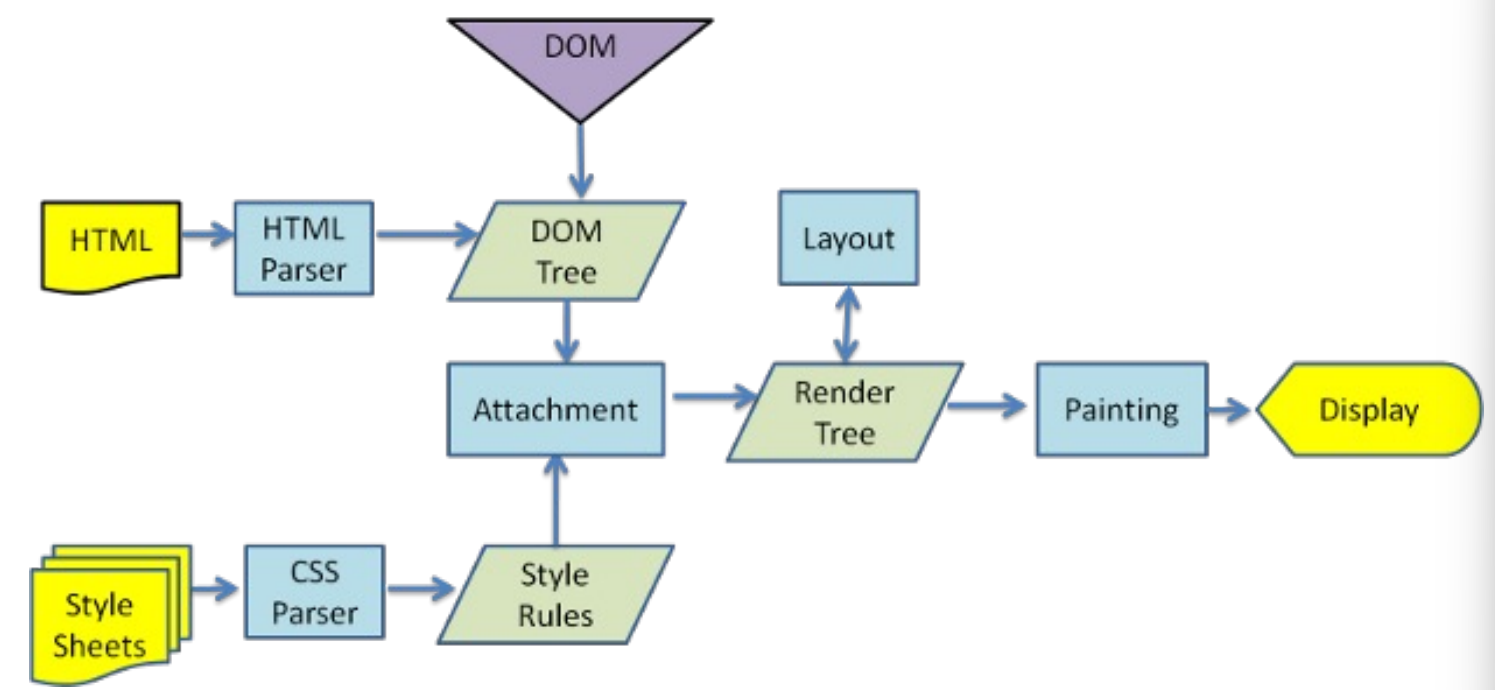
1 Kubernetes指标流水线
资源指标
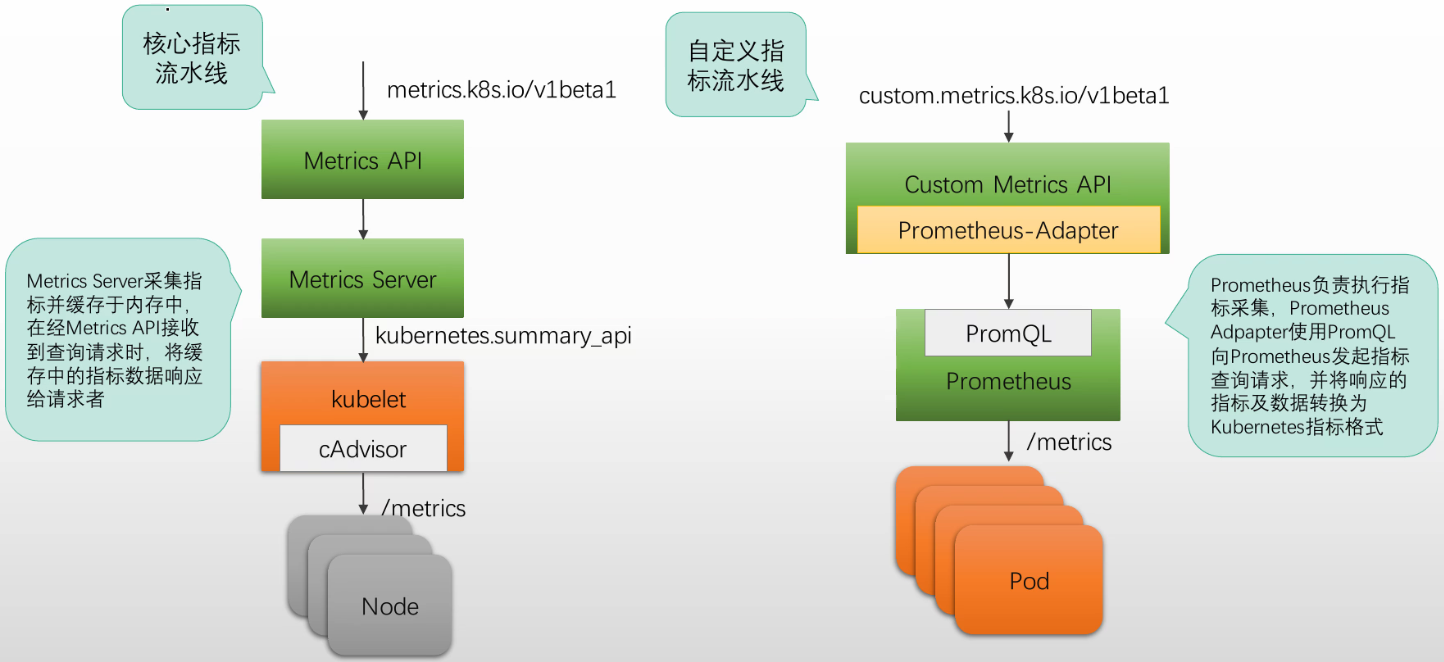
Kubernetes有一些依赖于指标数据的组件,例如HPA和VPA等Kubernetes使用Metrics API暴露系统指标给这些组件 #只暴露nodes和pods上的内存,CPU指标 该API仅提供CPU和内存相关的指标数据负责支撑Metrics API、生成并提供指标数据的组件,成为核心指标流水线 (Core Metrics Pipeline)
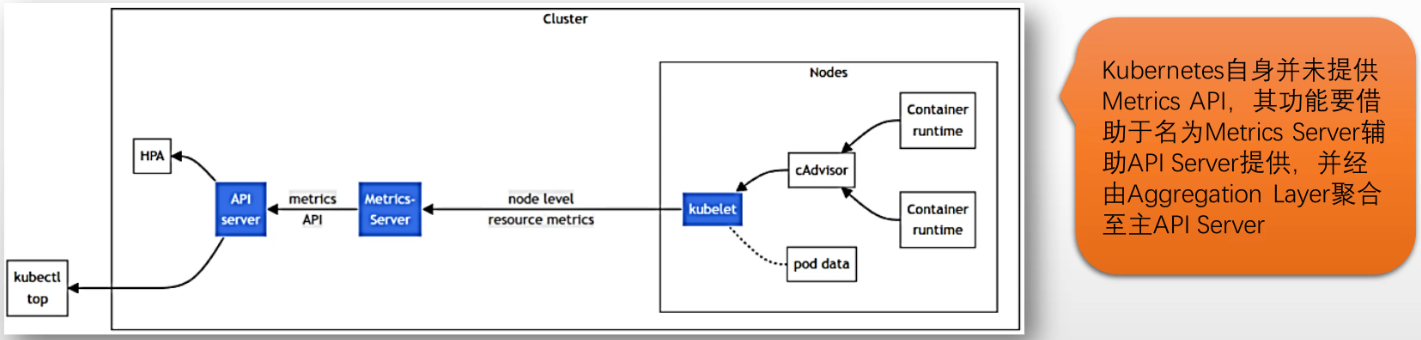
Kubernetes设计用于暴露其他指标的API,是Custom Metrics API和External Metrics API此二者通常也要由专用的辅助API Server提供,例如著名的Prometheus Adapter项目#因为Prometheus不兼容k8s API,所以中间要转换组件#请求经过API Server到Prometheus Adapter,再到Prometheus去kubelet抓取数据(可能还要node exporter或其他exporter)负责支持Custom Metrics API、生成并提供指标数据的组件,称为自定义指标流水线
核心指标流水线和自定义指标流水线
Metrics Server
口Metrics Server介绍 #收集K8s集群中Pods和Nodes的实时性能指标,CPU和内存使用率 由Kubernetes SIG社区维护从Kubelet收集资CPU和内存源指标,默认每15秒收集一次,并经由Metrics API暴露设计用于支撑HPA和VPA等组件的功能,不适用于作为监控系统组件 口部署要求kube-apiserver必须启用聚合层各节点必须启用Webhook认证和鉴权机制 #kubeadmin部署默认启用kubelet证书需要由Kubernetes CA签名,或者要使用“--kubelet-insecure-tls”选项禁用证书验证Container Runtime需要支持ontainer metrics RPC,或者内置了cAdvisor控制平面节点需要经由10250/TCP端口访问MetricsServerMetrics Server需要访问所有的节点以采集指标,默认为kubelet监听的10250端口#HPA有2个版本 #HPA早期版本只支持Metrics Server,只支持通过CPU资源使用状况来执行扩容缩容 #HPAv2版本可以通过任何从Custom Metrics获取的指标(请求速率等都行)进行扩容缩容
总结
Kubernetes + PrometheusAPI Server:role: Node,Pod,Endpoint,Service,IngressDeployment/Statefulset/Daemonset/...PVC,...Prometheus Adapter: #Prometheus的客户端,去prometheus要数据 第三方API Server,可由Aggregation Layer聚合,扩展支持更多的APIkube-state-metrics: #Prometheus的服务端,提供数据给prometheuskubernetes-exporter第三方指标流水线:prometheus-serverpromethues-adapter注册到API聚合成,提供custom,metrics.k8s,io和external.metrics.k8s.iokube-state-metrics #收集K8s集群中资源状态信息包括Pods、Nodes、Deployments、Services等,是否满足预期等 监控系统:prometheus-serveralertmanagerblackbox-exporterpush-gatewaynode-exporterkube-state-metrics被监控对象上需要的配置:`prometheus.jo/scrape`: 值为true才允许抓取指标`prometheus.io/path`: 抓取指标路径,默认路径/metrics`prometheus,io/port`: 抓指标的端口,不指就是pod监听的端口(若pod暴露的是exporter,必须指定)部署Prometheus的方法:手动部署kube-prometheus operatorCRD: Prometheus应用的自动扩缩容:Kubernetes内置实现:HPAVPA #纵向扩展,改pod模板上的资源需求和资源限制,但pod创建完不允许改(只能重建pod)CA: Cluster Autoscaler #k8s加节点扩容集群 (云环境可以使用) 第三方项目: KEDAhttps://keda.sh/OpenKruise #第三方项目:自动渐进式发布功能,自动检测如果有问题自动回滚
实际操作示例
