免责声明:本文章仅用于交流学习,因文章内容而产生的任何违法&未授权行为,与文章作者无关!!!
附:完整笔记目录~
ps:本人小白,笔记均在个人理解基础上整理,若有错误欢迎指正!
2.4 JS信息收集
- 引子:上一篇所介绍源码信息收集,主要针对目标站点不可见的后端源码进行收集,往往能收集到的概率小但危害较大。而本篇则介绍针对前后端分离&前端Web的JS的信息收集,由于源码本身可见,因此收集重点从源码转为源码中的敏感信息。
- 手工收集
一般测试者在进行信息收集时,往往会采用工具+手工的方式而非纯手工。而手工收集中最常用的收集方法,则为借助浏览器开发者工具(F12)搜索关键词。
这里列举一些可能会包含敏感信息的JS关键词:src= , path= ,$.ajax ...... - Burp插件收集
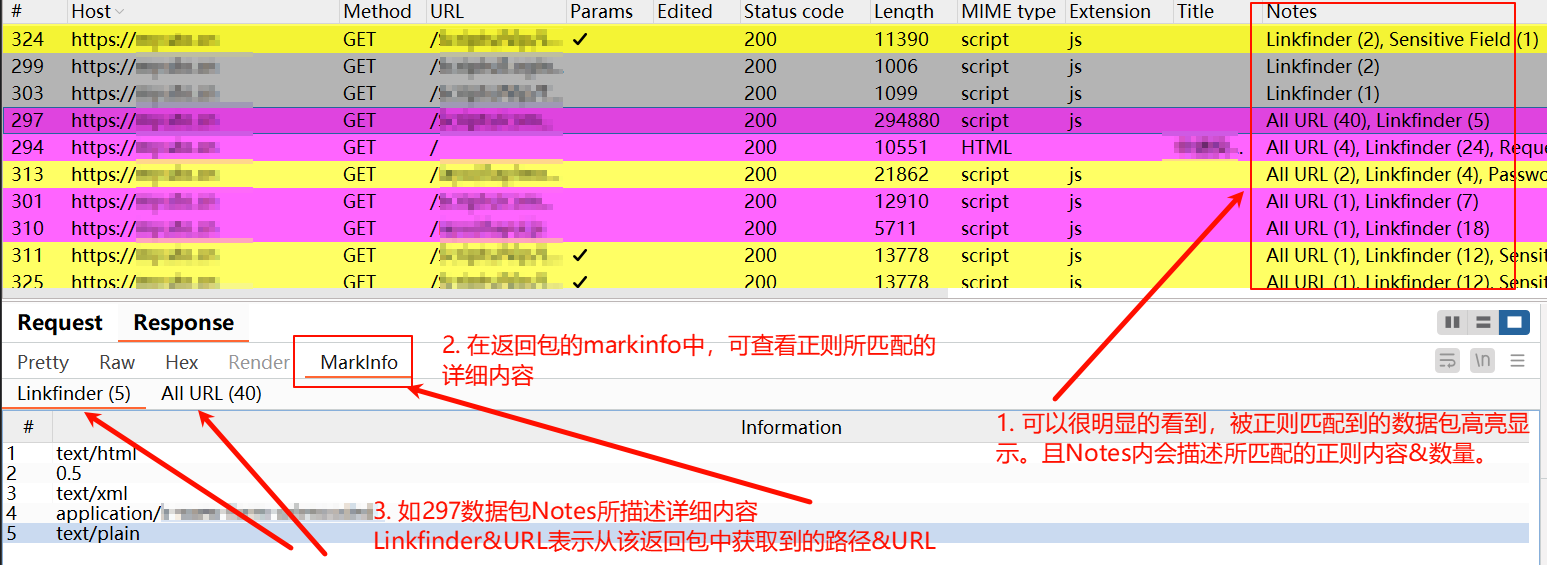
- HaE:https://github.com/gh0stkey/HaE
