本文章详解了K-means聚类算法的原理及其优缺点,进行了K-means聚类算法的Python及C++基础实现。
一、聚类分析概述
- 定义:
- 根据“物以类聚”原理,将本身尚未归类的样本根据多个维度(属性)聚集成不同的组,这样的一组数据对象的集合叫做簇或群组。
- 经过聚类划分后的群组特性目标:
- 属于同一群组的样本之间彼此足够相似;
- 属于不同群组的样本应该足够不相似;
- 聚类与分类的区别:
- 聚类没有事先预定的类别,不需要人工标注和预先训练分类器,类别在聚类过程中自动生成,即聚类是一种无监督学习算法。
二、聚类分析代表算法:K-means算法介绍
2.1 K-means算法的五大计算步骤【概述】
- 数据预处理(如归一化),使数据点的每个属性值均位于【0,1】之间;
- 设定一个数K,用于表示期望将数据分为几个群簇(组);
- 从所有实例中随机选择K个实例,分别代表一类群簇的群簇中心;
- 对剩余的每个实例,计算其与各个群簇的群簇中心的距离(欧氏距离),根据计算结果将各个实例分配到离自己最近的一个群簇中(通过添加标记表示分配);
- 更新群簇中心,即重新计算得出每个群簇的新的中心点;
- 重复第4、5步,直到每个群簇中心不再变化(即直到所有实例在K组分布中都找到离自己最近的群簇中心),或达到最大迭代次数(人工设置);
- 退出计算;
2.2 K-means算法的适用条件及优缺点
- 适用条件
- K-means算法适合使用数值型属性的数据集(可用于欧式距离计算),而非使用类别型属性。
- 优点
- 实现原理简洁易懂。
- 算法属于无监督学习。
- 缺点
- 可能存在数据点使得聚类计算无法收敛,这就需要人为指定最大迭代次数。
- 需要给定期望将数据分为几个群簇(组)的初始K值。
- K-means算法需要提前设定聚类数K,这个值的选择往往需要根据具体问题和数据特点来确定。如果K值选择不当,可能会导致聚类结果不符合实际情况或无法有效揭示数据的内在结构。
- 在实际应用中,可以通过一些评估指标(如轮廓系数、肘部法则等)来辅助确定合适的K值。
- K-means算法对初始聚类中心敏感
- K-means算法的聚类结果在很大程度上受到初始聚类中心选择的影响。如果初始聚类中心选择不当,可能会导致聚类结果出现偏差或迭代次数较多导致计算结果不稳定。
- 为了缓解这一问题,可以采用一些启发式方法(如K-means++算法)来优化初始聚类中心的选择。
2.3 K-means算法的数学模型
- 划分数据点$$dist(x,c_i)=\sqrt{\sum_{j=1}{d}(x_j-c_{ij})2}$$
- 参数说明
- \(x\):数据点
- \(c_i\):第i个聚类中心
- \(d\):数据的维度
- \(x_j和c_{ij}\):分别是\(x\)和\(c_i\)在第\(j\)维上的值。
- 更新群簇中心$$c_i=\frac{1}{|S_i|}\sum_{x\epsilon{S_i}}x$$
- 参数说明
- \(S_i\):第\(i\)个聚类的数据点集合
- \(|S_i|\):该集合中数据点的数量
三、K-means算法编程实现
3.1 测试数据集介绍
- 本测试采用鸢尾花数据集;
- 鸢尾花数据集包含3种类型数据集,共150条数据;
- 鸢尾花数据集包含4项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,特征值都为正浮点数,单位为厘米;
- 通过上述4个特征预测鸢尾花属于(iris-setosa(山鸢尾) , iris-versicolour(杂色鸢尾) , irisvirginica(维吉尼亚鸢尾))中的哪一品种。
3.2 使用Python库处理鸢尾花数据集
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
import numpy as np2