#部署k8s集群,这里用flannel作为网络插件 #部署metallb(配置地址池和公告模式) #部署Ingress-Nginx #部署openEBS(3.10.x版本) kubectl apply -f https://openebs.github.io/charts/openebs-operator.yaml#部署metrics service [root@master01 ~]#cd learning-k8s/metrics-server/ #注意里面的参数 [root@master01 metrics-server]#vim high-availability-1.21+.yaml ...containers:- args:...- --kubelet-preferred-address-types=InternalIP #保留InternalIP即可- --kubelet-insecure-tls #加这项(实验环境,让metrics-server不验证k8s提供的ca证书);若内部pod的dns能解析节点主机名,可以不加 ... #会部署2个metrics-server实例 [root@master01 metrics-server]#kubectl apply -f high-availability-1.21+.yaml [root@master01 metrics-server]#kubectl get pods -n kube-system metrics-server-56bddb479b-8mbq5 1/1 Running 0 98s metrics-server-56bddb479b-frk2g 1/1 Running 0 98s #会生成对应的资源群组 [root@master01 metrics-server]#kubectl api-versions metrics.k8s.io/v1beta1#可以通过metrics.k8s.io/v1beta1资源群组获取指标了 #可以通过命令获取指标 [root@master01 metrics-server]#kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% master01 74m 3% 1024Mi 56% node01 28m 1% 618Mi 33% node02 83m 4% 506Mi 27% node03 30m 1% 500Mi 27% #查看pod参数 [root@master01 metrics-server]#kubectl top pods -n kube-system NAME CPU(cores) MEMORY(bytes) ... metrics-server-56bddb479b-8mbq5 2m 17Mi metrics-server-56bddb479b-frk2g 4m 19Mi #核心指标流水线已经部署完成
#下载项目,里面有对应脚本 [root@master01 ~]#git clone https://github.com/iKubernetes/k8s-prom.git [root@master01 ~]#kubectl create namespace prom [root@master01 ~]#cd k8s-prom/prometheus#部署prometheus-server (很多组件规则如告警依赖于kube-state-metrics, prometheus定义了服务发现) v2.47.2 [root@master01 prometheus]#kubectl apply -f . -n prom #prometheus-server会查看当前系统上有哪些pod允许抓指标,抓取对应的资源 [root@master01 ~]#kubectl get pods -n prom NAME READY STATUS RESTARTS AGE prometheus-server-56c7fc76b5-qjrnq 1/1 Running 0 109s#prometheus服务有个正则表达式浏览器,下面通过ingress进行部署 [root@master01 ~]#kubectl get svc -n prom NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus NodePort 10.102.232.72 <none> 9090:30090/TCP 14 [root@master01 prometheus]#cd ingress/ [root@master01 ingress]#kubectl apply -f ingress-prometheus.yaml [root@master01 ingress]#kubectl get ingress -n prom NAME CLASS HOSTS ADDRESS PORTS AGE prometheus nginx prom.magedu.com,prometheus.magedu.com 10.0.0.51 80 45s#windows配置host文件,进行访问测试 prometheus.magedu.com#创建一个pod,看看prometheus服务能不能抓取指标 (es不部署也没事,部署下面小的就行) [root@master01 ~]#cd learning-k8s/Mall-MicroService/infra-services-with-prometheus/02-ElasticStack/ [root@master01 02-ElasticStack]#vim 01-elasticsearch-cluster-persistent.yaml ...annotations:prometheus.io/scrape: "true" #允许抓取指标prometheus.io/port: "9114" #抓取指标端口,不标会通过9200来抓指标prometheus.io/path: "/metrics" ...