通过规则库正则匹配数据包中的敏感数据,并高亮展示匹配到的数据包。
以某通为例:
- BurpAPIFinder:https://github.com/shuanx/BurpAPIFinder
JS敏感信息匹配插件,且据作者说信息匹配除正则外还支持多种模式,集成了HaE、APIKit等敏感信息指纹等。
例子:
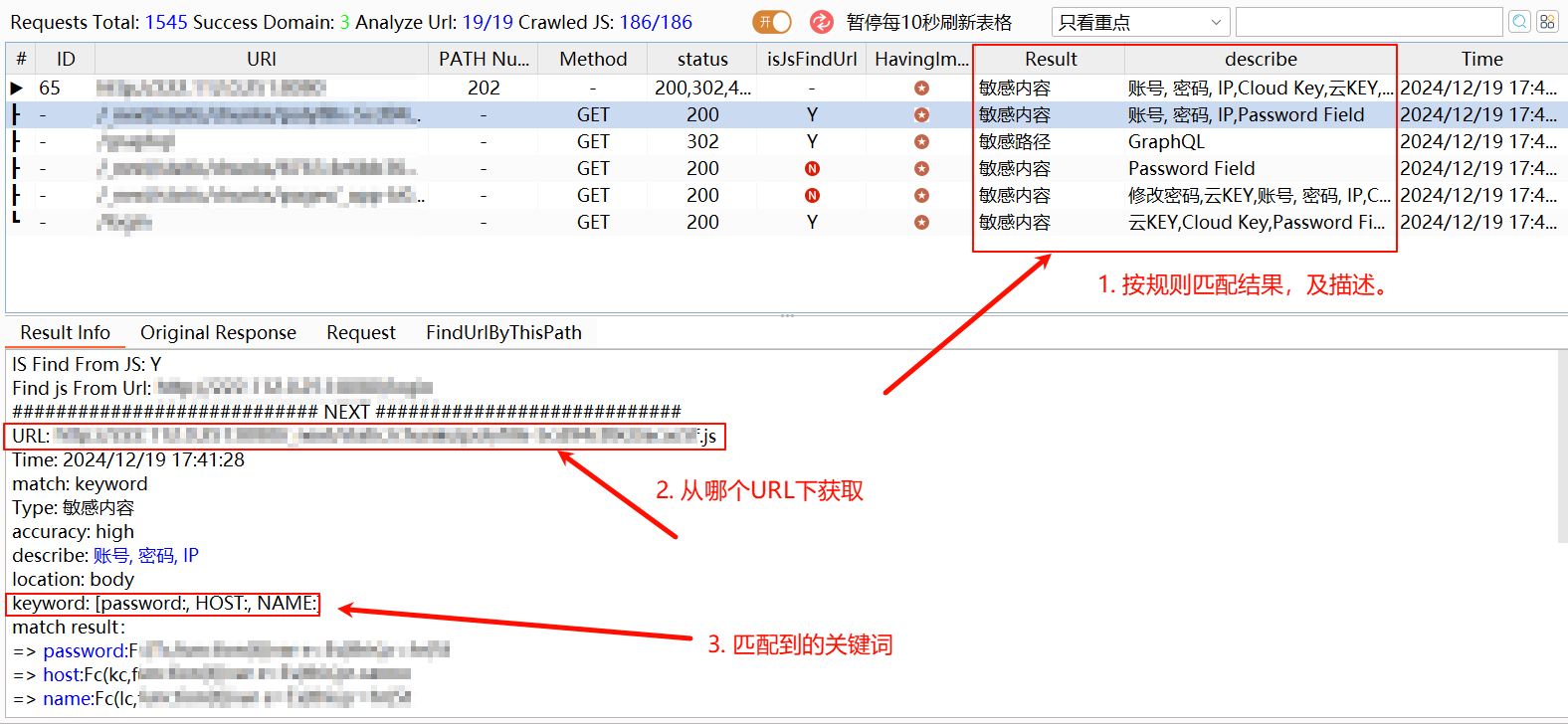
依据其配置文件规则匹配,听说该插件支持递归扫描、深入挖掘,因此能获取到更多的信息。不过缺点就是,扫描速度慢,刷新时内存占用高。
- HaE:https://github.com/gh0stkey/HaE
- 自动化工具收集
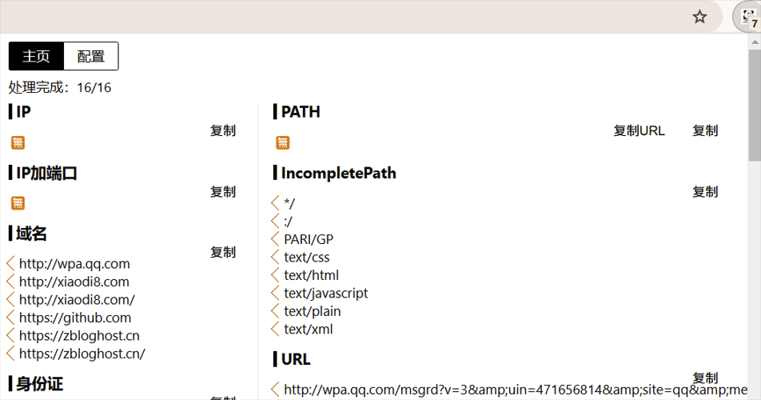
- 浏览器插件 → FindSomething
该插件会收集当前标签页源码&JS链接,并将收集到的JS链接再次加载以获取JS源码,随后从获取到的html&js源码中通过正则匹配其中的敏感信息并展示。