import matplotlib.pyplot as plt
# 第一步:使用聚类器进行聚类分析
temp = load_iris() #实例化鸢尾花数据
iris_dataset = temp.data[:, :4] # 取特征空间中的前四个维度,因为第五个维度是鸢尾花数据集已做好的分类标记
kms = KMeans(n_clusters=3) #构造聚类器,指定期望的群簇数
kms.fit_predict(iris_dataset) #使用聚类器对鸢尾花数据进行聚类分析
label_pred = kms.labels_ #获取聚类标签
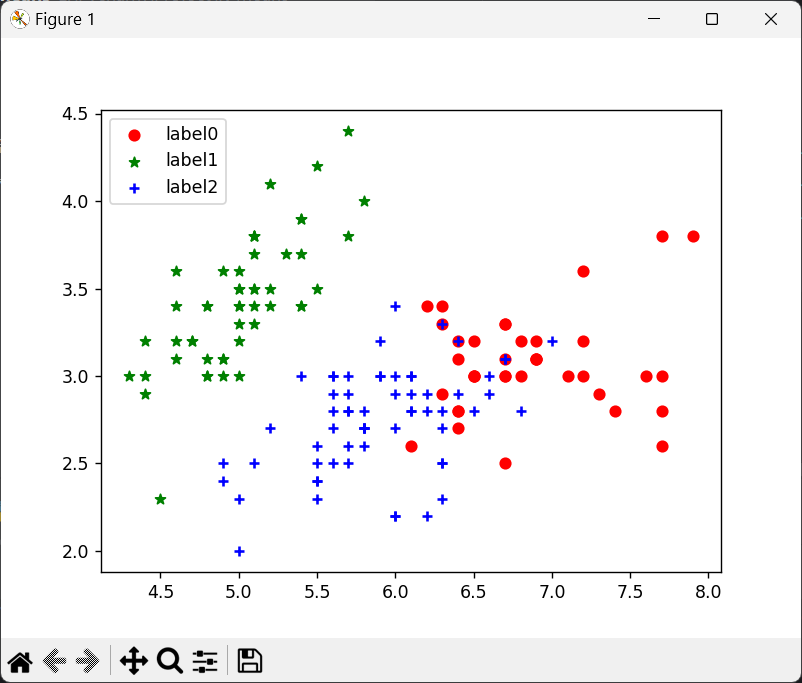
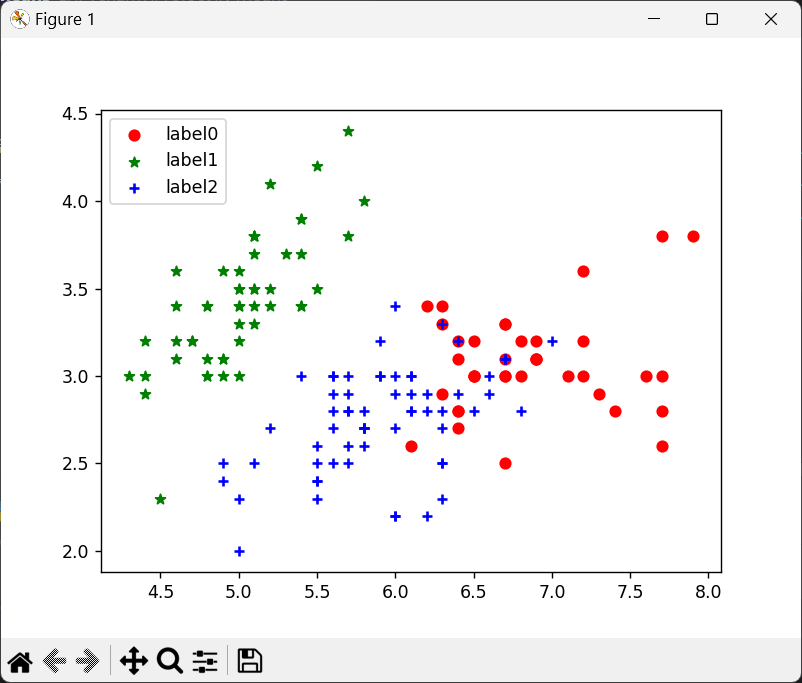
# 第二步:对聚类结果进行绘图
x0 = iris_dataset[label_pred == 0] # 获取聚类后标签为0的数据
x1 = iris_dataset[label_pred == 1] # 获取聚类后标签为1的数据
x2 = iris_dataset[label_pred == 2] # 获取聚类后标签为2的数据
plt.scatter(x0[:, 0], x0[:, 1], c = "red", marker = "o", label = "label0") # 为了在平面图上表示,每个样本使用其两个特征来绘制其二维数据分布图,但样本本身是聚类成了三类,不可混淆了
plt.scatter(x1[:, 0], x1[:, 1], c = "green", marker = "*", label = "label1")
plt.scatter(x2[:, 0], x2[:, 1], c = "blue", marker = "+", label = "label2")
plt.legend(loc = 2)
plt.show()
3.3 使用C++编写K-means算法处理鸢尾花数据集
- 设计流程如下
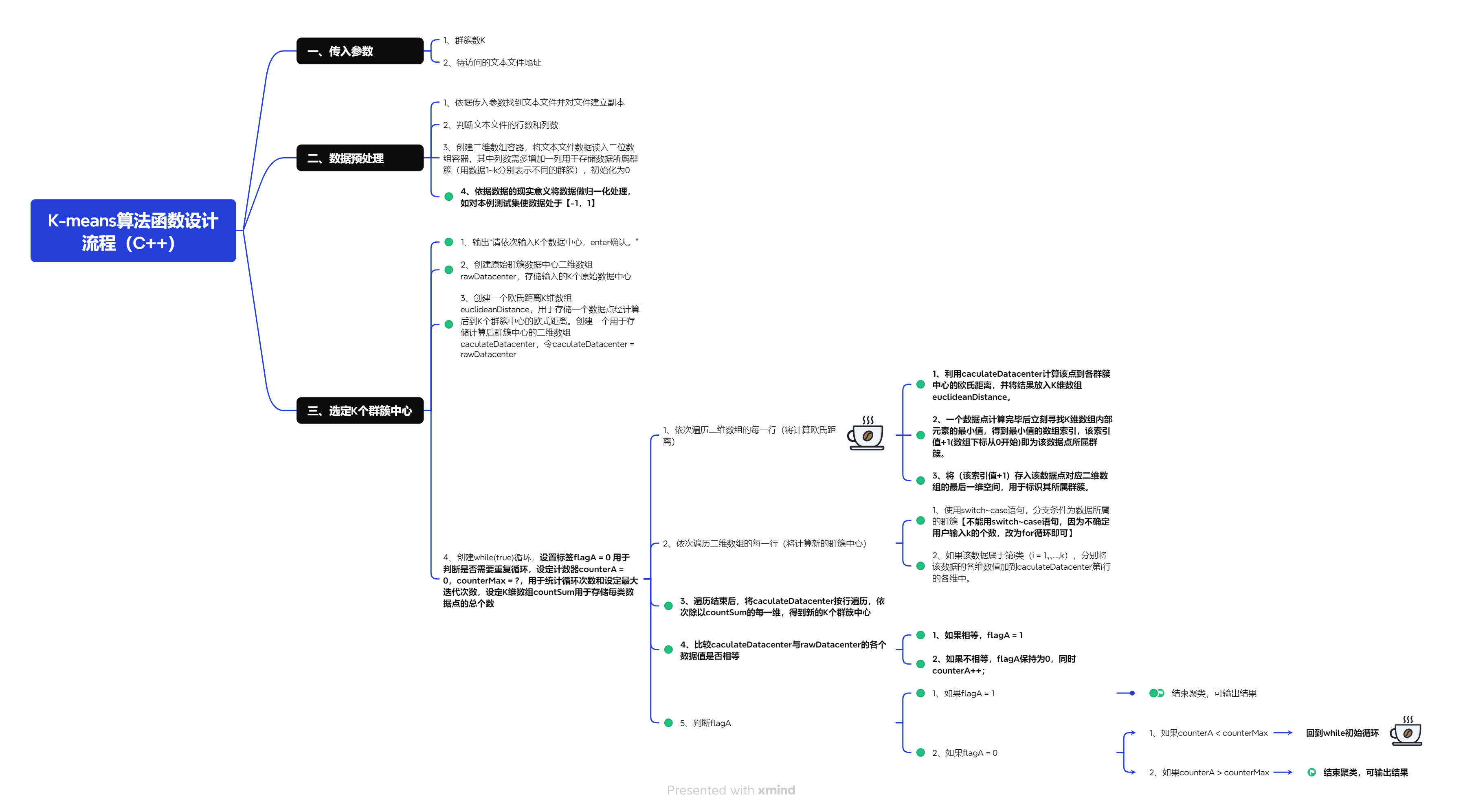
- 代码如下【C++可视化待更新】
#include <iostream>
#include <vector>
#include <fstream>
#include <string>
#include <unordered_map>
#include <algorithm>
using namespace std;int main() {//读取文件,载入数据vector<vector<float>> database_init;vector<string> line;ifstream infile("C:/Users/asus/Desktop/iris.txt"); //鸢尾花数据集文件可见文末附件if (!infile) {cout << "无法打开文件~" << endl;return 1;}string temp;vector<float> iris_dataset;while (getline(infile,temp)) {string temp2;int x = temp.size();for (int i = 0; i < x; i++) {if (temp[i] != ' ') {temp2 += temp[i];}else {line.push_back(temp2);temp2 = "";}}line.erase(line.begin());for (int i = 0; i < line.size(); i++)iris_dataset.push_back(stof(line[i])); //stof:将string转为floatiris_dataset.push_back(0.0);database_init.push_back(iris_dataset);iris_dataset.clear(); //一定要记得及时清除数据啊!!line.clear(); //还有这个!!