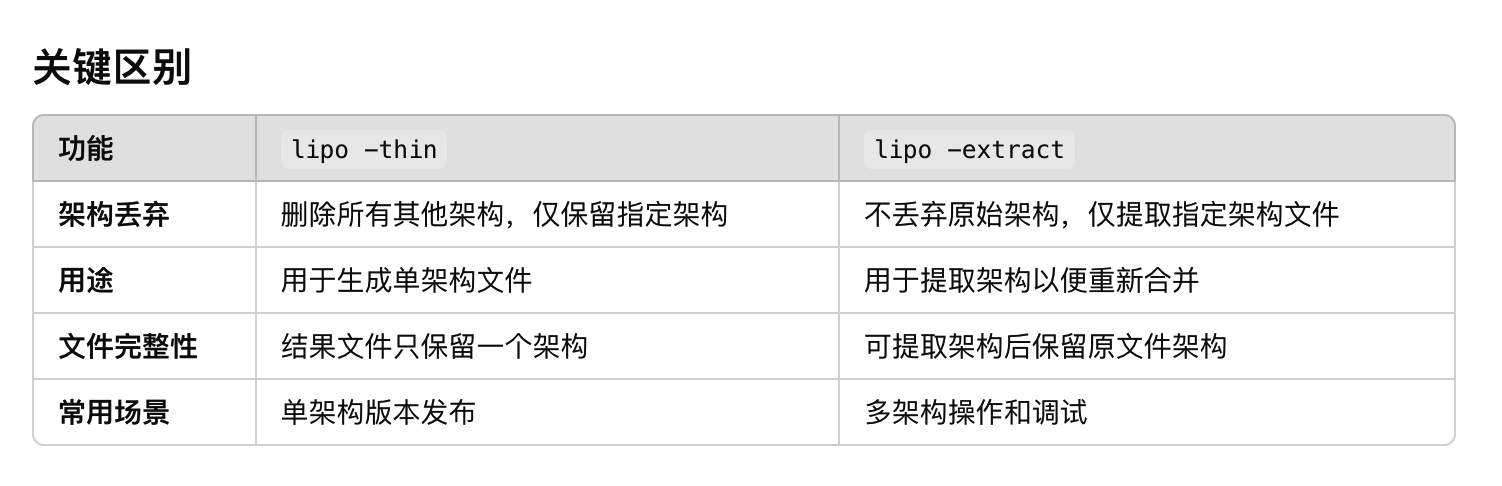
当专用模型超越通用模型时
“越大越好”——这个原则在人工智能领域根深蒂固。每个月都有更大的模型诞生,参数越来越多。各家公司甚至为此建设价值100亿美元的AI数据中心。但这是唯一的方向吗?
在NeurIPS 2024大会上,OpenAI联合创始人伊利亚·苏茨克弗提出了一个观点:“我们所熟知的预训练将无可争议地终结。”这表明大规模化的时代即将结束,现在是时候专注于改进当前的方法和算法了。
其中一个最有前景的领域是使用参数量不超过10B的小型语言模型(SLMs)。这种方法在行业内正逐步崭露头角。例如,Hugging Face的CEO克莱姆·德朗格预测,高达99%的应用场景可以使用SLMs来解决。类似的趋势也体现在YC对创业公司的最新需求中:
大规模的通用模型确实令人印象深刻,但它们也非常昂贵,常常伴随着延迟和隐私挑战。
在我上一篇文章《您真的需要托管的LLMs吗?》中,我探讨了是否需要自托管模型。现在,我进一步提出问题:您是否真的需要LLMs?

本文摘要
在本文中,我将探讨为何小型模型可能是您的业务所需的解决方案。我们将讨论它们如何降低成本、提高准确性并保持数据控制。当然,我们也会诚实地讨论它们的局限性。
成本效益
LLMs的经济学可能是企业最头疼的话题之一。但问题更广泛,包括昂贵的硬件需求、基础设施成本、能源消耗及环境后果。
是的,大型语言模型在能力上令人惊艳,但维护成本同样高昂。您可能已经注意到基于LLMs的应用程序订阅价格的上涨?例如,OpenAI最近宣布推出200美元/月的Pro计划,这表明成本正在增加。竞争对手也很可能会提高到类似价格水平。

