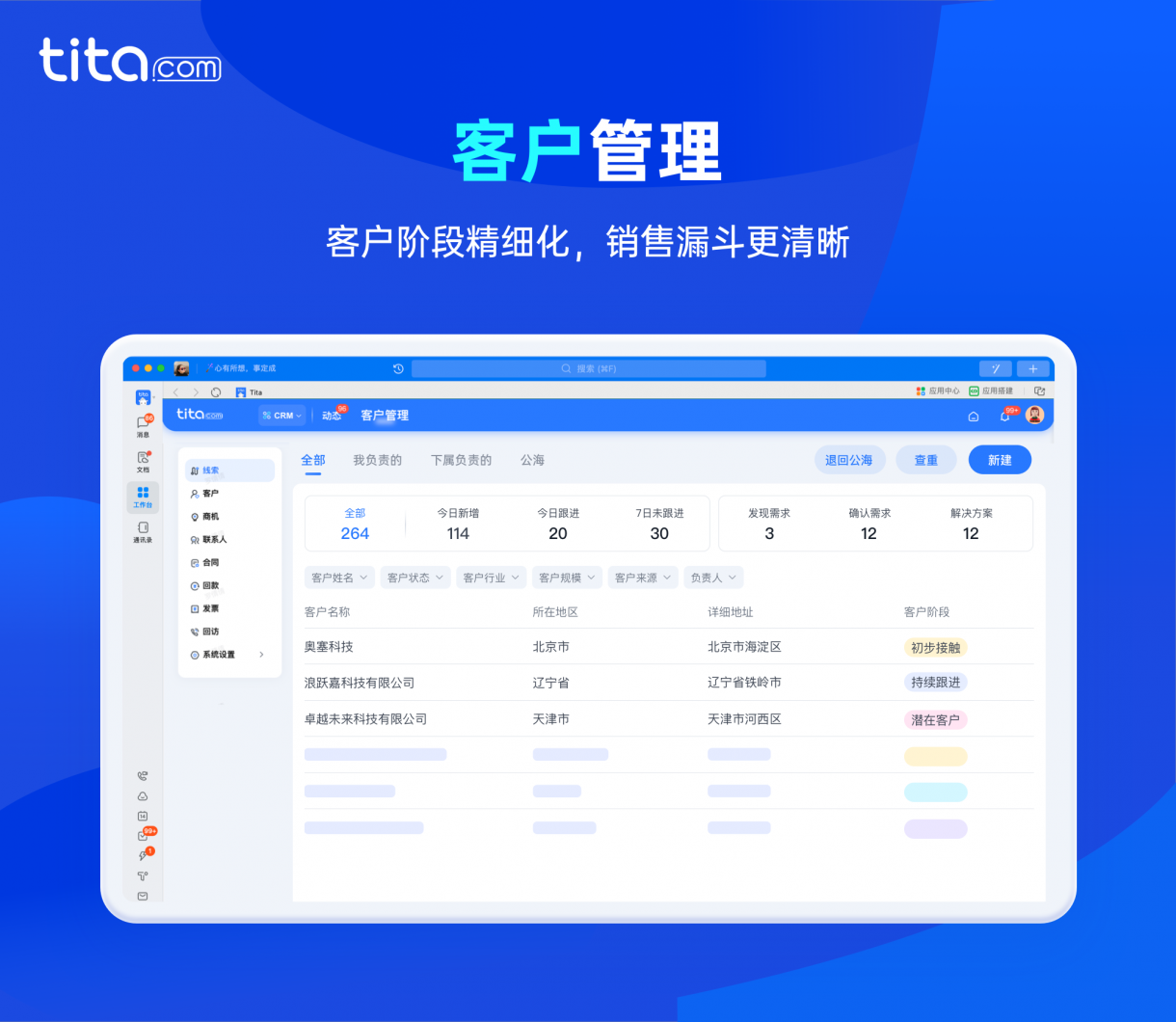
按照 dotnet 的惯例,先使用 NuGet 安装大佬封装好的 ICU 库,我这里选择的是 icu.net 库和 Microsoft.ICU.ICU4C.Runtime 库。其中 icu.net 库提供 ICU 的 dotnet 层封装,让咱上层 C# 代码可以方便调用。而 Microsoft.ICU.ICU4C.Runtime 库则提供非托管的 dll 依赖,用于提供 ICU 的实际逻辑和辅助数据,包括 icuuc72.dll 、icuin72.dll 和 icudt72.dll 文件
需要说明的是,默认情况下,系统在 C:\windows\System32\ 文件夹里面都带有 icuuc.dll 和 icuin.dll 文件,只是没有带包含 ICU 的 data file 的 icudt72.dll 文件。默认情况下 dotnet 都会使用系统自带的 dll 文件。在本文这里需要使用 Microsoft.ICU.ICU4C.Runtime 只是为了用到更多的功能,如分词和分行功能而已
安装完成的 icu.net 库和 Microsoft.ICU.ICU4C.Runtime 库之后的 csproj 项目文件内容大概如下
<Project Sdk="Microsoft.NET.Sdk"><PropertyGroup><OutputType>Exe</OutputType><TargetFramework>net9.0</TargetFramework><ImplicitUsings>enable</ImplicitUsings><Nullable>enable</Nullable></PropertyGroup><ItemGroup><PackageReference Include="icu.net" Version="3.0.0" /><PackageReference Include="Microsoft.ICU.ICU4C.Runtime" Version="72.1.0.3" /></ItemGroup></Project>
在使用 ICU 之前,需要调用 Icu.Wrapper.Init(); 方法。完全使用完成之后,建议调用 Icu.Wrapper.Cleanup(); 方法。对于很多应用程序来说,都是从一打开就使用的,直到进程退出。这时候就可以不调用 Icu.Wrapper.Cleanup(); 方法了。只有对于一些是中间过程中使用 ICU 的逻辑,才需要成对调用
Icu.Wrapper.Init();// 逻辑开始Icu.Wrapper.Cleanup();
当然了,如果为了安全性考虑,可以将 Icu.Wrapper.Cleanup(); 放到 finally 方法里面哈
以上就是所有的准备工作,接下来就是实际功能的演示
先和大家演示分词功能,测试代码如下
Span<string> testTextSpan = ["大学生活", "大学生活动", "大学生命"];foreach (var testText in testTextSpan)
{Console.WriteLine($"对 '{testText}' 进行分词:");foreach (var boundary in Icu.BreakIterator.GetBoundaries(BreakIterator.UBreakIteratorType.WORD,Locale.GetLocaleForLCID(CultureInfo.CurrentCulture.LCID), testText)){var subText = testText.AsSpan().Slice(boundary.Start, boundary.End - boundary.Start);Console.WriteLine($" - \"{subText.ToString()}\"");}