}infile.close();vector<vector<float>> database = database_init; //备份数据//数据预处理:归一化处理float sum = 0;for (int i = 0; i < database.size(); i++) {sum = 0;for (int j = 0; j < 4; j++)sum += database[i][j];for (int j = 0; j < 4; j++)database[i][j] = database[i][j] / sum;}//随机选定k个群簇中心【初始选取聚类中心不同,得到的聚类结果也不同】cout << "请输入待聚类的群簇个数k:";int k = 0;cin >> k;vector<vector<float>> rawDatacenter;int randnum = 0;srand(time(NULL)); //确保每一轮生成的随机数序列不同for (int i = 0; i < k; i++) { //从n个数据点中随机生成k个原始群簇中心,该选取方式可以优化randnum = rand() % database.size();rawDatacenter.push_back(database[randnum]);}vector<float> euclideanDistance;vector<vector<float>> caculateDatacenter;caculateDatacenter = rawDatacenter;//进入迭代循环int flag_out = 0;int numberOfCycles = 0;unordered_map<float, float> sums; //创建哈希表用于存储聚类计算后k类中每类数据点的总个数while (flag_out == 0 && numberOfCycles < 50) { //numberOfCycles值的选定有待推敲,可以优化for (int i = 0; i < database.size(); i++) {//分别计算该数据点到k个群簇中心的欧氏距离,并将计算结果放入euelideanDistance。for (int j = 0; j < k; j++) {float distance = 0;for (int n = 0; n < 4; n++)distance += pow((database[i][n] - caculateDatacenter[j][n]), 2); //平方和distance = sqrt(distance);euclideanDistance.push_back(distance);}//依据最小欧氏距离,确定该数据点所属群簇float mindistance = euclideanDistance[0];int index = 0;for (int j = 1; j < k; j++) {if (euclideanDistance[j] < mindistance) {index = j;mindistance = euclideanDistance[j];}}database[i][4] = index + 1; //得到该数据点所属群簇(1~k)euclideanDistance.clear(); //记得清空容器哦~}//将群簇中心清零,用于填充新的群簇中心for (int i = 0; i < caculateDatacenter.size(); i++) {for (int j = 0; j < caculateDatacenter[0].size(); j++)caculateDatacenter[i][j] = 