以xiaodi8为例:
- JSFinder:https://github.com/Threezh1/JSFinder
依据正则检索Web js文件中的URL、子域名等信息。引小迪的评价,“老牌蘸酱”。
例子:
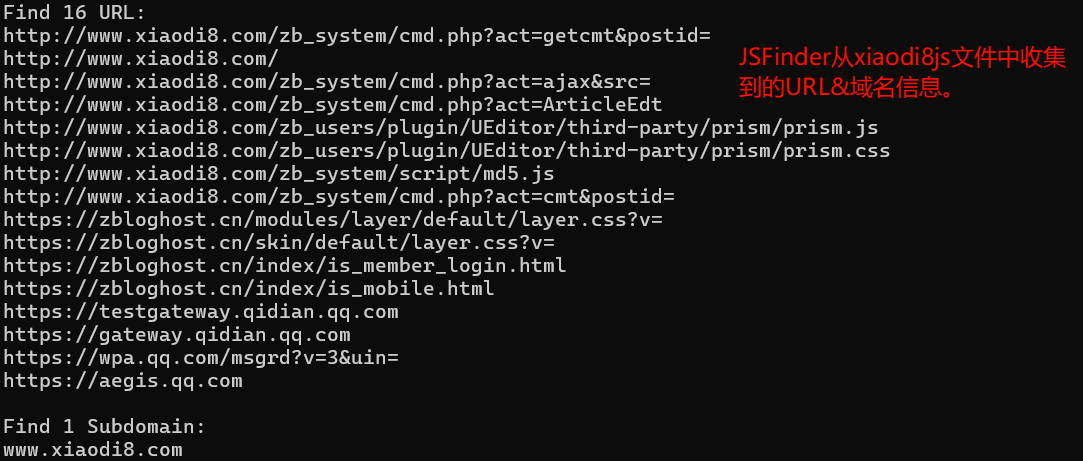
- URLFinder:https://github.com/pingc0y/URLFinder
作者说由于JSFinder项目长时间无人维护,因此自己写了一个。项目较新,检索速度快&内容多,对于自动化工具JS信息收集,更推荐该项目。
例子:

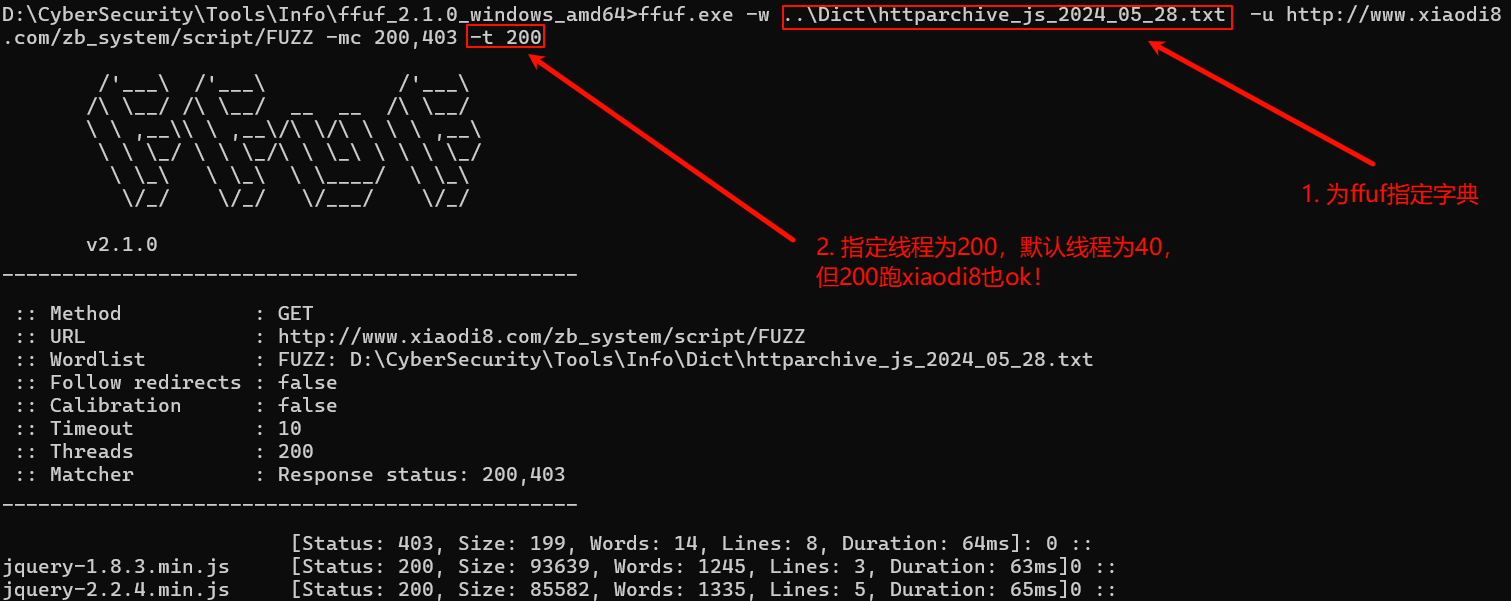
相较于JSFinder,使用URLFinder获取到的信息除URL&子域名外,还有各种经规则匹配的敏感信息。 - ffuf:https://github.com/ffuf/ffuf