}
我这里选用了中文不简单的分词句子来进行测试,运行代码,可见控制台如下输出
分词测试:
对 '大学生活' 进行分词:- "大学"- "生活"
对 '大学生活动' 进行分词:- "大学生"- "活动"
对 '大学生命' 进行分词:- "大学"- "生命"
可以看到分词策略还是不错的
继续演示 分行 的功能。分行的功能是常见在文本排版布局里面使用,在咱中文里面大概的核心用途就是防止标点符号被错误分行,如将逗号放在行首,将 “ 左引号放在行末等错误排版问题。在英文里面则是避免一个单词被强行拆分为两行。不同的国家语言文化有不同的规则,于是才有了 ICU 库的整理规范
如以下测试代码
Console.WriteLine($"分行测试:");var text = "asd fx, aasa “说话大学生上课”\nasd sadf";
var boundaries = Icu.BreakIterator.GetBoundaries(BreakIterator.UBreakIteratorType.LINE,Locale.GetLocaleForLCID(CultureInfo.CurrentCulture.LCID), text);
foreach (Boundary boundary in boundaries)
{var subText = text.AsSpan().Slice(boundary.Start, boundary.End - boundary.Start);Console.WriteLine($" - \"{subText.ToString()}\"");
}
控制台输出如下
分行测试:- "asd "- "fx, "- "aasa "- "“说"- "话"- "大"- "学"- "生"- "上"- "课”
"- "asd "- "sadf"
可以看到以上的分行策略是正确的,可以将英文单词合并到一个 Boundary 里面,将标点符号和对应的文字也合并到一个 Boundary 里面
但尽管如此,在中文排版里面,如果严格执行 GB/T 15834 标准,那 ICU 库还是很有挑战的,且更挑战的是文本库哈。详细请看 Office 文档 文本排版布局 中华人民共和国国家标准 标点符号用法
除此之外,咱还可以使用 ICU 库进行转义,如以下测试例子
// Will output "NFC form of XA\u0308bc is XÄbc"
// 有些控制台输出不了 Ä 字符哦
Console.WriteLine($"NFC form of XA\\u0308bc is {Icu.Normalizer.Normalize("XA\u0308bc",Icu.Normalizer.UNormalizationMode.UNORM_NFC)}");
本文代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin c060ecede2ffa8b81c57e1ff8d0efcb0820fafc4
以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin c060ecede2ffa8b81c57e1ff8d0efcb0820fafc4
获取代码之后,进入 Workbench/FichallbibaRenafawwhi 文件夹,即可获取到源代码
更多技术博客,请参阅 博客导航