0; //清零但保持索引}//标记完所有数据点所属群簇后,开始进行新的群簇中心计算sums.clear(); //将哈希表清空for (int i = 0; i < database.size(); i++) {if (sums.count(database[i][4]))sums[database[i][4]]++;elsesums[database[i][4]] = 1;for (int j = 0; j < 4; j++)caculateDatacenter[database[i][4] - 1][j] += database[i][j];}for (int i = 0; i < caculateDatacenter.size(); i++) {for (int j = 0; j < caculateDatacenter[0].size(); j++) {caculateDatacenter[i][j] = caculateDatacenter[i][j] / sums[i + 1];}}//比较caculateDatacenter是否与rawDatacenter相同,若相同,则退出迭代,反之需要继续迭代[当然也要设置一定的迭代次数]bool ifSameCenter = equal(caculateDatacenter.begin(), caculateDatacenter.end(), rawDatacenter.begin(), rawDatacenter.end());if (ifSameCenter == true)flag_out = 1;else {numberOfCycles++;rawDatacenter = caculateDatacenter;}}for (int i = 0; i < database.size(); i++) {for (int j = 0; j < database[0].size() - 1; j++) {cout << fixed << setprecision(1) << database_init[i][j] << " "; //控制输出精度,保留一位小数}cout.unsetf(ios::fixed); //取消输出精度(因为该项是聚类类型)cout << database[i][4] << '\n';}return 0;
}
四、K-means算法的实际应用——基于聚类的图像压缩
- 通过将颜色空间中的颜色值进行迭代聚类从而得到k个聚类中心;
- 每个聚类中心代表一种颜色,使用k个聚类中心颜色值表示图像,从而实现对图像颜色种类进行缩减的目标。
- 图像颜色种类减少,有助于减小图像文件的大小,因此完成了对图像的压缩处理。

五、K-means算法的改进
5.1 聚类群簇数K值的确定
- K-means算法需要提前设定聚类数K,这个值的选择往往需要根据具体问题和数据特点来确定。
- 如果K值选择不当,可能会导致聚类结果不符合实际情况或无法有效揭示数据的内在结构。
- 在实际应用中,我们可以通过一些评估指标(如轮廓系数、肘部法则等)来辅助确定合适的K值。
5.1.1 肘部法则简述
- 肘部法则通过观察数据集的聚类平方和(SSE)随着K值变化的曲线来确定最优聚类数。
- 当K值较小时,增加K值会显著降低数据集的聚类平方和(SSE)。
- 当K值到达某个分界点后,再增加K值对数据集的聚类平方和(SSE)的降低效果将不再明显,该分界点对应的K值即为最优聚类数。
5.2 聚类中心的选择
- K-means算法的聚类结果在很大程度上受到初始聚类中心选择的影响。
- 如果初始聚类中心选择不当,可能会导致聚类结果出现偏差或不稳定。为了缓解这一问题,可以采用一些启发式方法(如K-means++算法)来优化初始聚类中心的选择。
5.2.1 K-means++算法简述
- K-means++算法首先随机选择一个数据点作为初始聚类中心。
