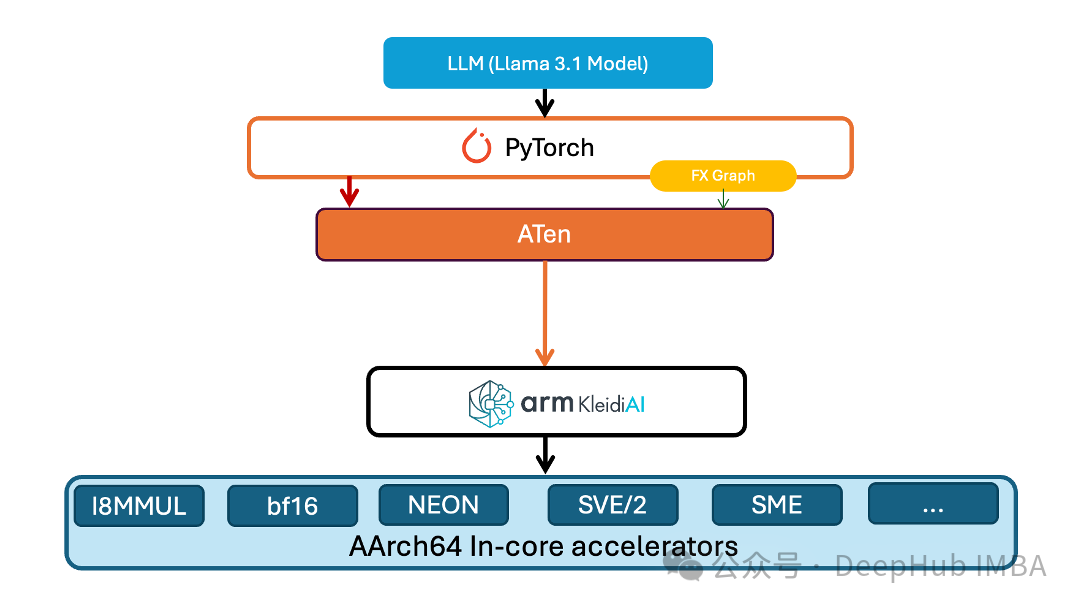
在深度学习模型部署和优化领域,计算效率与资源消耗的平衡一直是一个核心挑战。PyTorch团队针对这一问题推出了创新性的技术方案——在其原生低精度计算库TorchAO中引入低位运算符支持。这一技术突破不仅实现了1至8位精度的嵌入层权重量化,还支持了具有8位动态量化激活的线性运算符,为解决资源受限环境下的深度学习计算难题提供了有效解决方案。
这项技术创新的重要性体现在其全面的框架支持上。通过精心的架构设计,新的低位运算符实现了与PyTorch生态系统各个关键组件的无缝集成,包括即时执行模式(eager execution)、torch.compile编译优化框架、预先推理技术(AOTI)以及面向边缘计算的ExecuTorch。这种全方位的技术覆盖确保了开发者能够在各种应用场景中充分利用低位计算带来的性能优势。
通用低位计算内核的技术创新
在深度学习硬件加速领域,低位计算面临的最大挑战之一是缺乏直接的硬件支持。PyTorch团队通过创新的架构设计巧妙地解决了这个问题。他们采用了高度模块化的设计理念,将低位值解包操作与核心GEMV(通用矩阵-向量乘法)计算逻辑分离,这种解耦不仅提高了代码的可维护性,更为不同精度配置下的计算优化提供了灵活的实现路径。
在具体的技术实现中,团队开发的8位GEMV内核展现了卓越的架构设计。该内核充分利用了Arm架构的NeonDot指令集的并行计算能力,通过实现强制内联的解包例程,高效完成从低位值到int8的精确转换过程。这种模块化设计的优势在于,它实现了位打包逻辑的高度复用,使得同一套核心逻辑可以同时服务于线性计算和嵌入层计算,显著降低了开发成本和维护难度。
https://avoid.overfit.cn/post/384c1c6813dd4c46871e9ac0772db350