目录
1.静态训练与动态训练
1.1 如何选择训练方式?
2.静态与动态推理
2.1 离线推理的优缺点
2.2 在线推理的优缺点
3.数据依赖性
3.1 可靠性
3.2 版本控制
3.3 必要性
3.4 相关性
3.5 反馈回路
4.参考文献
到目前为止,【机器学习1~20】所述内容都是围绕构建 ML 模型展开的。然而,如下图所示,现实世界的生产机器学习系统是大型生态系统,模型只是其中的一部分(更准确地说,是很小的一部分)。
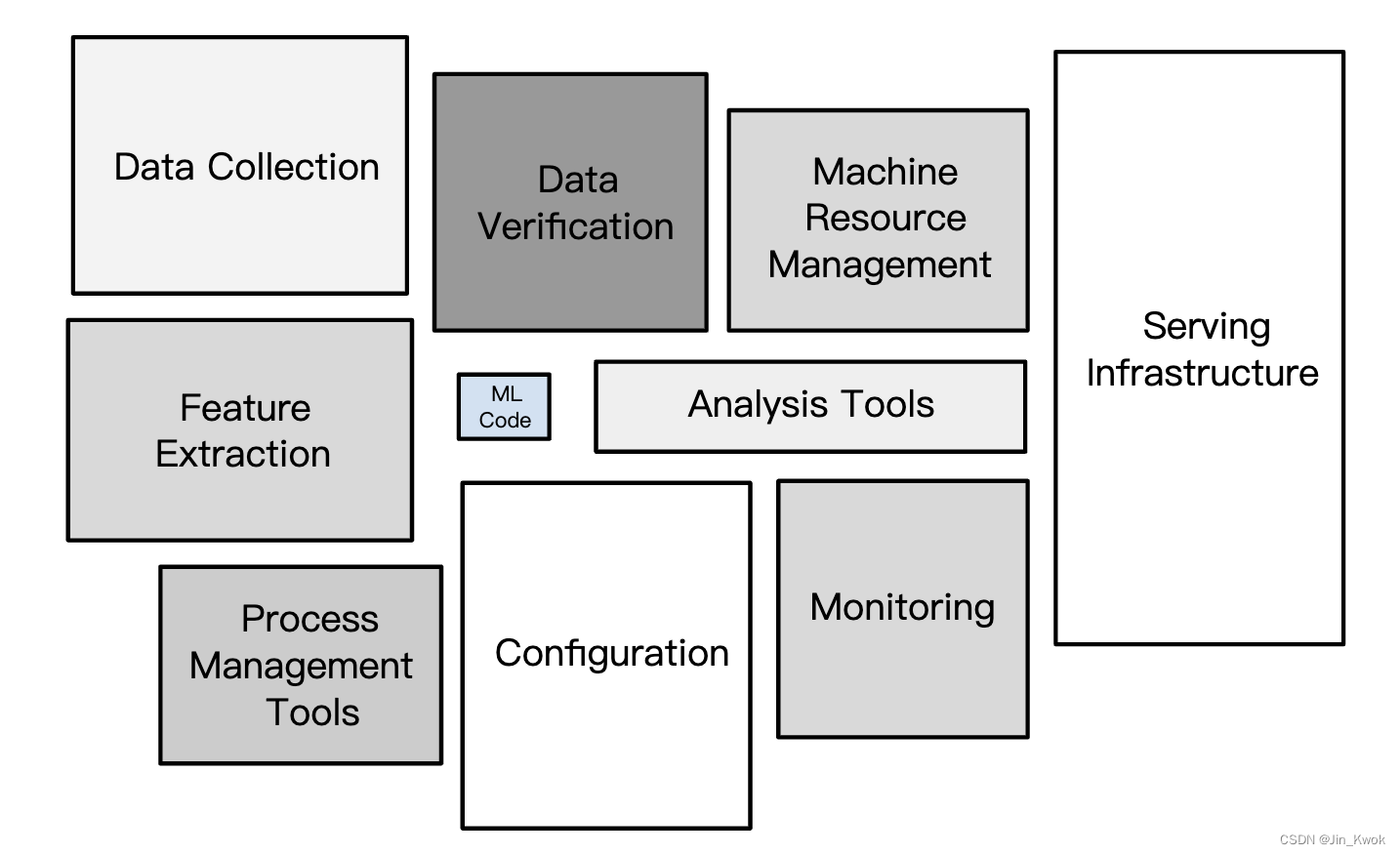
图 1. 实际生产机器学习系统
ML 代码是现实世界 ML 生产系统的核心,但该框通常仅占整个 ML 生产系统整体代码的 5% 或更少。在实际应用中,机器学习生产系统需投入大量资源来输入数据——收集数据、验证数据并从中提取特征。此外,服务基础设施必须到位,才能将 ML 模型的预测付诸现实世界的实际应用。
幸运的是,上图中的许多组件都是可重用的,同时,我们不必自己构建图 1 中的所有组件。
TensorFlow Extended (TFX) 是一个用于部署生产 ML 管道的端到端平台。在后续的文章中,笔者将继续解读构建生产机器学习系统的设计决策。
1.静态训练与动态训练
一般来说,训练模型有两种方法:
- 静态模型:一般是离线训练的,换言之,我们只训练模型一次,然后在一段时间内使用经过训练的模型。
- 动态模型:在训练模型时,数据不断进入系统,我们通过不断地更新将这些数据合并到模型中。
1.1 如何选择训练方式?