- 紧接着,K-means++算法对每个未被选择的数据点计算其与确定的聚类中心之间的最小距离。
- 根据最小距离计算结果及其概率分布,K-means++算法能够选择下一个聚类中心。
- 通过上述方式,K-means++算法能够使得选定的聚类中心之间距离较远,从而避免陷入局部最优解。
六、参考文献
- CSDN:机器学习-14 K-means聚类算法:原理、应用与优化
- CSDN:c/c++输出保留指定位小数(输出精度控制)
七、附件
7.1 iris.txt
"1" 5.1 3.5 1.4 0.2 "setosa"
"2" 4.9 3 1.4 0.2 "setosa"
"3" 4.7 3.2 1.3 0.2 "setosa"
"4" 4.6 3.1 1.5 0.2 "setosa"
"5" 5 3.6 1.4 0.2 "setosa"
"6" 5.4 3.9 1.7 0.4 "setosa"
"7" 4.6 3.4 1.4 0.3 "setosa"
"8" 5 3.4 1.5 0.2 "setosa"
"9" 4.4 2.9 1.4 0.2 "setosa"
"10" 4.9 3.1 1.5 0.1 "setosa"
"11" 5.4 3.7 1.5 0.2 "setosa"
"12" 4.8 3.4 1.6 0.2 "setosa"
"13" 4.8 3 1.4 0.1 "setosa"
"14" 4.3 3 1.1 0.1 "setosa"
"15" 5.8 4 1.2 0.2 "setosa"
"16" 5.7 4.4 1.5 0.4 "setosa"
"17" 5.4 3.9 1.3 0.4 "setosa"
"18" 5.1 3.5 1.4 0.3 "setosa"
"19" 5.7 3.8 1.7 0.3 "setosa"
"20" 5.1 3.8 1.5 0.3 "setosa"
"21" 5.4 3.4 1.7 0.2 "setosa"
"22" 5.1 3.7 1.5 0.4 "setosa"
"23" 4.6 3.6 1 0.2 "setosa"
"24" 5.1 3.3 1.7 0.5 "setosa"
"25" 4.8 3.4 1.9 0.2 "setosa"
"26" 5 3 1.6 0.2 "setosa"
"27" 5 3.4 1.6 0.4 "setosa"
"28" 5.2 3.5 1.5 0.2 "setosa"
"29" 5.2 3.4 1.4 0.2 "setosa"
"30" 4.7 3.2 1.6 0.2 "setosa"
"31" 4.8 3.1 1.6 0.2 "setosa"
"32" 5.4 3.4 1.5 0.4 "setosa"
"33" 5.2 4.1 1.5 0.1 "setosa"
"34" 5.5 4.2 1.4 0.2 "setosa"
"35" 4.9 3.1 1.5 0.2 "setosa"
"36" 5 3.2 1.2 0.2 "setosa"
"37" 5.5 3.5 1.3 0.2 "setosa"
"38" 4.9 3.6 1.4 0.1 "setosa"
"39" 4.4 3 1.3 0.2 "setosa"
"40" 5.1 3.4 1.5 0.2 "setosa"
"41" 5 3.5 1.3 0.3 "setosa"
"42" 4.5 2.3 1.3 0.3 "setosa"
"43" 4.4 3.2 1.3 0.2 "setosa"
"44" 5 3.5 1.6 0.6 "setosa"
"45" 5.1 3.8 1.9 0.4 "setosa"
"46" 4.8 3 1.4 0.3 "setosa"
"47" 5.1 3.8 1.6 0.2 "setosa"
"48" 4.6 3.2 1.4 0.2 "setosa"
"49" 5.3 3.7 1.5 0.2 "setosa"
