关于分布式锁的的思考
结论先行:
对于分布式锁我们在考虑不同方案的时候需要先思考需要的效果是什么?
-
为了效率(efficiency),协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其它的不良后果。比如重复发送了一封同样的 email(当然这取决于业务应用的容忍度)。
-
为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,订单重复,超卖或者其它严重的问题。
方案选型:
- 基于
ZooKeeper|Chubby 的分布式锁,适用于高可靠(高可用)而并发量不是太大的场景; - 基于
Redis 的分布式锁,适用于并发量很大、性能要求很高的、而可靠性问题可以通过其他方案去弥补的场景。 - 基于
MySQL 的分布式锁一般均有单点问题,高并发场景下对数据库的压力比较大;
通常来说如果是为了效率,那么我们使用单机的REDIS实现的分布式锁即可(REDLOCK方案太重了,而且并没有正确性保证不推荐,后面会说明)。
如果是为了正确性,那么我们应该考虑zk,Chubby等方案。
提到不建议使用REDLOCK方案,原因是REDLOCK方案不可靠且“重” ,显得“不伦不类”,其不可靠的关键在于:
-
数据丢失:REDIS的单个节点并不能保证数据不丢失,因此集群更不能保证数据不丢失,那么就算拿到了REDLOCK,实际上也是只能是大部分保证。除非有如下配置:
- 持久化配置中设置
fsync=always,性能大大降低 - 恰当的运维,把崩溃节点进行延迟重启,超过崩溃前所有锁的 TTL 时间之后才加入 Redlock 节点组。(这样重启之后原来拿到的分布式锁已经过期了)
- 持久化配置中设置
-
其它:由于REDIS过期时间是依赖系统时钟的,而且是可修改的那一种。因此出现时钟漂移的情况下就会出现问题。linux的两个系统时间[1]
在几乎没有收益的情况下,带来运维和操作极大的复杂性,显然没有必要。
而不用REDLOCK的话单机REDIS也可以保证”大部分“情况下没问题,这样的话还不如使用单机REDIS,就像DDIA的作者Martin评价REDLOCK为neither fish nor fowl (不伦不类)。
补充问题
分布式锁方案的其他补充
分布式锁相比于单机锁要考虑的问题:
- 互斥(Mutual Exclusion), 这是锁最基本的功能,同一时刻只能有一个客户端持有锁;
- 避免死锁(Dead lock free), 如果某个客户端获得锁之后花了太长时间处理,或者客户端发生了故障,锁无法释放会导致整个处理流程无法进行下去,所以要避免死锁。最常见的是通过设置一个 TTL(Time To Live,存活时间) 来避免死锁。
- 容错(Fault tolerance), 为避免单点故障,锁服务需要具有一定容错性。大体有两种容错方式,一种是锁服务本身是一个集群, 能够自动故障切换(ZooKeeper、etcd);另一种是客户端向多个独立的锁服务发起请求,其中某个锁服务故障时仍然可以从其他锁服务读取到锁信息(Redlock),代价是一个客户端要获取多把锁, 并且要求每台机器的时钟都是一样的,否则 TTL 会不一致,可能有的机器会提前释放锁,有的机器会太晚释放锁,导致出现问题。
