记录一下目前综合时遇到的一点小问题。
目前的设计的计算模块里大量使用了DW IP,包括浮点除法器,浮点加减法器,浮点乘法器,浮点求根器,浮点比较器等每个各32个,直接综合的话会发现这些大的计算单元每个都需要进行mapping,会导致综合的总时长长的难以想象(可能需要数天的时间)。
分析其原因,主要就是尽管对DW IP进行了重复例化,但在综合时实际上由于每个的env被视作不同,所以都会被独立进行mapping和optimization,导致总时间变得离谱。所以解决思路也很简单,进行层次化的综合,先把要用到的DW IP给单独综合为网表,在整体大模块中直接调用已经综合好的网表进行再综合(同时要注意对模块设置set_dont_touch属性,避免工具再去优化已经综合好的网表,经过实践发现,如果不加的话时间一样会长的离谱)。
对DW IP进行独立综合时,可以在其外部包裹wrapper提升设计时调用的便捷性,在约束时给一个相对而言比较紧的时序约束,来确保后续的综合可以通过。
以我这里的一个浮点除法器为例:
// float point divider
module fp_div (input wire [31:0] i1,input wire [31:0] i2,output wire [31:0] o
);parameter sig_width = 23;
parameter exp_width = 8;
parameter ieee_compliance = 0;DW_fp_div # (sig_width,exp_width,ieee_compliance
) u_DW_fp_div (.a(i1),.b(i2),.rnd(3'b000),.z(o),.status()
);endmodule
目标是跑上400MHz,对应2.5ns周期,在约束时适当加紧,最后达到了1.37ns的最大组合传播延时。
随后综合产生网表:
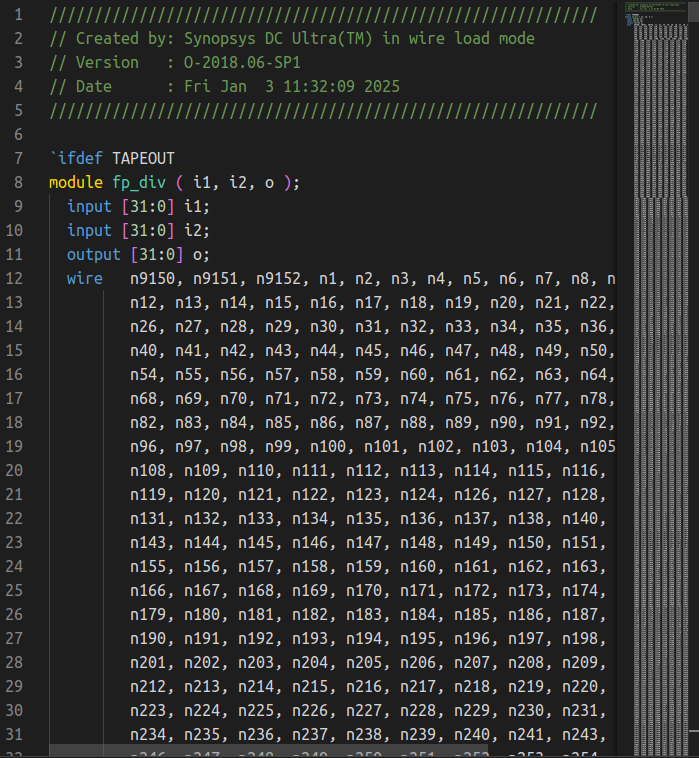
在顶层模块综合时,直接读入该文件即可。
此外需要对该模块进行set_dont_touch,我将其写到了sdc中,通过set_dont_touch [get_references u_xxxx/u_xxxx/fp_div*]完成约束,这里需要注意get_references命令在执行时必须要符合设计的层次,确保能够找到所有的fp_div的例化模块。
至此层次化综合的设置全部完成,再次运行综合之后,发现综合速度极大提升,从原来的可能需要数天时间,直接加快到二十分钟左右就结束。
该思路对于其他需要以网表的形式做集成的IP也都是适用的,层次化的综合也有利于减小整体的综合时间以及减小机器的资源需求,是个挺有用的trick。