`'''
这是一个简单的文本分类任务,基本的流程步骤还是挺清晰完整的,和之前那个简单的cnn差不多,
用到了transformers包,还需用到huggingface的模型rbt3,
但是好像连接不上``
'''
'''
遇到的问题:
1.导入的包不可用,从AutoModelForTokenClassification换成了AutoModelForSequenceClassification
2.模型加载不出来,然后选择将模型下载到本地进行加载,但是这样的话会非常耗内存,后续考虑设置一个代理
3.数据处理的问题,在处理完数据,进行训练的时候,没有处理好设备选择问题,导致部分数据在cpu,部分数据在gpu
'''
step1 导入相关包
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
step2 加载数据
import pandas as pd
data = pd.read_csv("./ChnSentiCorp_htl_all.csv")
data = data.dropna()
step3 创建Dataset
from torch.utils.data import Dataset
class MyDataset(Dataset):
def init(self):
super().init()
self.data = pd.read_csv("./ChnSentiCorp_htl_all.csv")
self.data = self.data.dropna()
def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]def __len__(self):return len(self.data)
dataset = MyDataset()
step4 划分数据集
from torch.utils.data import random_split
trainset, validset = random_split(dataset, lengths=[0.9, 0.1])
step5 创建Dataloader
tokenizer = AutoTokenizer.from_pretrained("./hfl/rbt3")
def collate_func(batch): # 自定义的数据合并函数,负责将一个批次(batch)的文本和标签进行处理
texts, labels = [], []
for item in batch:
texts.append(item[0])
labels.append(item[1])
inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")
# 确保把所有输入移到正确的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
inputs = {key: value.to(device) for key, value in inputs.items()}
inputs["labels"] = torch.tensor(labels).to(device) # labels 也移到相同设备
return inputs
from torch.utils.data import DataLoader
trainloader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=collate_func)
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_func)
step6 创建模型及优化器
from torch.optim import Adam
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModelForSequenceClassification.from_pretrained("./hfl/rbt3").to(device)
optimizer = Adam(model.parameters(), lr=2e-5)
step7 训练与验证
def evaluate():
model.eval() # 设置模型为评估模式
acc_num = 0
# 打印模型设备信息(只在验证开始时打印一次)
print(f"验证开始:\n模型设备: {next(model.parameters()).device}")
with torch.no_grad():
for batch in validloader:
batch = {k: v.to(device) for k, v in batch.items()} # 将数据移到指定设备
# 只需要在第一次 batch 时打印一次输入数据设备信息
if acc_num == 0:
print(f"输入数据设备: {batch['input_ids'].device}")
output = model(**batch)
pred = torch.argmax(output.logits, dim=-1)
acc_num += (pred.long() == batch["labels"].long()).float().sum()
return acc_num / len(validset)
def train(epoch=1, log_step=100):
global_step = 0
for ep in range(epoch):
model.train() # 设置模型为训练模式
# 打印模型和输入数据设备信息(只在每个 epoch 开始时打印一次)
print(f"Epoch {ep} 开始:")
print(f"模型设备: {next(model.parameters()).device}")
for batch in trainloader:
batch = {k: v.to(device) for k, v in batch.items()} # 移动到正确设备
# 只需要在第一次 batch 时打印一次输入数据设备信息
if global_step == 0:
print(f"输入数据设备: {batch['input_ids'].device}")
optimizer.zero_grad()
output = model(**batch)
output.loss.backward()
optimizer.step()
if global_step % log_step == 0:
print(f"ep:{ep}, global_step:{global_step}, loss:{output.loss.item()}")
global_step += 1
acc = evaluate() # 调用evaluate函数
print(f"ep:{ep}, acc:{acc}")
step8 模型训练
train()
step9 模型预测
sen = "我觉得这家酒店真不错,饭很好吃!"
id2_label = {0: "差评", 1: "好评"}
model.eval()
with torch.no_grad():
inputs = tokenizer(sen, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()} # 确保输入在正确的设备
# 只在预测开始时打印一次设备信息
print(f"预测开始:\n模型设备: {next(model.parameters()).device}")
print(f"输入数据设备: {inputs['input_ids'].device}")
logits = model(**inputs).logits
pred = torch.argmax(logits, dim=-1)
print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")
更简单的做法
from transformers import pipeline
model.config.id2label = id2_label
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0 if torch.cuda.is_available() else -1)
print(pipe(sen))
`
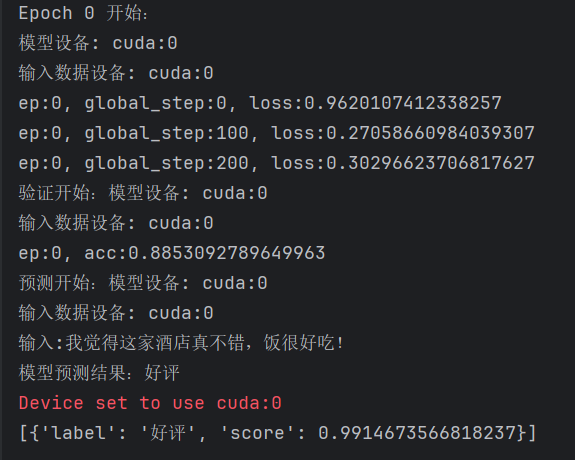
最终运行的结果是这样的: