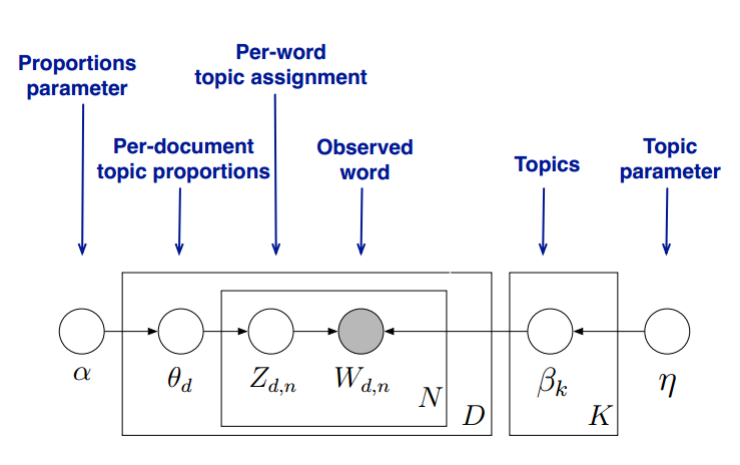
LDA假设每个文档都是多个主题的混合,每个主题又是多个词语的混合。它通过识别文档中的词语分布来推断出文档的主题结构。LDA的一个简单比喻是冰淇淋店:每个文档就像一个装满多种口味冰淇淋的甜筒,而LDA的任务就是根据观察到的冰淇淋,推断出每种口味(即每个主题)在这些甜筒中的比例。LDA(Latent Dirichlet Allocation)主题分析是一种文本挖掘和机器学习技术,旨在从大量文本数据中发现主题结构。该方法假设每个文档都是由多个主题组成,而每个主题又由一组单词表示。LDA的应用领域包括信息检索、社交媒体分析、新闻主题挖掘等。
一、Gensim库实现LDA
应用 gensim 库实现 LDA(Latent Dirichlet Allocation)主题建模及可视化的详细步骤,并对每个步骤提供相应的 Python 代码。文章将分为以下几个部分:数据准备、文本预处理、LDA 模型训练及优化、结果分析与可视化。
1.1 数据准备
步骤:导入所需的库;加载数据(可使用自定义数据集或公开数据集);数据清理(移除无关字符)。
import pandas as pd
from gensim import corpora, models
from gensim.models import CoherenceModel
import pyLDAvis.gensim_models as gensimvis
import pyLDAvis# 示例:加载文本数据
data = ["Natural language processing enables machines to understand human language.","Machine learning models can improve by analyzing more data.","Deep learning uses neural networks to learn representations.","Latent Dirichlet Allocation is a popular topic modeling technique."
]# 数据清理(示例:全小写处理)
data = [text.lower() for text in data]
1.2 文本预处理
步骤:分词;移除停用词及非字母文本;生成词典和词袋模型(Bag of Words)。
复制代码
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
nltk.download('stopwords')# 停用词列表
stop_words = set(stopwords.words('english'))# 文本分词并移除停用词和非字母字符
processed_data = [[word for word in word_tokenize(doc) if word.isalpha() and word not in stop_words]for doc in data
]# 创建词典
dictionary = corpora.Dictionary(processed_data)# 创建词袋模型
corpus = [dictionary.doc2bow(text) for text in processed_data]
1.3 LDA 模型训练及优化
步骤:选择 LDA 模型的参数,例如主题数;使用 gensim 的 LdaModel 训练模型;使用主题一致性分数优化主题数。
# 训练 LDA 模型
lda_model = models.LdaModel(corpus=corpus,id2word=dictionary,num_topics=4, # 设置主题数random_state=42,passes=10,alpha='auto',per_word_topics=True
)# 打印每个主题的前5个词
for idx, topic in lda_model.print_topics(-1):print(f"主题 {idx}: {topic}")# 主题一致性分数计算(用于选择最佳主题数)
coherence_model = CoherenceModel(model=lda_model,texts=processed_data,dictionary=dictionary,coherence='c_v'
)
print(f"主题一致性分数: {coherence_model.get_coherence()}")
1.4 结果分析与可视化
步骤:使用 pyLDAvis 进行交互式可视化;查看每个主题的关键词分布及文档-主题分布。
# 使用 pyLDAvis 可视化
pyLDAvis.enable_notebook()
lda_vis_data = gensimvis.prepare(lda_model, corpus, dictionary)
pyLDAvis.display(lda_vis_data)# 可选择将可视化结果保存为 HTML 文件
pyLDAvis.save_html(lda_vis_data, 'lda_visualization.html')
上述步骤涵盖了从文本预处理到 LDA 模型训练以及最终结果可视化的完整过程。以下是每个步骤的关键点:
数据预处理是确保模型效果的基础,重点是分词、去停用词和创建词袋模型。
LDA 模型的核心在于主题数选择,可以通过一致性分数进行优化。
使用 pyLDAvis 提供了非常直观的交互式主题分布分析工具。
通过这些代码与方法,你可以快速实现对任意文本数据的主题建模,并通过可视化深入理解文本主题结构。
二、LDA主题模型的Python实现
2.1 程序
数据来源:数据大,运行时间长,调试时可用部分数据:https://www.kaggle.com/gauravduttakiit/npr-data
import pandas as pd
from gensim import corpora, models
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
nltk.download('stopwords')# 一、加载数据
npr = pd.read_csv('npr.csv')
print(npr.head())# 二、文本预处理
# 停用词列表
stop_words = set(stopwords.words('english'))# 数据清洗与分词
def preprocess_text(text):tokens = word_tokenize(text.lower()) # 转小写并分词return [word for word in tokens if word.isalpha() and word not in stop_words] # 移除停用词和非字母字符# 对每篇文章进行预处理
processed_data = npr['Article'].dropna().apply(preprocess_text).tolist()# 创建词典和词袋模型
dictionary = corpora.Dictionary(processed_data)
corpus = [dictionary.doc2bow(text) for text in processed_data]# 三、LDA 模型训练
lda_model = models.LdaModel(corpus=corpus,id2word=dictionary,num_topics=7, # 设置主题数random_state=42,passes=10,alpha='auto',per_word_topics=True
)# 打印每个主题的前15个词
for idx, topic in lda_model.print_topics(num_words=15):print(f"主题 {idx}: {topic}")# 四、主题分配
# 获取每篇文章的主题分布
doc_topics = [lda_model.get_document_topics(doc) for doc in corpus]# 获取每篇文章的主主题
npr['Topic'] = [max(doc, key=lambda x: x[1])[0] for doc in doc_topics]# 打印结果
print(npr.head())
2.2 程序逻辑说明
数据加载:
使用 pandas 读取 npr.csv 文件,并输出前几行以了解数据格式。
文本预处理:
将文章文本分词,移除停用词和非字母字符,确保主题建模聚焦于有意义的词汇。
词典和语料库创建:
使用 gensim.corpora.Dictionary 构建词典,并生成 Bag-of-Words 模型以供 LDA 使用。
LDA 模型训练:
设置 num_topics=7 表示提取7个主题。
使用 alpha='auto' 自动调整主题稀疏度。
打印每个主题的前15个关键词。
主题分配:
为每篇文章分配主主题,方法是获取主题分布中概率最高的主题编号。
将主主题编号存储到数据框的新列 Topic 中。
输出:
每个主题的关键词展示,可以帮助理解主题含义。
每篇文章的主主题编号,存储在 npr['Topic'] 列中。
最终打印带有主题列的数据框。
通过 Gensim 的实现,你可以更高效地进行主题建模,并获得更直观的输出结果。
2.3 程序运行结果
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\hao'hai\AppData\Roaming\nltk_data...
[nltk_data] Unzipping tokenizers\punkt.zip.
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\hao'hai\AppData\Roaming\nltk_data...