- name: elasticsearch-exporter #里面包含了exporterimage: prometheuscommunity/elasticsearch-exporter:v1.7.0args:- '--es.uri=http://localhost:9200' #监测端口为9200 [root@master01 02-ElasticStack]#kubectl create namespace elastic [root@master01 02-ElasticStack]#kubectl apply -f 01-elasticsearch-cluster-persistent.yaml -n elastic [root@master01 02-ElasticStack]#kubectl get pods -n elastic#再部署个小的(里面提供了http_requests_total指标) [root@master01 02-ElasticStack]#cd /root/k8s-prom/prometheus-adpater/example-metrics [root@master01 example-metrics]#vim metrics-example-app.yaml ...template:metadata:labels:app: metrics-appcontroller: metrics-appannotations:prometheus.io/scrape: "true" #允许抓取指标prometheus.io/port: "80" #抓取指标端口prometheus.io/path: "/metrics" #部署 [root@master01 example-metrics]#kubectl apply -f metrics-example-app.yaml [root@master01 example-metrics]#kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE metrics-app-79cc5f8dd4-kcbxf 1/1 Running 0 17m 10.244.1.19 node01 metrics-app-79cc5f8dd4-xtg72 1/1 Running 0 17m 10.244.2.15 node02 #手动模拟访问 [root@master01 example-metrics]#curl 10.244.1.19 Hello! My name is metrics-app-79cc5f8dd4-kcbxf. The last 10 seconds, the average QPS has been 0.2. Total requests served: 71#在Prometheus网页上,搜索http_requests_total可以看到对应指标已经采集进来。status下的服务发现可以看到被发现的服务 #计算速率2分钟,可以输入 rate(http_requests_total[2m])#部署promethues-adapter [root@master01 ~]#cd /root/k8s-prom/prometheus-adpater [root@master01 prometheus-adpater]#kubectl create namespace custom-metrics #运行证书生成secret [root@master01 prometheus-adpater]#apt-get install -y golang-cfssl [root@master01 prometheus-adpater]#bash gencerts.sh#注意在 manifests/custom-metrics-apiserver-deployment.yaml里,如果prometheus没有部署在prom的ns下,要改- --prometheus-url=http://prometheus.prom.svc:9090/#完成部署 [root@master01 prometheus-adpater]#kubectl apply -f manifests/ #查看 [root@master01 manifests]#kubectl get pods -n custom-metrics NAME READY STATUS RESTARTS AGE custom-metrics-apiserver-945cc6f54-2k7lw 1/1 Running 0 8m10s #生成资源群组 [root@master01 manifests]#kubectl api-versions custom.metrics.k8s.io/v1beta1 custom.metrics.k8s.io/v1beta2 external.metrics.k8s.io/v1beta1#发起请求查询命令 --raw获取原始格式 #请求该资源群组所有数据(所有指标能抓到都会显示) 通过jq装成json格式 [root@master01 manifests]#kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1|jq .