"50" 5 3.3 1.4 0.2 "setosa"
"51" 7 3.2 4.7 1.4 "versicolor"
"52" 6.4 3.2 4.5 1.5 "versicolor"
"53" 6.9 3.1 4.9 1.5 "versicolor"
"54" 5.5 2.3 4 1.3 "versicolor"
"55" 6.5 2.8 4.6 1.5 "versicolor"
"56" 5.7 2.8 4.5 1.3 "versicolor"
"57" 6.3 3.3 4.7 1.6 "versicolor"
"58" 4.9 2.4 3.3 1 "versicolor"
"59" 6.6 2.9 4.6 1.3 "versicolor"
"60" 5.2 2.7 3.9 1.4 "versicolor"
"61" 5 2 3.5 1 "versicolor"
"62" 5.9 3 4.2 1.5 "versicolor"
"63" 6 2.2 4 1 "versicolor"
"64" 6.1 2.9 4.7 1.4 "versicolor"
"65" 5.6 2.9 3.6 1.3 "versicolor"
"66" 6.7 3.1 4.4 1.4 "versicolor"
"67" 5.6 3 4.5 1.5 "versicolor"
"68" 5.8 2.7 4.1 1 "versicolor"
"69" 6.2 2.2 4.5 1.5 "versicolor"
"70" 5.6 2.5 3.9 1.1 "versicolor"
"71" 5.9 3.2 4.8 1.8 "versicolor"
"72" 6.1 2.8 4 1.3 "versicolor"
"73" 6.3 2.5 4.9 1.5 "versicolor"
"74" 6.1 2.8 4.7 1.2 "versicolor"
"75" 6.4 2.9 4.3 1.3 "versicolor"
"76" 6.6 3 4.4 1.4 "versicolor"
"77" 6.8 2.8 4.8 1.4 "versicolor"
"78" 6.7 3 5 1.7 "versicolor"
"79" 6 2.9 4.5 1.5 "versicolor"
"80" 5.7 2.6 3.5 1 "versicolor"
"81" 5.5 2.4 3.8 1.1 "versicolor"
"82" 5.5 2.4 3.7 1 "versicolor"
"83" 5.8 2.7 3.9 1.2 "versicolor"
"84" 6 2.7 5.1 1.6 "versicolor"
"85" 5.4 3 4.5 1.5 "versicolor"
"86" 6 3.4 4.5 1.6 "versicolor"
"87" 6.7 3.1 4.7 1.5 "versicolor"
"88" 6.3 2.3 4.4 1.3 "versicolor"
"89" 5.6 3 4.1 1.3 "versicolor"
"90" 5.5 2.5 4 1.3 "versicolor"
"91" 5.5 2.6 4.4 1.2 "versicolor"
"92" 6.1 3 4.6 1.4 "versicolor"
"93" 5.8 2.6 4 1.2 "versicolor"
"94" 5 2.3 3.3 1 "versicolor"
"95" 5.6 2.7 4.2 1.3 "versicolor"
"96" 5.7 3 4.2 1.2 "versicolor"
"97" 5.7 2.9 4.2 1.3 "versicolor"
"98" 6.2 2.9 4.3 1.3 "versicolor"
"99" 5.1 2.5 3 1.1 "versicolor"
"100" 5.7 2.8 4.1 1.3 "versicolor"