[nltk_data] Unzipping corpora\stopwords.zip.Article
0 In the Washington of 2016, even when the polic...
1 Donald Trump has used Twitter — his prefe...
2 Donald Trump is unabashedly praising Russian...
3 Updated at 2:50 p. m. ET, Russian President Vl...
4 From photography, illustration and video, to d...
主题 0: 0.011*"said" + 0.009*"says" + 0.007*"police" + 0.007*"people" + 0.004*"city" + 0.004*"one" + 0.004*"government" + 0.004*"country" + 0.004*"reports" + 0.004*"also" + 0.003*"two" + 0.003*"war" + 0.003*"last" + 0.003*"according" + 0.003*"told"
主题 1: 0.024*"trump" + 0.013*"clinton" + 0.011*"said" + 0.008*"would" + 0.007*"campaign" + 0.007*"president" + 0.006*"state" + 0.006*"republican" + 0.005*"election" + 0.005*"voters" + 0.005*"obama" + 0.005*"vote" + 0.005*"percent" + 0.005*"people" + 0.005*"party"
主题 2: 0.012*"music" + 0.007*"new" + 0.006*"song" + 0.005*"album" + 0.005*"one" + 0.004*"songs" + 0.004*"band" + 0.004*"like" + 0.004*"first" + 0.004*"space" + 0.003*"also" + 0.003*"time" + 0.003*"years" + 0.003*"year" + 0.003*"rock"
主题 3: 0.019*"says" + 0.007*"food" + 0.006*"water" + 0.005*"one" + 0.005*"like" + 0.004*"new" + 0.004*"people" + 0.003*"years" + 0.003*"could" + 0.003*"also" + 0.003*"zika" + 0.003*"world" + 0.002*"would" + 0.002*"scientists" + 0.002*"animals"
主题 4: 0.010*"like" + 0.008*"people" + 0.008*"one" + 0.008*"says" + 0.005*"think" + 0.005*"know" + 0.005*"time" + 0.004*"really" + 0.004*"would" + 0.004*"way" + 0.004*"get" + 0.004*"first" + 0.003*"life" + 0.003*"going" + 0.003*"even"
主题 5: 0.016*"trump" + 0.014*"said" + 0.008*"president" + 0.007*"court" + 0.005*"would" + 0.005*"law" + 0.005*"also" + 0.004*"news" + 0.004*"house" + 0.004*"federal" + 0.004*"department" + 0.004*"new" + 0.004*"case" + 0.004*"state" + 0.004*"justice"
主题 6: 0.021*"says" + 0.009*"people" + 0.008*"health" + 0.005*"percent" + 0.005*"one" + 0.005*"school" + 0.004*"care" + 0.004*"get" + 0.004*"would" + 0.004*"students" + 0.004*"also" + 0.004*"many" + 0.004*"new" + 0.004*"like" + 0.003*"study"Article Topic
0 In the Washington of 2016, even when the polic... 5
1 Donald Trump has used Twitter — his prefe... 5
2 Donald Trump is unabashedly praising Russian... 5
3 Updated at 2:50 p. m. ET, Russian President Vl... 5
4 From photography, illustration and video, to d... 0
总结
Gensim库提供了高效、灵活的工具,用于实现LDA(Latent Dirichlet Allocation)主题建模,能够帮助从海量文本数据中提取潜在主题。整个过程主要包括数据准备、文本预处理、模型训练与优化以及结果可视化。在实际应用中,数据预处理是关键的一步,涉及分词、去停用词和构建词袋模型(Bag of Words)。这些步骤直接影响LDA模型的效果和主题提取的准确性。模型训练时,主题数的选择对结果至关重要,可以通过主题一致性分数(如c_v一致性)进行优化,以确定最佳参数配置。Gensim的LdaModel能够根据给定的文档-词汇矩阵和词典生成主题分布,同时允许调整passes和alpha等参数来提升模型性能。此外,结合pyLDAvis工具,可以通过交互式可视化直观呈现主题分布和关键词权重,有助于对结果进行深入分析和解释。Gensim的LDA模型是文本挖掘和自然语言处理中的重要工具,尤其适用于学术研究、市场分析和客户反馈分类等任务,为探索文本数据中的隐藏信息提供了便捷的途径。

参考资料
- https://blog.csdn.net/X308919/article/details/143857680
- 基于LDA主题分析的《老友记》情景喜剧数据集建模与分析研究
- https://zhuanlan.zhihu.com/p/62148264