上述所提到的各种JS敏感信息收集方式,正则、递归等,都是在被发送至浏览器上的JS文件基础进行。而ffuf不同,使用模糊测试的方法,通过大字典去跑目标Web可能存在的JS文件,主要针对部分JS文件可能存在但并未被发送至客户端的情况,从而获取更多信息。
其实就跟目录扫描差不多,只不过这里扫的全是js文件罢了。由于使用ffuf需要提前准备字典,so 这里分享一个字典站:https://wordlists.assetnote.io/
例子:
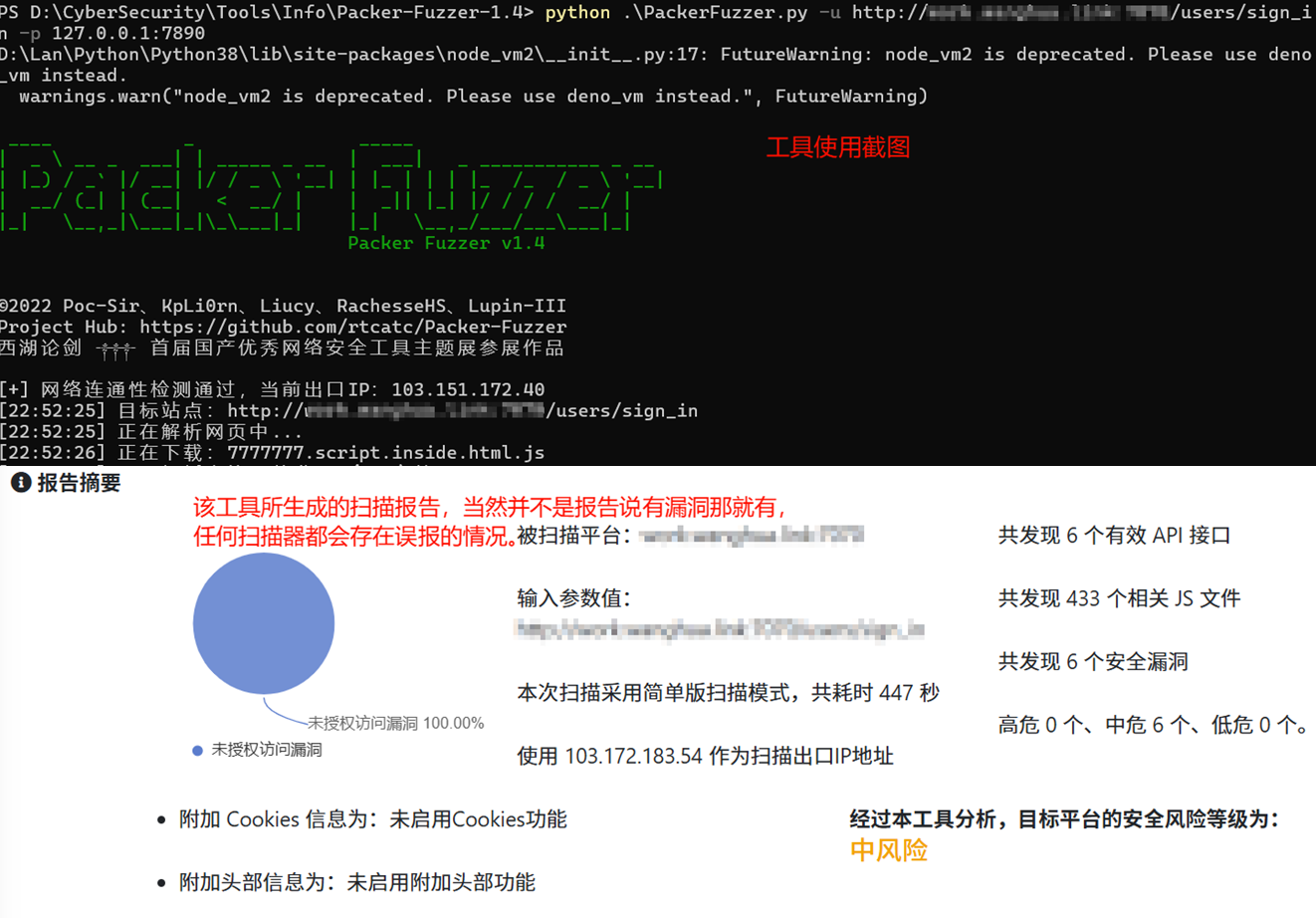
- Packer-Fuzzer:https://github.com/rtcatc/Packer-Fuzzer
由于WebPack会自动将打包后的JS代码进行混淆,导致上述JS信息收集方式收集到的信息不那么准确,因此针对WebPack站点,建议使用对口工具。
Packer-Fuzzer,主要目标为WebPack站点,针对被打包的JS文件进行敏感信息收集,且支持部分漏洞检测,扫描完成后会自动生成检测报告。
