学号后四位:3018
9.2:
点击查看代码
import numpy as np
from scipy.stats import shapirodata = np.array([15.0, 15.8, 15.2, 15.1, 15.9, 14.7, 14.8, 15.5, 15.6, 15.3,15.1, 15.3, 15.0, 15.6, 15.7, 14.8, 14.5, 14.2, 14.9, 14.9,15.2, 15.0, 15.3, 15.6, 15.1, 14.9, 14.2, 14.6, 15.8, 15.2,15.9, 15.2, 15.0, 14.9, 14.8, 14.5, 15.1, 15.5, 15.5, 15.1,15.1, 15.0, 15.3, 14.7, 14.5, 15.5, 15.0, 14.7, 14.6, 14.2])statistic, p_value = shapiro(data)
alpha = 0.05
if p_value > alpha:print("滚珠直径服从正态分布")
else:print("滚珠直径不服从正态分布")
print("统计量:", statistic)
print("p - 值:", p_value)
print("xuehao3018")

9.3:
点击查看代码
import numpy as np
import matplotlib.pyplot as pltdata = np.array([[4.13, 3.86, 4.00, 3.88, 4.02, 4.02, 4.00],[4.07, 3.85, 4.02, 3.88, 3.95, 3.86, 4.02],[4.04, 4.08, 4.01, 3.91, 4.02, 3.96, 4.03],[4.07, 4.11, 4.01, 3.95, 3.89, 3.97, 4.04],[4.05, 4.08, 4.04, 3.92, 3.91, 4.00, 4.10],[4.04, 4.01, 3.99, 3.97, 4.01, 3.82, 3.81],[4.02, 4.02, 4.03, 3.92, 3.89, 3.98, 3.91],[4.06, 4.04, 3.97, 3.90, 3.89, 3.99, 3.96],[4.10, 3.97, 3.98, 3.97, 3.99, 4.02, 4.05],[4.04, 3.95, 3.98, 3.90, 4.00, 3.93, 4.06]
])fig, ax = plt.subplots()
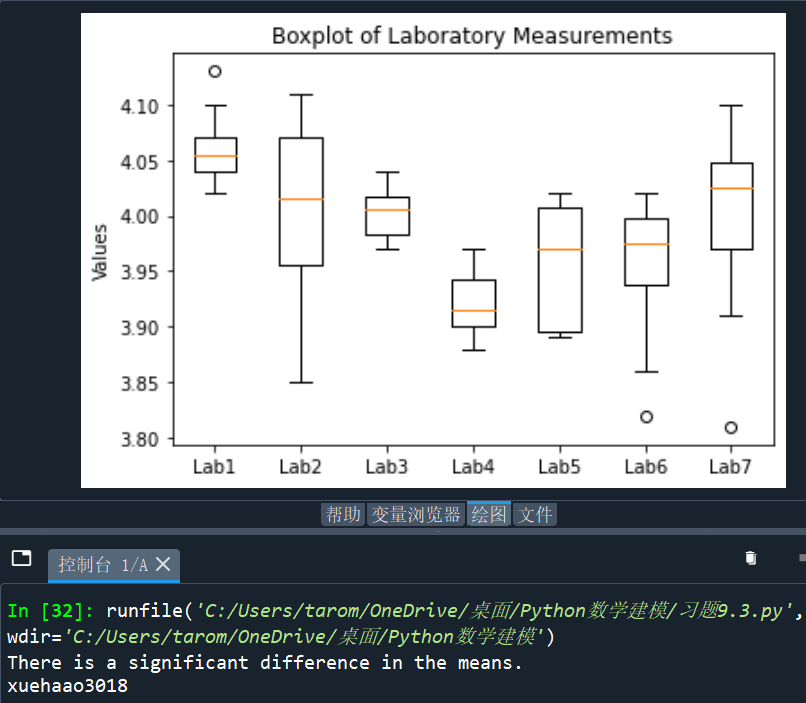
ax.boxplot(data)
ax.set_xticklabels(['Lab1', 'Lab2', 'Lab3', 'Lab4', 'Lab5', 'Lab6', 'Lab7'])
ax.set_ylabel('Values')
ax.set_title('Boxplot of Laboratory Measurements')
plt.show()from scipy.stats import f_onewaydata = np.array([[4.13, 3.86, 4.00, 3.88, 4.02, 4.02, 4.00],[4.07, 3.85, 4.02, 3.88, 3.95, 3.86, 4.02],[4.04, 4.08, 4.01, 3.91, 4.02, 3.96, 4.03],[4.07, 4.11, 4.01, 3.95, 3.89, 3.97, 4.04],[4.05, 4.08, 4.04, 3.92, 3.91, 4.00, 4.10],[4.04, 4.01, 3.99, 3.97, 4.01, 3.82, 3.81],[4.02, 4.02, 4.03, 3.92, 3.89, 3.98, 3.91],[4.06, 4.04, 3.97, 3.90, 3.89, 3.99, 3.96],[4.10, 3.97, 3.98, 3.97, 3.99, 4.02, 4.05],[4.04, 3.95, 3.98, 3.90, 4.00, 3.93, 4.06]
])lab1, lab2, lab3, lab4, lab5, lab6, lab7 = [data[:, i] for i in range(7)]
f_statistic, p_value = f_oneway(lab1, lab2, lab3, lab4, lab5, lab6, lab7)alpha = 0.05
if p_value < alpha:print("There is a significant difference in the means.")
