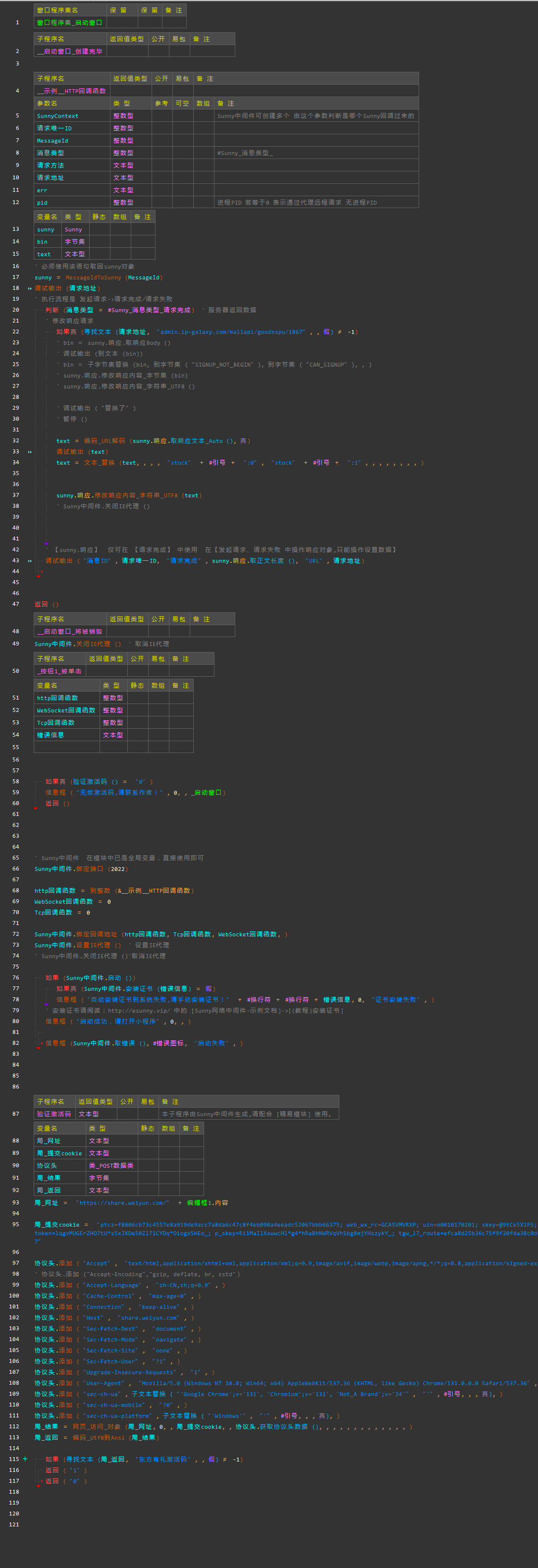
SI152: Numerical Optimization
Lec 1.
Optimization
Three elements of an optimization problem: Objective(目标), Variables(变量), Constraints(约束条件).
Classifacation:
- Linear Optimization v.s. Nonlinear Optimization
- Constrained Optimization v.s. Unconstrained Optimization
- Continuous Optimization v.s. Integer Optimization
- Stochastic Optimization v.s. Deterministic Optimization
- Convex Optimization v.s. Nonconvex Optimization
- Single-objective Optimization v.s. Multi-objective Optimization
- Bilevel Optimization v.s. Single-level Optimization
- Bilevel Optimization: \(F(x, y(x))\) is the objective function of the upper level problem, which depends on the solution \(y(x)\) of the lower level problem.
- Global Optimization v.s. Local Optimization
Equation \(\iff\) Optimization
Iterative algorithms: \(x_{k+1} = \mathcal{M} (x_k)\)
Generally, the sequence from iterative algorithms converges to an “optimal solution”.
- Globally convergent algorithm v.s. Locally convergent algorithm
Convergence rates
For sequence \(\{x_k\}\) converges to \(x^*\).
Q-linear convergence: If there exists a constant \(c \in [0,1)\) and \(\hat{k}\geq 0\) such that
then \(\{x_k\}\) converges Q-linearly to \(x^*\).
- i.e.
- also called geometric convergence.