#如果要查自定义指标,需要进行添加到adapter,adapter发给promtheus查询,adapter把它转为k8s指标 #示例#有名称空间,且为pod- seriesQuery: 'http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}'resources:overrides:kubernetes_namespace: {resource: "namespace"}kubernetes_pod_name: {resource: "pod"}name:matches: "^(.*)_total" #取出http_requests_total的前缀作为下面的${1}as: "${1}_per_second" #真正发给promtheus的语句,下面Series和标签会自动从seriesQuery获取到的代入进去,然后进行计算metricsQuery: rate(<<.Series>>{<<.LabelMatchers>>}[1m])#把上述内容加入configmap中,重新生效。这个属于自定义资源指标,放入data/config.yaml/rules下即可 [root@master01 manifests]#vim custom-metrics-config-map.yaml ... data:config.yaml: |rules: #下面第一行直接追加即可- seriesQuery: 'http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}'resources:overrides:kubernetes_namespace: {resource: "namespace"}kubernetes_pod_name: {resource: "pod"}name:matches: "^(.*)_total"as: "${1}_per_second" metricsQuery: rate(<<.Series>>{<<.LabelMatchers>>}[1m]) #重新apply生效 (重载时间无法预测) [root@master01 manifests]#kubectl apply -f custom-metrics-config-map.yaml #因为重载时间无法预测,这里直接重启保险点 [root@master01 manifests]#kubectl get all -n custom-metrics deployment.apps/custom-metrics-apiserver 1/1 1 1 35m [root@master01 manifests]#kubectl rollout restart deployment.apps/custom-metrics-apiserver -n custom-metrics#获取名称空间下pod里http_requests_per_second的所有指标, 这时就能返回指标 [root@master01 manifests]#kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests_per_second | jq . {"kind": "MetricValueList","apiVersion": "custom.metrics.k8s.io/v1beta1","metadata": {},"items": [{"describedObject": {"kind": "Pod","namespace": "default","name": "metrics-app-79cc5f8dd4-kcbxf","apiVersion": "/v1"},"metricName": "http_requests_per_second","timestamp": "2024-12-23T11:21:53Z","value": "66m", #66毫秒"selector": null},{"describedObject": {"kind": "Pod","namespace": "default","name": "metrics-app-79cc5f8dd4-xtg72","apiVersion": "/v1"},"metricName": "http_requests_per_second","timestamp": "2024-12-23T11:21:53Z","value": "66m","selector": null}] }#执行hpa 扩缩容 [root@master01 ~]#cd k8s-prom/prometheus-adpater/example-metrics/ [root@master01 example-metrics]#vim metrics-app-hpa.yaml kind: HorizontalPodAutoscaler apiVersion: autoscaling/v2 metadata:name: metrics-app-hpa spec:scaleTargetRef: #对谁执行自动扩缩容apiVersion: apps/v1kind: Deploymentname: metrics-appminReplicas: 2 #最小值尽量和默认部署值保持一致maxReplicas: 10metrics:- type: Pods #参考的指标是pod上的指标 pods:metric: #指标名name: http_requests_per_second #就是上面转化为k8s的指标target: #满足什么条件就扩容type: AverageValue #平均值,多个pod的平均值averageValue: 5 #平均值>=5就扩容 behavior:scaleDown: #缩容stabilizationWindowSeconds: 120 #稳定窗口期,到达缩容期等待120秒才缩容(中途指标又变大了,就不缩容) [root@master01 example-metrics]#kubectl apply -f metrics-app-hpa.yaml #查看hpa,目标左侧显示当前为0.066,右侧目标为5 [root@master01 example-metrics]#kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE metrics-app-hpa Deployment/metrics-app 66m/5 2 10 2 27s#测试,监视查看效果 [root@master01 example-metrics]#kubectl get pods -w#其他节点发起请求测试 [root@node01 ~]#while true; do curl 10.244.1.19; sleep 0.$RANDOM; done [root@node02 ~]#while true; do curl 10.244.1.19; sleep 0.0$RANDOM; done #观察当前数值,超过数值,自动增加metrics-app对应的pod [root@master01 ~]#kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE metrics-app-hpa Deployment/metrics-app 6949m/5 2 10 6 21m#查看hpa状态,里面事件会有说明 [root@master01 example-metrics]#kubectl describe hpa metrics-app-hpa Events:Type Reason Age From Message---- ------ ---- ---- -------Normal SuccessfulRescale 4m47s horizontal-pod-autoscaler New size: 4; reason: pods metric http_requests_per_second above target #超过目标,扩展到4个Normal SuccessfulRescale 4m32s horizontal-pod-autoscaler New size: 6; reason: pods metric http_requests_per_second above target #超过目标,扩展到6个#扩展到6个pod时,指标低于5了 [root@master01 ~]#kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE metrics-app-hpa Deployment/metrics-app 4717m/5 2 10 6 26m#取消node2的请求,测试缩容效果 #查看hpa状态,里面事件会有说明 [root@master01 example-metrics]#kubectl describe hpa metrics-app-hpaNormal SuccessfulRescale 37m horizontal-pod-autoscaler New size: 4; reason: pods metric http_requests_per_second above targetNormal SuccessfulRescale 37m horizontal-pod-autoscaler New size: 6; reason: pods metric http_requests_per_second above targetNormal SuccessfulRescale 53s horizontal-pod-autoscaler New size: 4; reason: All metrics below targetNormal SuccessfulRescale 38s horizontal-pod-autoscaler New size: 3; reason: All metrics below targetNormal SuccessfulRescale 23s horizontal-pod-autoscaler New size: 2; reason: All metrics below target#注意: hpa能力有限,控制源必须是k8s指标。