单机MySQL实现分布式锁的方式
单机MySQL设计分布式锁相比于REDIS,其它的设计考虑点基本类似(解锁必须是加锁客户端),但是需要额外考虑锁的释放的问题,原因在于MySQL并没有REDIS这样的定期删除的机制。
解决方案也很简单,可以考虑在MySQL维护分布式锁的表中增加一个字段,标注当前锁持有的默认有效期,当默认有效期过了,其它节点就可以尝试拿锁了。
所有分布式锁都需要考虑的fencing机制
fencing机制是什么?请看下图中存在的分布式锁的重复加锁引发的强占问题。
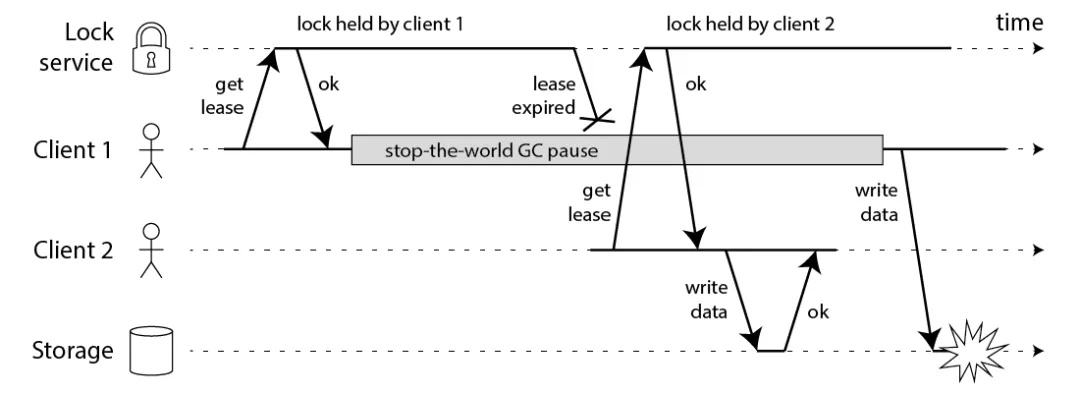 图中client1拿到锁之后,由于停机了一段时间,导致锁过期(无论哪一种分布式锁的实现,为了保证不死锁,在客户端停止响应一段时间之后都会释放锁,无论以哪种方式释放)。这时候client2拿到锁,client2拿到锁之后,client1恢复了。这时候client1和clinet2都以为自己拿到了分布式锁!
图中client1拿到锁之后,由于停机了一段时间,导致锁过期(无论哪一种分布式锁的实现,为了保证不死锁,在客户端停止响应一段时间之后都会释放锁,无论以哪种方式释放)。这时候client2拿到锁,client2拿到锁之后,client1恢复了。这时候client1和clinet2都以为自己拿到了分布式锁!
一个最简单的误区就是让client1在操作数据之前再去确认自己是不是拿到锁了,这样是不行的,因为client1确认锁 与 操作数据 不是原子的,这期间仍有可能发生上面提到的宕机等问题。
解决方案就是fencing token机制:
那怎么解决这个问题呢?Martin 给出了一种方法,称为 fencing token。fencing token 是一个单调递增的数字, 当客户端成功获取锁的时候它随同锁一起返回给客户端。而客户端访问共享资源的时候带着这个 fencing token,这样提供共享资源的服务就能根据它进行检查,拒绝掉延迟到来的访问请求(避免了冲突)。如下图:

在上图中,客户端 1 先获取到的锁,因此有一个较小的 fencing token,等于 33,而客户端 2 后获取到的锁,有一个较大的 fencing token,等于 34。客户端 1 从 GC pause 中恢复过来之后,依然是向存储服务发送访问请求,但是带了 fencing token = 33。存储服务发现它之前已经处理过 34 的请求,所以会拒绝掉这次 33 的请求。这样就避免了冲突。
说白了,需要存储服务提供一些额外的类似于版本号识别的能力,感觉用的很少。
这也许说明实际上使用zk这样的分布式锁方案也只是”尽全力“保证不重复加锁,或者说现实中出现这样的问题的时候太少了,如果为了这个而设计一套复杂的机制是不是过于复杂设计了。
WAIT 命令能够为 Redis 实现强一致吗?