else:print("There is no significant difference in the means.")
print("xuehaao3018")
9.4:
点击查看代码
import numpy as np
import statsmodels.api as smy = np.loadtxt('ti9_4.txt',encoding='utf-8').flatten()
x1 = np.tile(np.arange(1,4), (12, 1)).T.flatten()
x2 = np.tile(np.hstack([np.ones(3), 2 * np.ones(3), 3 * np.ones(3),
4 * np.ones(3)]), (3, 1)).flatten()
d = {'x1':x1, 'x2':x2, 'y':y}
md = sm.formula.ols('y~C(x1) * C(x2)', d).fit()
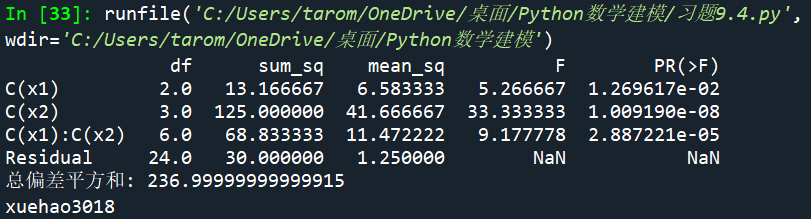
ano = sm.stats.anova_lm(md)
print(ano); print('总偏差平方和:', sum(ano.sum_sq))
print("xuehao3018")
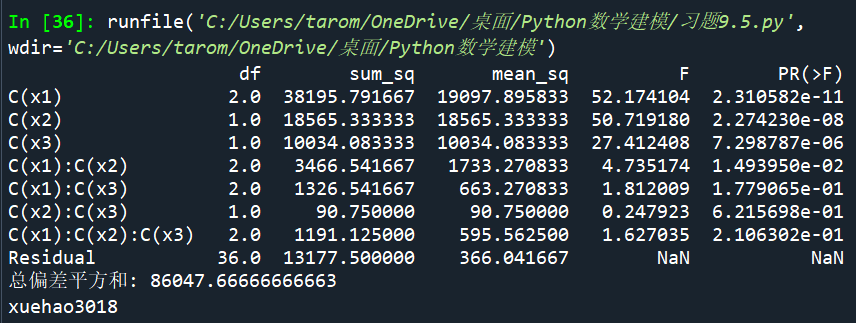
9.5:
点击查看代码
import numpy as np
import statsmodels.api as smy = np.loadtxt('ti9_5.txt').T.flatten()
x1 = np.tile(np.hstack([np.ones(4), 2 * np.ones(4), 3 * np.ones(4)]), (4, 1)).flatten()
x2 = np.tile(np.tile([1, 1, 2, 2], (1, 3)), (4, 1)).flatten()
x3 = np.tile(np.tile([1, 2], (1, 6)), (4, 1)).flatten()
d = {'x1': x1, 'x2': x2, 'x3': x3, 'y': y}
md = sm.formula.ols('y ~ C(x1) * C(x2) * C(x3)', d).fit()
ano = sm.stats.anova_lm(md)
print(ano)
print('总偏差平方和:', sum(ano.sum_sq))
print("xuehao3018")