200美元的Pro计划
Moxie机器人是一个很好的例子。Embodied公司开发了一款售价800美元的儿童伴侣机器人,使用了OpenAI API。尽管产品成功(孩子们每天发送500–1000条消息),但由于API的高运营成本,公司不得不关闭。现在,成千上万的机器人将变得无用,孩子们也会失去他们的朋友。
一种解决方案是为您的特定领域微调专用的小型语言模型。虽然不能解决“世界上所有问题”,但它可以完美应对特定任务。例如,分析客户文档或生成特定报告。同时,SLMs更经济,资源消耗更少,所需数据更少,可以运行在更普通的硬件上(甚至是智能手机上)。

不同参数模型的利用率对比
最后,不要忘了环境因素。在《碳排放与大规模神经网络训练》一文中,我发现了一些令人震惊的统计数据:训练拥有1750亿参数的GPT-3所耗电量相当于美国普通家庭120年的用电量,同时产生502吨二氧化碳,相当于超过100辆汽油车一年的排放。而这还不包括推理成本。相比之下,部署一个更小的7B模型仅需大模型消耗的5%。那么最新的o3模型呢?

模型 o3 的二氧化碳排放量。
💡提示:不要盲目追赶潮流。在解决任务之前,计算API或自建服务器的使用成本。思考这种系统的扩展性以及使用LLMs是否合理。
专用任务上的性能
现在我们已经讨论了经济学问题,接下来说说质量。当然,很少有人愿意仅仅为了节约成本而牺牲解决方案的准确性。但即使在这方面,SLMs也有其优势。

领域内内容审核的表现
比较SLMs与LLMs在领域内内容审核的准确率、召回率和精确率。最佳表现的SLMs在准确率和召回率上超过了LLMs,而LLMs在精确率上表现更佳。
许多研究表明,对于高度专业化的任务,小型模型不仅能与大型LLMs竞争,甚至经常超越它们。以下是几个具有代表性的例子:
- 医学领域
Diabetica-7B模型(基于Qwen2-7B)在糖尿病相关测试中达到了87.2%的准确率,而GPT-4为79.17%,Claude-3.5为80.13%。尽管如此,Diabetica-7B的规模远小于GPT-4,可以在消费级GPU上本地运行。
- 法律领域
一个仅有0.2B参数的SLM在合同分析中达到了77.2%的准确率(GPT-4约为82.4%)。此外,在识别用户协议中的“不公平”条款等任务中,SLM在F1指标上甚至优于GPT-3.5和GPT-4。
- 数学任务
谷歌DeepMind的研究表明,将一个小型模型Gemma2-9B训练在另一个小型模型生成的数据上,比在更大模型Gemma2-27B的数据上训练效果更好。小型模型往往能更专注于细节,而不会像大模型那样“试图展现全部知识”。
- 内容审核
LLaMA 3.1 8B在15个热门subreddits的内容审核中,准确率提高了11.5%,召回率提高了25.7%,超过了GPT-3.5。这是通过4位量化实现的,这进一步减少了模型的规模。

用于PubMedQA的领域内SLM与LLMs的对比
更进一步地说,即使是传统的自然语言处理方法也往往表现出色。让我分享一个实际案例:我正在开发一款心理支持产品,每天处理用户发送的超过1000条消息。这些消息会被分类到以下四个类别之一:

消息分类方案
• SUPPORT:关于应用如何工作的提问;我们用文档中的内容回答。
• GRATITUDE:用户感谢机器人;我们简单地发送一个“点赞”。
• TRY_TO_HACK:用户请求与应用目的无关的内容(如“用Python写一个函数”)。
• OTHER:其他所有消息,将进一步处理。
起初,我使用GPT-3.5-turbo进行分类,后来切换到GPT-4o mini,花费了大量时间调整提示词,但仍然遇到错误。于是我尝试了传统方法:TF-IDF + 简单分类器。训练时间不到一分钟,宏观F1分数从GPT-4o mini的0.92提高到0.95。模型大小仅为76MB,并且在处理我们实际的200万条消息数据时,节省的成本非常显著:基于GPT的解决方案大约花费500美元,而传统方法几乎不需要成本。

