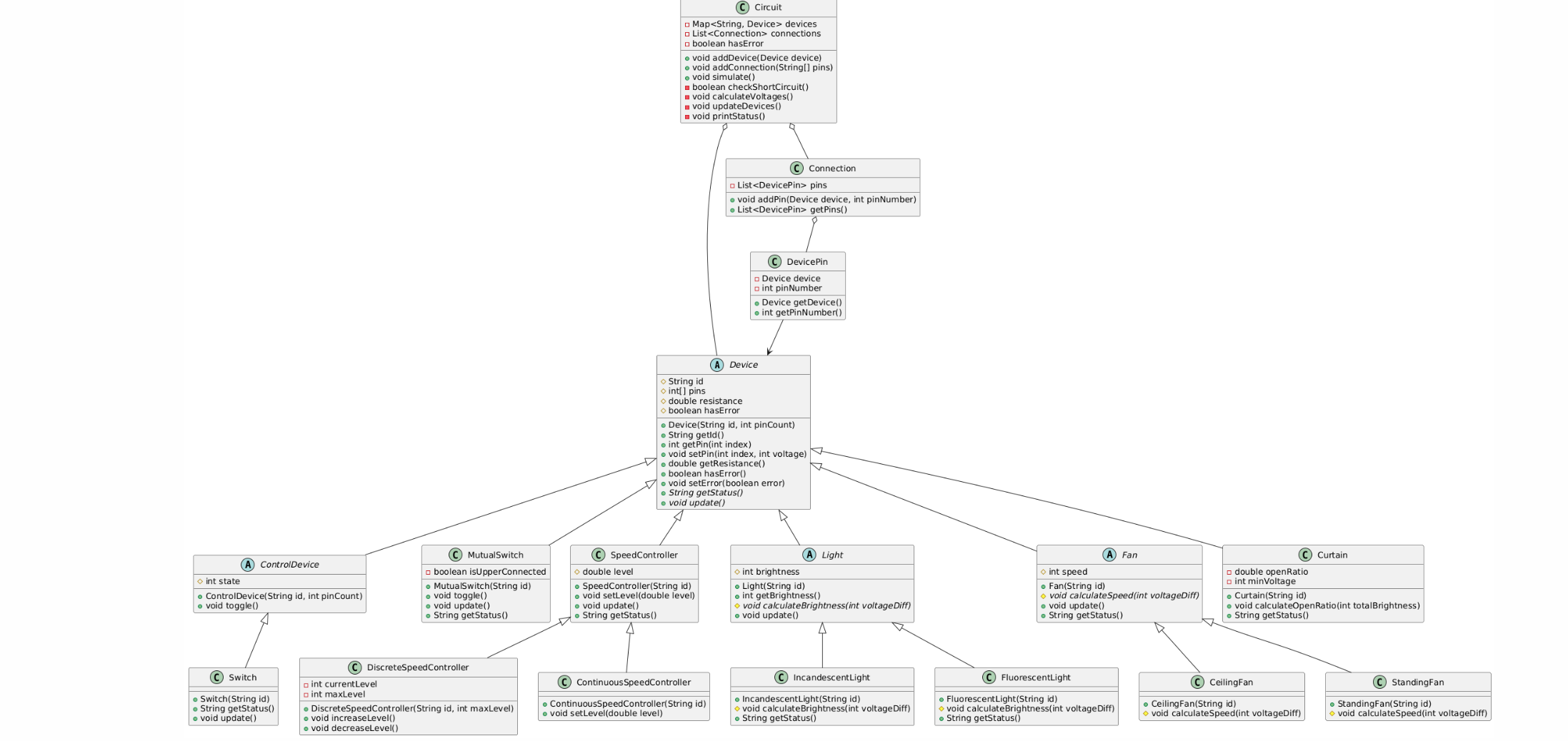
Java难绷知识01之对象流
本篇文章会探讨一些JavaIO流中比较容易被忽视的对象流,而且会相对的探讨其中的一些细节
其中对于对象流的操作讲解会少一些,主要讨论的是一些细节
在 Java IO 流中,对象流(ObjectInputStream对象输入流 和 ObjectOutputStream对象输出流)用于将对象进行序列化和反序列化操作
对象流及其序列化
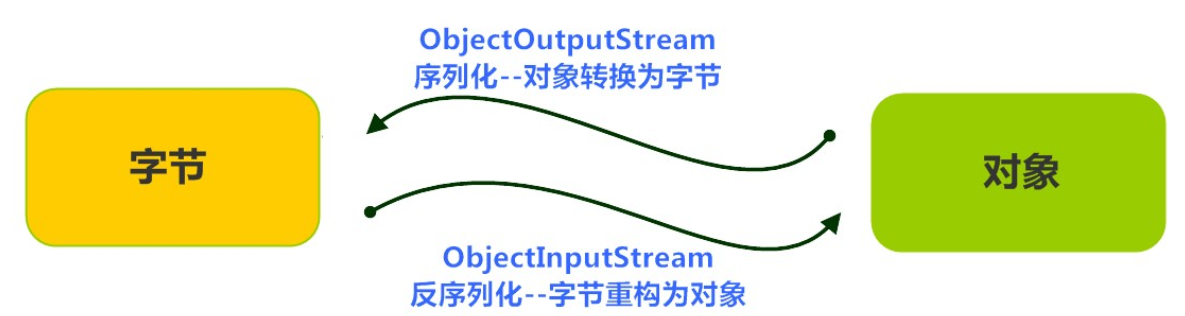
首先,ObjectInputStream和ObjectOutputStream这两个类都属于是字节流,它们分别继承自InputStream和OutputStream
对象输出流,ObjectOutputStream,用于对象的序列化,也就是把Java对象转换成字节序列,把字节序列写出到文件,以这种对象转换为字节序列的机制实现了对象存储
序列化目的是能够将整个 Java 对象(包括对象的状态,即成员变量的值)转换为字节流,以便在网络上传输或存储到文件中,之后还能稳定的从字节流中恢复出原来的对象。
通过序列化,对象的状态信息(包括成员变量的值)可以被保存下来,以便后续传输或存储。
对象输入流,ObjectInputStream,用于对象的反序列化,是将文件中的字节序列恢复为Java对象,以这种字节序列转换为对象的机制实现了对象读取
反序列化时,系统会根据字节流中的信息重新构建对象的状态。
在其基础上,我们再探讨序列化的一些细节
对象序列化的条件
要想使一个类的对象能够被序列化,该类必须实现 java.io.Serializable 接口
这是一个标记接口,没有任何方法需要实现。实现该接口,意味着告诉 Java 虚拟机这个类的对象可以被序列化。
点击查看代码
import java.io.*;// 定义一个实现Serializable接口的类
class Person implements Serializable {private static final long serialVersionUID = 1L;private String name;private int age;public Person(String name, int age) {this.name = name;this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}
}public class SerializationExample {public static void main(String[] args) {// 创建一个对象Person person = new Person("Alice", 30);// 序列化对象到文件try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.ser"))) {oos.writeObject(person);System.out.println("对象已成功序列化到文件 person.ser");} catch (IOException e) {e.printStackTrace();}// 从文件反序列化对象try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.ser"))) {Person deserializedPerson = (Person) ois.readObject();System.out.println("反序列化后的对象: " + deserializedPerson);} catch (IOException | ClassNotFoundException e) {e.printStackTrace();}}
}
注意:
每个可序列化的类都应该有一个serialVersionUID,用于验证序列化和反序列化过程中的版本兼容性
使用transient关键字声明的成员变量不会被序列化
序列化可能会引发安全问题
对象流的使用细节
对象流需要关闭吗
先说结论,可以不关
但是强烈建议关闭。这与 Java 流的资源管理机制紧密相关。
涉及到对外部资源的读写操作,包括网络、硬盘等等的I/O流,如果在使用完毕之后不关闭,会导致资源泄漏以及可能会引起文件锁定等问题。