Q-superlinear convergence: If there exists a sequence \(\{c_k\} \to 0\) such that
then \(\{x_k\}\) converges Q-superlinearly to \(x^*\).
- i.e.
Q-quadratic convergence: If there exists a constant \(c \geq 0\) and \(\hat{k}\geq 0\) such that
then \(\{x_k\}\) converges Q-linearly to \(x^*\).
“R-” convergence: skipped. So we’ll drop the “Q-”.
Sublinear convergence (Arithmetic Convergence): If the sequence \(\{r_k\}\) converges to \(r^*\) in such a way that
where \(C\) is a fixed positive number, the sequence is said to converge arithmetically to \(r^∗\) with order \(p\).
- i.e.
Lec 2.
Linear equations
Solution:
- Direct methods: Gaussian elimination
- Iterative methods
- Conjugate gradient method
The Jacobi Iteration Method
For \(n \times n\) linear system \(Ax=b\), let solution be \(x^*\):
Let \(A=L+D+U\)
Trasform \((D+L+U)x=b\) into:
So Jacobi iterative technique (Matrix form):
(Elementwisely form):
Convergence:
So $||M||<1 \implies \text{linear convergence} $ , \(||M||\) is spectral norm(谱范数) of \(M\).
Weighted Jacobi method (1):
Weighted Jacobi method (2):
Gauss-Seidel Method
(Matrix form):
- Often converges faster than Jacobi.
- Still depends on the spectral radius but with improved convergence
Nonlinear equations
Nonlinear equation \(f(x)=0\), solution is \(x_*\).
Definition
A function \(G\) is Lipschitz continuous with constant \(L \geq 0\) in \(\mathcal{X}\) if
Bisection Method
In use of Intermediate Value Theorem:
If \(f(x)\) is continuous on \([a, b]\) and \(f(a) \cdot f(b) < 0\), then \(\exist c\in (a, b) , f(c) = 0\).
Newton’s method
From:
Then:
Quadratic convergence:
Let \(e_k = x_k - x_*\)
Problem of Newton’s method
- May cause cycling and even divergence. (\(f(x) = \arctan(x)\))
- May have \(f'(x_k) = 0\). (\(f(x) = x^3\))
- \(f(x_k)\) may be undefined.
Secant method
Change tangent into secant:
Superline convergence:
Let \(e_k = x_k - x_*\), \(M=\dfrac{f''(x_*)}{2f'(x_*)}\)
If \(|e_{k+1}|\approx C|e_k|^p\), then
So we can get:
Newton’s method for multivariable
Suppose we have $F: \mathbb{R}^m \mapsto \mathbb{R}^n $ and solve \(F(x) = 0\).
Then
Quadratical convergence:
Newton's method converges quadratically! (under nice assumptions)
- \(F\) is continuously differentiable in an open convex set \(\mathcal{X}\subset\mathbb{R}^n\) with $ x_* \in\mathcal{X} $.
- The Jacobian of \(F\) at \(x_*\) is invertible and is bounded in norm by \(M > 0\), i.e.,\[\lVert \nabla F(x_*)^{-T} \rVert _2 \leq M \]
- If \(M\) is large, then following the gradient may send us far away.
- For some neighborhood of \(x_∗\) with radius \(r > 0\) contained in \(\mathcal{X}\), i.e.,
the Jacobian of F(x) is Lipschitz continuous with constant \(L\) in \(\mathbb{B}(x_∗, r)\).
- If \(L\) is large, then the gradients of the functions change rapidly.
Equations and Optimization
Linear
Nonlinear
- Nonlinear equation \(\implies\) Optimization
- \(F(x) = 0 \implies \min_{x\in\mathbb{R}} f(x) := \frac{1}{2}\lVert F(x) \rVert _2^2\)
- However, we generally do not prefer solve the latter, since\[ \nabla f(x) = F(x)^T \nabla F(x), \nabla^2 f(x) = \nabla F(x)^T \nabla F(x) \]
- Optimization \(\implies\) Nonlinear equation
- For any \(C^1\)-smooth,\[\min_{x\in\mathbb{R}} f(x) \iff \nabla f(x) = 0 \]
- For any \(C^1\)-smooth,