一般来说,以下几点主导着静态与动态训练决策:
- 静态模型更容易构建和测试。
- 动态模型适应不断变化的数据。现实世界通常是不断变化的,比如根据去年的数据建立的销售预测不太可能成功预测明年的结果。
如果你的数据集确实不随时间变化,那么,选择静态训练即可,因为它的创建和维护成本比动态训练便宜。然而,许多信息源确实会随着时间的推移而发生变化,即使是那些你认为像海平面一样恒定的特征,它们可能也在缓慢变化。在实践中,即使进行静态训练,仍然必须监控输入数据的变化,以便及时发现。
例如,假设有一个经过训练来预测用户购买鲜花的概率的模型。由于时间压力,该模型仅使用七月和八月的鲜花购买行为数据集进行一次训练。然后该模型被发送出去以在生产中提供预测服务, 但从不更新。 该模型在几个月内运行良好,但随后在 情人节前 后做出了糟糕的预测,因为该假期期间的用户行为发生了巨大变化。
2.静态与动态推理
与模型训练方法类似,推理策略也可分为动态推理(也称为在线推理)和静态推理(也称为离线推理)两种,定义如下:
- 离线推理,意味着使用 MapReduce 或类似的工具批量进行所有可能的预测。然后,将预测写入 SSTable 或 Bigtable,然后将它们提供给缓存/查找表。
- 在线推理,意味着使用服务器按需预测,即以服务的形式对外,调用方可通过调用服务获取推理结果。例如京东、拼多多等电商平台的商品推荐,抖音、快手等平台的视频内容推荐,本质上都是在线推理。
2.1 离线推理的优缺点
- 优点:不需要太担心推理成本,整体成本较低。
- 优点:可以使用批量配额或一些巨型 MapReduce。
- 优点:可以在推送之前对预测进行验证。
- 缺点:只能预测我们所知道的事情——不利于长尾。
- 缺点:更新延迟可能以小时或天为单位来衡量。
2.2 在线推理的优缺点
- 优点:可以对任何新产品的出现做出预测——非常适合长尾。
- 缺点:计算密集、延迟敏感——可能会限制模型的复杂性。
- 缺点:监控需求更加密集。
3.数据依赖性
数据对于机器学习开发人员来说就像代码对于传统程序员一样重要。
机器学习系统的行为取决于其 输入特征 的行为和质量。随着这些特征的输入数据发生变化,模型也会发生变化。有时这种改变是可取的,但有时则不然。
在传统的软件开发中,工程师更关注代码而不是数据。在机器学习开发中,尽管编码仍然是工作的一部分,但重点必须扩大到包括数据。例如,在传统的软件开发项目中,最佳实践是编写单元测试来验证代码。在 ML 项目中,工程师还必须不断测试、验证和监控输入数据。
例如,持续监控模型以删除未使用(或很少使用)的特征。想象一下某个特征对模型贡献很少或没有贡献。如果该特征的输入数据突然发生变化,则模型的行为也可能会以不良方式突然发生变化。
3.1 可靠性
关于输入数据的可靠性,在实践中,我们可以通过一些问题来检验:
- 信号是否始终可用,还是来自不可靠的来源?例如:
- 信号是否来自在高负载、即将崩溃的服务器?——不稳定
- 信号是否来自每年八月去度假的人群?——不可靠
3.2 版本控制
有关版本控制的一些问题:
- 计算这些数据的系统会改变吗?如果会改变,那么:
- 变化的频率如何?
- 如何知道该系统何时发生变化?
有时,数据来自上游系统。如果上游系统(或上游处理流程)突然发生变化,模型可能会受到影响。因此,通常可以创建从上游流程收到的数据的副本,然后,仅在确定安全时才更新到上游数据的下一个版本。
3.3 必要性
根据正则化(【机器学习10:正则化-Regularization】和【机器学习14:稀疏性-Sparsity】)的解释,我们知道——模型的输入特征并非越多越好。对于任何一个特征,我们必须明确如下问题:
- 该特征的实用性是否证明了包含该特征的成本是合理的?
向模型添加更多特征总是很诱人。例如,假设我们发现一个新特征,添加该特征可以使模型稍微更准确。更高的准确度听起来肯定比更低的准确度更好。然而,增加特征会增加维护成本——因为该特征可能会意外降级,因此必须对其进行监控。在添加可带来短期小收益的特征之前应仔细权衡。
3.4 相关性
某些特征与其他特征相关(正相关或负相关)。问自己以下问题:
- 是否有任何特征如此紧密地联系在一起,以至于需要额外的策略来将它们分开?
3.5 反馈回路
有时模型会影响它自己的训练数据。例如,某些模型的结果又是同一模型的直接或间接输入特征。有时一个模型可以影响另一个模型。例如,考虑两个预测股票价格的模型:
- 模型 A(一个糟糕的预测模型)
- 模型 B
由于模型 A 有问题,它错误地决定购买股票 X 的股票,而这些购买推高了股票 X 的价格。模型 B 使用股票 X 的价格作为输入特征,因此模型 B 很容易得出一些错误的结论:股票 X 股票的价值。因此,模型 B 可以根据模型 A 的错误行为购买或出售股票 X 的股票。模型 B 的行为反过来又会影响模型 A,可能引发郁金香狂热或 X 公司 股票下跌。
4.参考文献
链接-https://developers.google.cn/machine-learning/crash-course/production-ml-systems