"101" 6.3 3.3 6 2.5 "virginica"
"102" 5.8 2.7 5.1 1.9 "virginica"
"103" 7.1 3 5.9 2.1 "virginica"
"104" 6.3 2.9 5.6 1.8 "virginica"
"105" 6.5 3 5.8 2.2 "virginica"
"106" 7.6 3 6.6 2.1 "virginica"
"107" 4.9 2.5 4.5 1.7 "virginica"
"108" 7.3 2.9 6.3 1.8 "virginica"
"109" 6.7 2.5 5.8 1.8 "virginica"
"110" 7.2 3.6 6.1 2.5 "virginica"
"111" 6.5 3.2 5.1 2 "virginica"
"112" 6.4 2.7 5.3 1.9 "virginica"
"113" 6.8 3 5.5 2.1 "virginica"
"114" 5.7 2.5 5 2 "virginica"
"115" 5.8 2.8 5.1 2.4 "virginica"
"116" 6.4 3.2 5.3 2.3 "virginica"
"117" 6.5 3 5.5 1.8 "virginica"
"118" 7.7 3.8 6.7 2.2 "virginica"
"119" 7.7 2.6 6.9 2.3 "virginica"
"120" 6 2.2 5 1.5 "virginica"
"121" 6.9 3.2 5.7 2.3 "virginica"
"122" 5.6 2.8 4.9 2 "virginica"
"123" 7.7 2.8 6.7 2 "virginica"
"124" 6.3 2.7 4.9 1.8 "virginica"
"125" 6.7 3.3 5.7 2.1 "virginica"
"126" 7.2 3.2 6 1.8 "virginica"
"127" 6.2 2.8 4.8 1.8 "virginica"
"128" 6.1 3 4.9 1.8 "virginica"
"129" 6.4 2.8 5.6 2.1 "virginica"
"130" 7.2 3 5.8 1.6 "virginica"
"131" 7.4 2.8 6.1 1.9 "virginica"
"132" 7.9 3.8 6.4 2 "virginica"
"133" 6.4 2.8 5.6 2.2 "virginica"
"134" 6.3 2.8 5.1 1.5 "virginica"
"135" 6.1 2.6 5.6 1.4 "virginica"
"136" 7.7 3 6.1 2.3 "virginica"
"137" 6.3 3.4 5.6 2.4 "virginica"
"138" 6.4 3.1 5.5 1.8 "virginica"
"139" 6 3 4.8 1.8 "virginica"
"140" 6.9 3.1 5.4 2.1 "virginica"
"141" 6.7 3.1 5.6 2.4 "virginica"
"142" 6.9 3.1 5.1 2.3 "virginica"
"143" 5.8 2.7 5.1 1.9 "virginica"
"144" 6.8 3.2 5.9 2.3 "virginica"
"145" 6.7 3.3 5.7 2.5 "virginica"
"146" 6.7 3 5.2 2.3 "virginica"
"147" 6.3 2.5 5 1.9 "virginica"
"148" 6.5 3 5.2 2 "virginica"
"149" 6.2 3.4 5.4 2.3 "virginica"
"150" 5.9 3 5.1 1.8 "virginica"