结论:WAIT 不能保证 Redis 的强一致性。
WAIT numreplicas timeout:
- numreplicas: 指定副本(slave)的数量。
- timeout: 超时时间,时间单位为毫秒;当设置为 0 时,表示无限等待,即用不超时。
WAIT 命令作用:WAIT 命令阻塞当前客户端,直到所有先前的写入命令成功传输,并且由至少指定数量的副本(slave)确认。在主从、sentinel 和 Redis 群集故障转移中, WAIT 能够增强(仅仅是增强,但不是保证) 数据的安全性。
官方文档:https://redis.io/commands/wait
zk实现分布式锁的方式
zk实现分布式锁可以采用 临时顺序节点(EPHEMERAL_SEQUENTIAL) 或者 永久节点。
1.临时顺序节点实现分布式锁:
顾名思义,临时顺序节点结合和临时节点和顺序节点的特点:在创建节点时,ZooKeeper 根据创建的时间顺序给该节点名称进行编号;当创建节点的客户端与 ZooKeeper 断开连接后,临时节点会被删除。
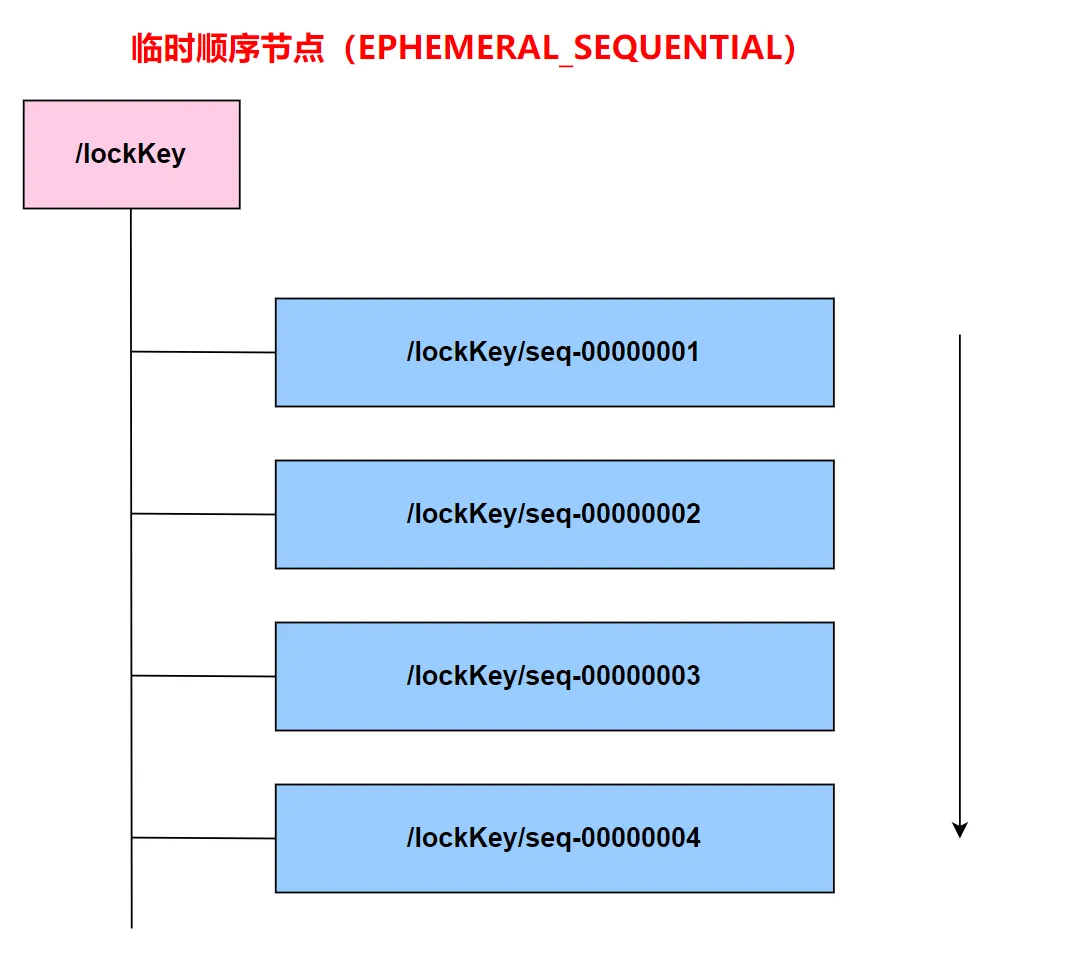 加锁就是创建第一个临时节点,解锁就是删除对应的临时节点。
加锁就是创建第一个临时节点,解锁就是删除对应的临时节点。
对于客户端宕机的情况,zk会在断联之后删除掉临时结点的值,可以通过后续节点监听这第一个临时节点的变化来获得。
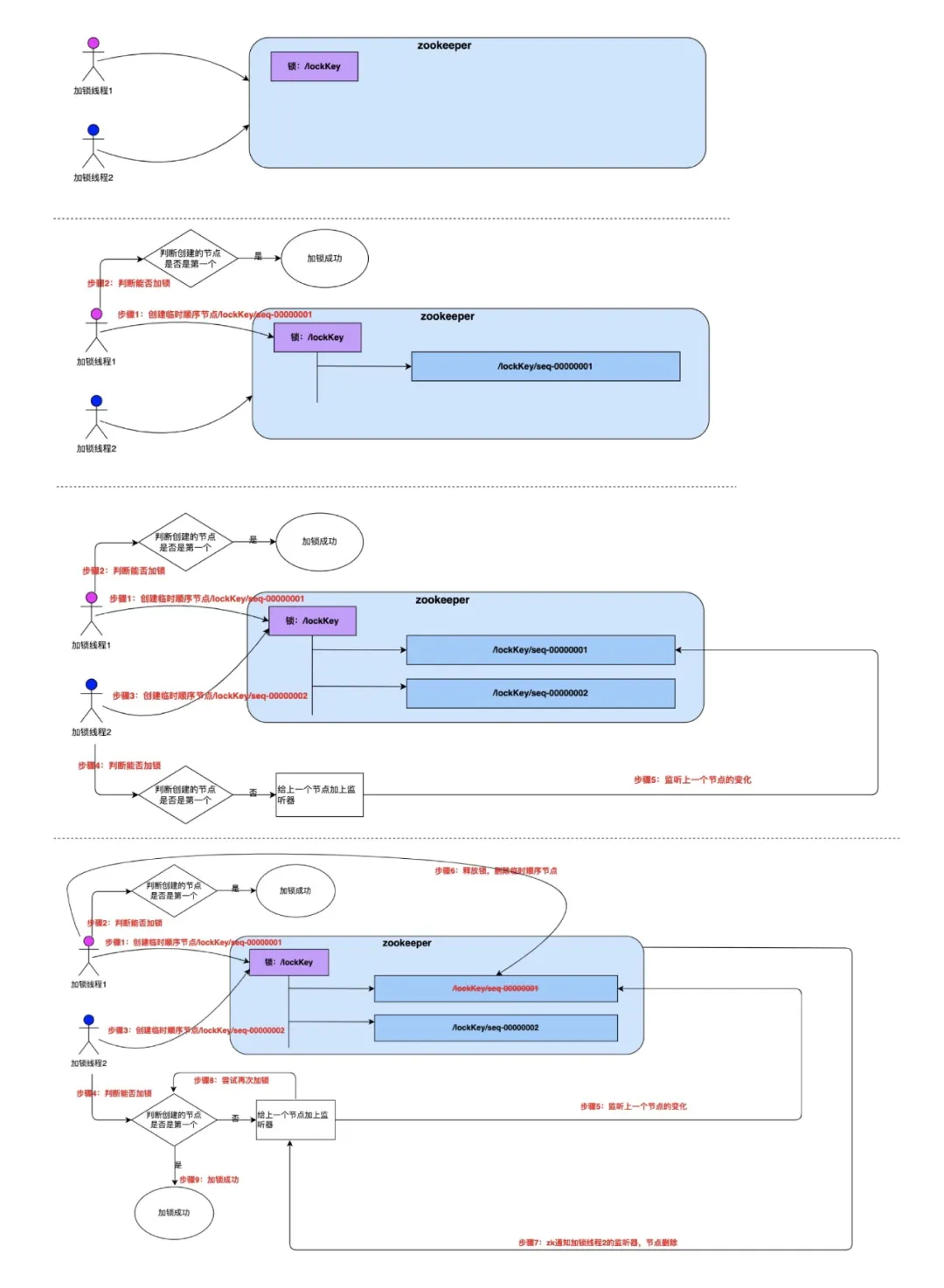
补充:惊群效应:错误的实现——如果实现 ZooKeeper 分布式锁的时候,所有后加入的节点都监听最小的节点。那么删除节点的时候,所有客户端都会被唤醒,这个时候由于通知的客户端很多,通知操作会造成 ZooKeeper 性能突然下降,这样会影响 ZooKeeper 的使用。
2.使用永久节点作为分布式锁的实现,本质上可以看成把zk当成了一个单机MySQL实现分布式锁的用法。
chubby是什么?