例子:
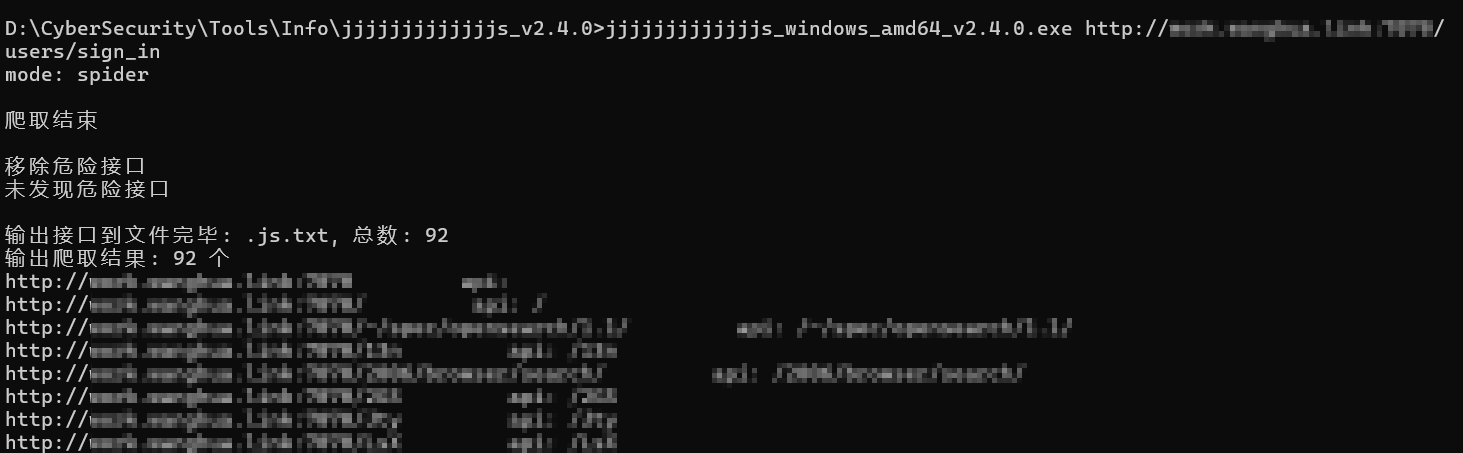
该项目会先将整个WebPack打包文件拖下来,再对拖下来的文件内容进行收集敏感信息,最后给出报告。因此实际中使用该工具跑一遍站点速度较慢。 - jjjjjjjjjjjjjs:https://github.com/ttstormxx/jjjjjjjjjjjjjs
针对WebPack站点的敏感信息收集工具。相较于Packer-Fuzzer,该项目仅匹配JS文件中的敏感信息,而不会拖取被打包文件,因此运行速度快。至于这两款工具还有什么优缺点,有用过的师傅可以聊一下🙏。
例子:
- 浏览器插件 → FindSomething
注:本文介绍了很多关于JS文件信息收集的工具,各个工具的功能或多或少都有些重复性。实际上,不必太纠结用哪款&那款好,我们的目标始终是解决问题而非工具选择。(ps:不要拿工具在网上乱扫哈,我们是禁止所有未授权测试的。)