当我们使用流进行数据操作时,它们会占用系统资源,如文件句柄、网络连接等。如果不关闭流,这些资源将不会被释放,可能导致资源泄漏问题。长时间运行的程序如果频繁出现资源泄漏,最终可能耗尽系统资源,导致程序崩溃或系统性能严重下降。
而且关闭流可以确保所有已写入的数据被正确地传输到目标位置
例如,当使用 ObjectOutputStream 将对象写入文件时,关闭流会保证缓冲区中的所有数据都被写入文件,避免数据丢失。
通常建议使用try - with - resources语句来自动关闭流
示例代码
import java.io.*;class MyClass implements Serializable {private static final long serialVersionUID = 1L;int data;public MyClass(int data) {this.data = data;}
}public class SerializeExample {public static void main(String[] args) {MyClass obj = new MyClass(42);try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("myfile.ser"))) {oos.writeObject(obj);} catch (IOException e) {e.printStackTrace();}}
}
对象流需要使用flush吗
先说结论,不用
ObjectOutputStream内部维护了一个缓冲区。在调用writeObject方法时,数据首先会被写入缓冲区。调用flush方法可以强制将缓冲区中的数据立即写入底层输出流。然而,在大多数情况下,并不需要显式调用flush。因为当缓冲区满、流关闭或者调用某些特定方法(如writeObject在某些情况下会触发缓冲区数据的刷新)时,缓冲区的数据会自动被写入底层流。
当然特意需要弄的时候可以弄
serialVersionUID在对象流中的必要性
凡是实现Serializable接口(标识接口)的类都有一个表示序列化版本标识符的静态常量:
private static final long serialVersionUID;
来表明类的不同版本间的兼容性。
在完成序列化操作后,如果对序列化对象进行了修改,那么我们再进行反序列化就会抛出InvalidClassException异常。 因为serialVersionUID缺失(没有显式分配)或者serialVersionUID发生了变化, serialVersionUID的作用在此体现——对序列化对象进行版本控制,有关各版本反序加化时是否兼容。避免混乱。
class Person implements Serializable {private static final long serialVersionUID = 1234567890123456789L;private String name;private int age;// 后续可以安全地对类结构进行一些兼容的修改
}
一个类在没有显示定义这个静态变量,它的值是Java运行时环境根据类的内部细节自动生成的。
若类的实例变量做了修改,serialVersionUID 可能发生变化。所以建议一般显式声明。
序列化的一些细节
static修饰的属性 不可以被序列化
原因在于 static 变量属于类,而不是类的实例。它们是类级别的共享数据,与对象的状态无关。
序列化的目的是保存对象的状态,所以 static 变量不会被包含在序列化的内容中。
class StaticExample implements Serializable {private static final long serialVersionUID = 1L;private static int sharedValue = 10;private int instanceValue;public StaticExample(int instanceValue) {this.instanceValue = instanceValue;}
}
当我们序列化 StaticExample 类的对象时,sharedValue 不会被序列化。
在反序列化时,sharedValue 的值将取决于类加载时的初始化状态,而不是序列化时的值
transient 修饰的属性不可以被序列化
transient 关键字用于标记那些不希望被序列化的属性。