市面上有些项目支持多种事件源扩展机制,例如KEDA https://keda.sh/#部署kube-state-metrics(收集K8s集群中包括Pods、Nodes、Deployments、Services等相关指标) #kube-state-metrics上的指标是查api server转换出的Deployments、Services等的指标 [root@master01 ~]#cd k8s-prom/kube-state-metrics/ [root@master01 kube-state-metrics]#ls kube-state-metrics-deploy.yaml kube-state-metrics-rbac.yaml kube-state-metrics-svc.yaml [root@master01 kube-state-metrics]#cat kube-state-metrics-svc.yaml apiVersion: v1 kind: Service metadata:annotations:prometheus.io/scrape: 'true' #支持指标抓取prometheus.io/port: '8080'name: kube-state-metricsnamespace: promlabels:app: kube-state-metrics spec:ports:- name: kube-state-metricsport: 8080protocol: TCPselector:app: kube-state-metrics [root@master01 kube-state-metrics]#kubectl apply -f . -n prom #创建出kube-state-metrics [root@master01 kube-state-metrics]#kubectl get pods -n prom NAME READY STATUS RESTARTS AGE kube-state-metrics-794d6f5c8b-t6mbk 1/1 Running 0 39s prometheus-server-56c7fc76b5-qjrnq 1/1 Running 0 19h#在Prometheus网页prometheus.magedu.com服务发现栏下能看到kube-state-metrics #至此,Prometheus里配置的告警规则通过kube-state-metrics也生效了 #下面可以部署告警通知程序来发出告警通知 [root@master01 ~]#cd k8s-prom/ [root@master01 k8s-prom]#kubectl apply -f alertmanager/ -n prom #部署node_exporter来获取更多指标 (主节点上添加要添加容忍度) [root@master01 k8s-prom]#kubectl apply -f node_exporter/ -n prom [root@master01 k8s-prom]#kubectl get pods -n prom NAME READY STATUS RESTARTS AGE alertmanager-7d57465bd6-9gw8m 1/1 Running 0 2m3s kube-state-metrics-794d6f5c8b-t6mbk 1/1 Running 0 27m prometheus-node-exporter-fw7k2 1/1 Running 0 117s prometheus-node-exporter-g9c5k 1/1 Running 0 117s prometheus-node-exporter-vbdmc 1/1 Running 0 117s prometheus-server-56c7fc76b5-qjrnq 1/1 Running 1 (90m ago) 20h
kube-prometheus operator部署第三方指标流水线(生成环境推荐该方式)
官网 #kube-prometheus operator部署(流程参考官网) https://github.com/prometheus-operator/kube-prometheus https://github.com/iKubernetes/learning-k8s/tree/master/kube-prometheus#下面采用helm的方式进行部署(生成环境推荐这种方式,prometheus服务和adapter设多个即高可用可面向生产使用) #参考 https://github.com/iKubernetes/k8s-prom/tree/master/helm#实际操作示例 #先重置k8s集群,防止上面手动部署干扰 [root@master01 ~]#cd learning-k8s/ansible-k8s-install/ #这种reset可能pod没清理干净,可以到每个节点上看下容器清理完没有 crictl ps -a [root@master01 ansible-k8s-install]#ansible-playbook reset-kubeadm.yaml #这里通过脚本搭建集群,部署flannel网络插件 [root@master01 ~]#cd learning-k8s/ansible-k8s-install/ [root@master01 ansible-k8s-install]#ansible-playbook install-k8s-flannel.yaml #安装完重启下系统 [root@master01 ansible-k8s-install]#ansible-playbook reboot-system.yaml#部署metallb [root@master01 ~]#kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.14.8/config/manifests/metallb-native.yaml [root@master01 MetalLB]#vim metallb-ipaddresspool.yaml- 