUSAL | 39.7 | 26.6 | 31.8 | 23.3 |
| AdvFineGrained | - | 48.5 | 50.7 | - |
| TMN | 58.7 | 60.0 | 45.0 | 29.3 |
| AttrAsOp | 59.8 | 54.2 | 40.8 | 25.9 |
| RedWine | 57.3 | 62.3 | 41.0 | 27.1 |
C-GQA
| Method | Seen | Unseen | HM | AUC |
|---|---|---|---|---|
| SCEN | 28.9 | 25.4 | 17.5 | 5.5 |
| CVGAE | 28.2 | 11.9 | 13.9 | 2.8 |
| Co-CGE | 32.1 | 2.0 | 3.4 | 0.78 |
| CGE | 31.4 | 14.0 | 14.5 | 3.6 |
Acknowledgements
This page is made by Yanyi Zhang and Jianghao Li, both of whom are graduate students of Dalian University of Technology.


.png)