Chubby 是 Google 内部使用的分布式锁服务,有点类似于 ZooKeeper,但也存在很多差异。Chubby 对外公开的资料,主要是一篇论文,叫做“The Chubby lock service for loosely-coupled distributed systems”。
chubby有点类似于zookeeper,但是也存在很多差异。
比如说,chubby缓解上面提到的所有分布式锁都需要考虑的fencing机制提供了一些方案:CheckSequencer()检查与上次最新的 sequencer 对比、lock-delay,它们对于安全性的保证是从强到弱的。而且,这些处理方式本身都没有保证提供绝对的正确性(correctness)。 但是确实比没有提供多了一些保证。
具体来说:
sequencer:Chubby 给出的用于解决(缓解)这一问题的机制称为 sequencer,类似于 fencing token 机制。锁的持有者可以随时请求一个 sequencer,这是一个字节串,它由三部分组成:
- 锁的名字。
- 锁的获取模式(排他锁还是共享锁)。
- lock generation number(一个 64bit 的单调递增数字)。作用相当于 fencing token 或 epoch number。
客户端拿到 sequencer 之后,在操作资源的时候把它传给资源服务器。然后,资源服务器负责对 sequencer 的有效性进行检查。检查可以有两种方式:
- 调用 Chubby 提供的 API,CheckSequencer(),将整个 sequencer 传进去进行检查。这个检查是为了保证客户端持有的锁在进行资源访问的时候仍然有效。
- 将客户端传来的 sequencer 与资源服务器当前观察到的最新的 sequencer 进行对比检查。 可以理解为与 Martin 描述的对于 fencing token 的检查类似。
lock-delay(锁延期机制): 当然,如果由于兼容的原因,资源服务本身不容易修改,那么 Chubby 还提供了一种机制:Chubby 允许客户端为持有的锁指定一个 lock-delay 的时间值(默认是 1 分钟)。
当 Chubby 发现客户端被动失去联系的时候,并不会立即释放锁,而是会在 lock-delay 指定的时间内阻止其它客户端获得这个锁。这是为了在把锁分配给新的客户端之前,让之前持有锁的客户端有充分的时间把请求队列排空(draining the queue),尽量防止出现延迟到达的未处理请求。
参考:
字节文章-聊聊分布式锁 (主要参考,原文还有很多细节讨论,比如:时钟变迁对分布式锁的影响)
linux的两个系统时间
先简单说下系统时间,linux 提供了两个系统时间:clock realtime 和 clock monotonic
-
clock realtime 也就是 xtime/wall time,这个时间是可以被用户改变的,被 NTP 改变。Redis 的判断超时使用的 gettimeofday 函数取的就是这个时间,Redis 的过期计算用的也是这个时间。参考https://blog.habets.se/2010/09/gettimeofday-should-never-be-used-to-measure-time.html -
clock monotonic,直译过来是单调时间,不会被用户改变,但是会被 NTP 改变。
最理想的情况是:所有系统的时钟都时时刻刻和 NTP 服务器保持同步,但这显然是不可能的。
clock realtime 可以被人为修改,在实现分布式锁时,不应该使用 clock realtime。
很可惜,Redis 使用的就是这个时间,Redis 5.0 使用的还是 clock realtime。Antirez 说过后面会改成 clock monotonic 的。也就是说,人为修改 Redis 服务器的时间,就能让 Redis 出问题了。 ↩︎
-