10.0.0.51-10.0.0.80 [root@master01 MetalLB]#kubectl apply -f metallb-ipaddresspool.yaml [root@master01 MetalLB]#vim metallb-l2advertisement.yaml interfaces:- ens33 [root@master01 MetalLB]#kubectl apply -f metallb-l2advertisement.yaml#部署ingress nginx [root@master01 ~]#kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.12.0-beta.0/deploy/static/provider/cloud/deploy.yaml [root@master01 ~]#kubectl get svc -n ingress-nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) ingress-nginx-controller LoadBalancer 10.96.54.253 10.0.0.51 80:31039/TCP,443:30770/TCP [root@master01 ~]#kubectl get pods -n ingress-nginx#部署openebs [root@master01 ~]#kubectl apply -f https://openebs.github.io/charts/openebs-operator.yaml [root@master01 ~]#kubectl get pods -n openebs#部署helm [root@master01 ~]#curl -LO https://get.helm.sh/helm-v3.16.3-linux-amd64.tar.gz [root@master01 ~]#tar xf helm-v3.16.3-linux-amd64.tar.gz [root@master01 ~]#cd linux-amd64/ [root@master01 linux-amd64]#mv helm /usr/local/bin #可以使用helm了#部署Prometheus及组件 #添加Prometheus Community的Chart仓库 (要上外网) [root@master01 ~]#helm repo add prometheus-community https://prometheus-community.github.io/helm-charts #查看仓库 [root@master01 ~]#helm repo list [root@master01 ~]#cd k8s-prom/helm/ #查看事先定义好的值文件模板 [root@master01 helm]#vim prom-values.yaml ...ingress:enabled: trueingressClassName: nginx #确认当前ingress用的是nginx,如果是cilium这里改为cilium annotations: {} ... #运行如下命令,即可加载本地的values文件,部署Prometheus (helm install会安装最新,推测这里应该安装2版本)#release名 仓库名/chart名 monitoring约定俗成 加载值文件 ]#helm install prometheus prometheus-community/prometheus --namespace monitoring --values prom-values.yaml --create-namespace #查看service/加了release前缀,所以名字有点长 [root@master01 helm]#kubectl get svc,pods -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) service/prometheus-alertmanager ClusterIP 10.103.131.169 <none> 9093/TCP service/prometheus-alertmanager-headless ClusterIP None <none> 9093/TCP service/prometheus-kube-state-metrics ClusterIP 10.98.219.172 <none> 8080/TCP service/prometheus-prometheus-node-exporter ClusterIP 10.108.142.5 <none> 9100/TCP service/prometheus-prometheus-pushgateway ClusterIP 10.105.25.116 <none> 9091/TCP service/prometheus-server ClusterIP 10.97.107.47 <none> 9090/TCP NAME READY STATUS RESTARTS AGE pod/prometheus-alertmanager-0 1/1 Running 0 87s pod/prometheus-kube-state-metrics-88947546-rb84n 1/1 Running 0 87s