GPT-4o mini与TF-IDF模型的准确率、速度和成本对比表
在我们的产品中,还有几项类似的“小型”简单任务。我相信您的公司也能找到类似的场景。当然,大型模型对于快速启动非常有用,特别是当没有标注数据且需求不断变化时。但对于定义明确、稳定的任务,且准确性和最低成本是关键的场景,专用的简单模型(包括传统方法)通常更为有效。
💡提示:使用LLMs进行原型设计,然后当任务明确且稳定时,切换到更小、更便宜、更准确的模型。这种混合方法有助于保持高质量,同时显著降低成本,避免通用模型的冗余。
安全性、隐私性与合规性
通过API使用LLMs,您实际上将敏感数据交给了外部提供商,这增加了泄露的风险,并使遵守HIPAA、GDPR和CCPA等严格法规变得更加复杂。OpenAI最近宣布计划引入广告,这进一步突显了这些风险。您的公司不仅失去了对数据的完全控制,还可能依赖于第三方的服务等级协议(SLAs)。
当然,也可以本地运行LLMs,但部署和扩展的成本(数百GB内存、多块GPU)通常超出了合理的经济范围,也难以快速适应新的监管要求。而在低端硬件上运行LLMs更是难以实现。

云端API风险与设备端SLM优势的对比。
这是小型语言模型(SLMs)发挥优势的地方:
- 简化审计
SLMs的较小规模降低了审计、验证和定制以满足特定法规的门槛。您可以更容易理解模型如何处理数据,实现自定义加密或日志记录,并向审计员证明信息从未离开受信任的环境。作为一家医疗公司创始人,我深知这项任务的挑战和重要性。
- 在隔离和低端硬件上运行
LLMs很难高效地“部署”在隔离的网络环境或智能手机上。而SLMs因计算需求较低,可以几乎在任何地方运行:从私人网络中的本地服务器,到医生或检查员的设备。根据IDC的预测,到2028年,超过9亿部智能手机将具备本地运行生成式AI模型的能力。
- 应对新法规的更新与适应
法规和法律经常变化——紧凑的模型可以在数小时内完成微调或调整,而不是数天。这使得企业能够快速响应新要求,无需进行大规模的基础设施升级,这通常是大型LLMs的特征。
- 分布式安全架构
与LLMs的一体化架构不同,其中所有安全组件都“内嵌”到一个大型模型中,SLMs允许创建分布式安全系统。每个组件:
o 专注于特定任务。
o 可独立更新和测试。
o 可与其他组件独立扩展。
例如,一个医疗应用程序可以使用由三个模型组成的级联架构:
• 隐私保护器(2B参数):屏蔽个人数据。
• 医学验证器(3B参数):确保医学准确性。
• 合规性检查器(1B参数):监控HIPAA合规性。
小型模型更容易验证和更新,使整体架构更加灵活可靠。

数据隐私功能对比表
💡提示:如果您的行业受严格监管(如医疗、金融或法律领域),请考虑使用SLMs。特别关注数据传输政策以及法规变化的频率。
AI智能体:完美的应用场景
还记得老式Unix哲学“专注做好一件事”吗?现在看来,我们正在将这一原则应用到AI中。
伊利亚·苏茨克弗在NeurIPS上的最新声明指出,“我们所熟知的预训练将无可争议地终结”,下一代模型将“以真正的方式具备智能体性”。这一趋势表明AI正向更细化、更专业化的方向发展。Y Combinator更进一步预测,AI智能体可能创造出比SaaS大10倍的市场。
例如,目前已有12%的企业解决方案采用基于智能体的架构。此外,分析师预测智能体将成为AI转型的下一波浪潮,不仅会影响4000亿美元的软件市场,还将影响10万亿美元的美国服务业经济。
SLMs是这些智能体的理想候选者。虽然单一模型功能有限,但一群这样的模型——可以逐步解决复杂任务。更快、更高质量且成本更低。

信息流示例:专用智能体之间的任务分配
这种方法不仅更加经济,还更加可靠:每个智能体专注于自己最擅长的部分。更便宜、更快、更好。是的,我再强调一次。
以下是一些支持这一点的公司案例:
-
H公司:在种子轮融资中筹集了1亿美元,用于开发基于SLMs(2–3B参数)的多智能体系统。他们的智能体Runner H(3B)在任务完成成功率上达到67%,相比之下,Anthropic的Computer Use仅为52%,而成本显著更低。
-
Liquid AI:最近获得了2.5亿美元资金,专注于构建高效的企业模型。他们的1.3B参数模型在同类规模模型中表现最佳。同时,他们的LFM-3B模型在性能上与7B甚至13B模型相当,但所需内存更少。
-
Cohere:推出了Command R7B,一个用于RAG(检索增强生成)应用的专用模型,甚至可以在CPU上运行。该模型支持23种语言,并能与外部工具集成,在推理和问答任务中表现最佳。
-
贵公司名称:也可以加入这一名单。在我工作的Reforma Health公司中,我们正在为不同的医疗领域开发专用的SLMs。这一决策是基于遵守HIPAA要求及医疗信息处理的特殊需求而做出的。我们的经验表明,高度专业化的SLMs在受监管领域中可以成为显著的竞争优势。
这些案例表明:
• 投资者看好专用小型模型的未来。
• 企业客户愿意为无需向外部提供商发送数据的高效解决方案买单。
• 市场正从依赖“通用”大模型向“智能”专用智能体转变。
💡提示:首先识别项目中重复性高的任务。这些任务是开发专用SLM智能体的最佳候选者。这样可以避免为LLMs的过剩能力支付过高的费用,同时获得更高的流程控制能力。
SLMs与LLMs的局限性对比
尽管本文一直在赞扬小型模型,但公平起见,也必须指出它们的局限性:
- 任务灵活性有限
SLMs的最大局限在于其窄化的专业性。与LLMs不同,SLMs只能在其训练的特定任务中表现出色。例如,在医学领域,Diabetica-7B在糖尿病测试中表现优异,但其他医疗学科需要额外微调或新的架构。