这在某些场景下非常有用,比如当对象的某个属性包含敏感信息(如密码)或者该属性在反序列化后可以通过其他方式重新计算得到时。
class TransientExample implements Serializable {private static final long serialVersionUID = 1L;private String username;private transient String password;public TransientExample(String username, String password) {this.username = username;this.password = password;}
}
当对 TransientExample 对象进行序列化时,password 的值不会被写入序列化流。这样可以保护敏感信息,防止其在序列化过程中被泄露。在反序列化后,password 属性的值将为 null,程序可以重新设置该值。
对象序列化的作用
为什么JavaIO流要特意造出这么一个IO流
当你需要把对象写入到文件或者读取的时候,其实我们更多的情况通常是保存对象的有效值字段,也就是对象的具体实例的字段,那么使用文件操作流FileOutputStream和字符输出流BufferedWriter或PrintStream就足够。这些流可以用于处理文件写入和基本数据类型及字符串的输出,但对象序列化有着独特且不可替代的作用
网络传输对象
对象序列化机制是Java内建的一种对象持久化方式,可以很容易实现在JVM中的活动对象与字节流之间进行转换
在网络传输中,发送端将对象序列化成字节流,经过网络传输到网络的另一端,可以从字节流重新还原为对象,这个特点使得在进行端到端的网络传输数据时候,字节流和Java对象之间的转换稳定且快速。
在其中分布式系统中,不同的节点之间需要进行对象的传递,对象序列化使得这种对象传输变得简单直接,确保了对象在不同 Java 虚拟机之间的准确传输,即使这些 JVM 运行在不同的操作系统上。
RMI 是 Java 的一种远程方法调用机制,它允许一个 JVM 中的对象调用另一个 JVM 中的对象的方法。对象序列化也在其中起着关键作用
确保对象深层次的复制和持久化
当对一个对象进行序列化然后反序列化时,会得到一个与原对象状态完全相同但内存地址不同的新对象。可以实现在不影响原对象的情况下对对象进行操作,多线程下的数据处理的机制也有一定序列化和反序列化的影子。
这种情况对于远程创建对象副本并且调度的时候十分方便,而且不会干扰对象内部包含的复杂的引用关系,合理使用对象流可以大大提高程序处理复杂数据的能力。
在很多情况下,对象内部状态是需要被持久化的,序列化通过把对象写为字节流,保存的位置从JVM内存转移到文件系统,在需要的时候随时可以进行快速方便的还原
例如:在一个游戏中,可以使用对象流将玩家的游戏进度(一个复杂的对象,包含玩家角色信息、游戏关卡等)保存到文件中,下次玩家启动游戏时可以恢复到上次的进度。
对象流与其他流的关系
与字节流的关系
字符流是对象流的特例,它们处理的是字符数据的序列化和反序列化。
字符流(Reader 和 Writer 及其子类,如 BufferedReader、BufferedWriter 等)主要用于处理字符数据。Java 采用 Unicode 编码来表示字符,字符流对其的输入输出有优化。而且字符流在处理数据时,会根据指定的字符编码进行字节和字符之间的转换
而对象流可以将任何实现了 Serializable 接口的对象进行序列化和反序列化,意味着对象流操作的数据是复杂的对象结构,包括对象的成员变量、对象之间的引用关系。
与缓冲流的关系
功能叠加:缓冲流(如 BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter)的主要作用是提高数据读写的效率,通过在内存中设置缓冲区,减少实际的 I/O 操作次数。
对象流可以和缓冲流结合使用,以提升对象序列化和反序列化的性能。
可以将 ObjectOutputStream 包装在 BufferedOutputStream 中,这样在写入对象时,数据会先写入缓冲区,当缓冲区满或流关闭时,才会一次性将数据写入底层输出流,从而减少磁盘 I/O 操作的频率,提高写入效率。
在处理大量对象的序列化或反序列化时,结合缓冲流能显著提升性能。不过反序列化涉及到的种种安全关系,这种情况,讨论一下就好。
希望指点出需要补充的内容和问题,水平一般,需要大家的帮助才能更好