pod/prometheus-prometheus-node-exporter-mtw54 1/1 Running 0 87s pod/prometheus-prometheus-node-exporter-t2zp6 1/1 Running 0 87s pod/prometheus-prometheus-node-exporter-xrlkh 1/1 Running 0 87s pod/prometheus-prometheus-node-exporter-zwtrb 1/1 Running 0 87s pod/prometheus-prometheus-pushgateway-9f8c968d6-dsfpb 1/1 Running 0 87s #2个容器,其中1个是发现Prometheus config是否变更,有变更自动让prometheus加载配置 pod/prometheus-server-6b884dc7f6-cqznp 2/2 Running 0 87s#注意:这里没有使用kube-operator封装,只是通过helm中的chart把组件部署起来#访问prometheus [root@master01 helm]#kubectl get ingress -n monitoring NAME CLASS HOSTS ADDRESS PORTS AGE prometheus-server nginx prometheus.magedu.com 10.0.0.51 80 29m #上面windows的hosts已经配置了,这里浏览器直接输入 prometheus.magedu.com#接下来通过cm配置Prometheus的规则,和告警配置 [root@master01 helm]#kubectl get cm -n monitoring NAME DATA AGE kube-root-ca.crt 1 38m prometheus-alertmanager 1 38m prometheus-server 6 38m #查看(在该基础上更改即可,prometheus会自动发现修改,重载配置的) [root@master01 helm]#kubectl get cm prometheus-server -o yaml -n monitoring#部署Prometheus Adapter 里面加入了自定义规则 (要上外网) [root@master01 helm]#helm install prometheus-adapter prometheus-community/prometheus-adapter --values prom-adapter-values.yaml --namespace monitoring #等待pod运行成功 [root@master01 helm]#kubectl get pods -n monitoring #生成资源群组 [root@master01 helm]#kubectl api-versions custom.metrics.k8s.io/v1beta1 external.metrics.k8s.io/v1beta1#部署pod测试 [root@master01 ~]#cd k8s-prom/prometheus-adpater/example-metrics/ [root@master01 example-metrics]#kubectl apply -f metrics-example-app.yaml [root@master01 example-metrics]#kubectl get pods NAME READY STATUS RESTARTS AGE metrics-app-79cc5f8dd4-nqkl4 1/1 Running 0 18s metrics-app-79cc5f8dd4-wsg79 1/1 Running 0 18s #注意:这里prometheus报该pod返回的Content-Type和fallback_scrape_protocol指定问题,应该是3.0版本问题 #所以这里prometheus不接收该pod的参数指标后续实验无法进行#查看部署的实例 [root@master01 example-metrics]#helm list -n monitoring NAME NAMESPACE REVISION STATUS CHART APP VERSION prometheus monitoring 1 deployedprometheus-26.0.1 v3.0.1 prometheus-adapter monitoring 1 UTC deployedprometheus-adapter-4.11.0 v0.12.0 #显示状态,会显示提示(返回的就是刚刚部署返回的信息) [root@master01 example-metrics]#helm status prometheus-adapter -n monitoring#查看自定义资源群组 ]#kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 |jq . #查看那个pod上的自定义指标 http_requests_per_second ]#kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests_per_second |jq .#接下来部署hpa,做压测效果也是一样的