LLMs与SLMs:灵活性与专业性的对比
- 上下文窗口限制
与上下文长度可达1M tokens(如Gemini 2.0)的大型模型相比,SLMs的上下文较短。尽管最新的小型LLaMA 3.2模型(3B、1B)支持128k tokens的上下文长度,但实际效果往往不如预期:模型常常无法高效连接文本开头和结尾。例如,SLMs无法高效处理长达数年的患者病史或大篇幅的法律文档。

不同模型最大上下文长度对比
- 涌现能力差距
许多“涌现能力”只有在模型达到一定规模阈值时才会出现。SLMs通常达不到参数水平以支持高级逻辑推理或深度上下文理解。谷歌研究的研究表明,在数学文字题中,小型模型难以处理基本算术,而大型模型则突然表现出复杂的数学推理能力。
不过,Hugging Face的最新研究表明,通过测试时的计算扩展可以部分弥补这一差距。使用迭代自我优化或奖励模型等策略,小型模型可以“更长时间地思考”复杂问题。例如,在扩展生成时间后,小型模型(1B和3B)在MATH-500基准上超过了其更大的对手(8B和70B)。
💡提示:如果您的任务环境经常变化,需要分析大规模文档,或涉及复杂逻辑问题,大型LLMs往往更可靠和通用。
总结与结论
就像我在上一篇文章《在OpenAI和自托管LLMs之间的选择》中讨论的那样,这里也没有放之四海而皆准的解决方案。如果您的任务涉及持续变化、缺乏明确的专业化或需要快速原型设计,LLMs提供了一个轻松的起点。
然而,随着您的目标逐渐明确,转向紧凑、专用的SLM智能体可以显著降低成本,提高准确性,并简化遵守监管要求的流程。

从LLM的快速原型设计到优化的SLM智能体生态系统的迁移
SLMs不是为了追求潮流而提出的颠覆性范式,而是一种务实的方法。它能够更准确、更具成本效益地解决特定问题,而无需为不必要的功能支付额外费用。您不需要完全抛弃LLMs——您可以逐步将部分组件替换为SLMs,甚至是传统的NLP方法。这一切取决于您的指标、预算和任务的性质。
一个很好的例子是IBM,他们采用了多模型策略,将不同任务分配给较小的模型。正如他们所指出的:
“更大并不总是更好,专用模型在基础设施需求更低的情况下表现优于通用模型。”
最终,成功的关键在于适应性。从一个大型模型开始,评估其最佳表现的领域,然后优化您的架构,以避免为不必要的功能支付过高的费用,同时保持数据隐私。这种方法允许您结合两者的优势:LLMs在初期阶段的灵活性和通用性,以及成熟产品阶段SLMs的精准性和高性价比。
关键提示总结
- 不要追赶潮流
在解决任务之前,计算使用API或自建服务器的成本,并分析是否需要LLMs。
- 混合方法
在原型阶段使用LLMs,等任务明确和稳定后切换到更小、更便宜的模型。
- 专注于小任务
识别重复性高的任务,并开发专用SLM智能体。
- 重视隐私和合规性
如果您处于高度受监管的领域(如医疗、金融或法律),请优先考虑SLMs以降低数据泄露风险并快速适应监管变化。
- 以需求为中心
大模型适用于任务多变、文档处理量大或逻辑复杂的场景。SLMs适用于稳定、专用的任务或对成本敏感的场景。