前序树(Trie/Prefix tree),它的一个典型的应用场景在搜索引擎里,当你输入查询关键字的时候,会联想自动补齐你想要输入的内容。比如,你输入app,下面可能会出来联想Apple, Applied等等。
什么是Trie?
Trie(读作Try)是这样一个数据结构,它把短语或者单词分解字母,然后以一种方式去存储,让添加、删除、查找或者自动补齐短语/单词更高效。
我们看一个例子:
1. 开始我们有一个空的根节点
*
2. 我们想把apple存放进来
2.1 *
a
p
p
l
e (The end of our phase or word!)
3. 把cat,dog加进来
3.1 *
a c d
p a o
p t g
l
e
4. 把duck加进来,d作为了dog和duck公共的前序字母
4.1 *
a c d
p a o u
p t g c
l k
e
5. 把dune和monk,monkey加进来
5.1 *
a c d m
p a o u o
p t g c n n
l k e k
e e
y
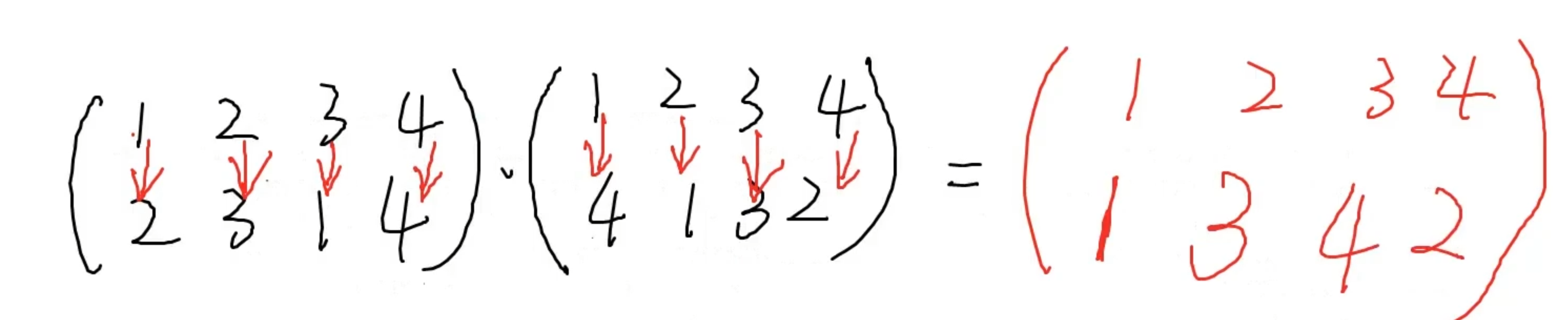
上面的前序树里,我们有apple,app,cat,dog,duck,dune,monkey,monk。
查找单词:
1. 我们要查找eagle,首先我们把eagle拆解成e,a,g,l,e,我们看e是不是在根节点的孩子节点里。这里我们并没有e,所以我们可以停止搜索,告知eagle不在我们树里。
2. 我们要查找monk,过程是一样的,把monk拆解成m,o,n,k,看m在不在孩子节点,这里m是其中一个孩子节点,所以继续往下找o,同样也能找到,可以看到,我们这里查找的时候就关注在m,o这条分支上,继续往下,n,k可以都找到。
2.1 如果我们是要看完整的单词是否存在,那我们要看最后一个字母是不是单词的结尾,monk的例子上,我们看到k是被标记为结尾的,所以monk是一个完整的单词。
2.2 如果我们是看prefix是否存在,那么我们不需要看最后一个字母是不是单词结尾,monk是存在的,同样的m,mo,mon也都是存在的。
删除单词:
如果我们要删除单词,我们不能简单的把这个单词的字母删掉,因为这个单词的字母有可能是和其他单词共用了前缀。
1. 查找要删除的单词在我们前序树里存在
2. 如果单词的某个字母是和其他单词共享的,那不能删除。比如要删除duck,d是和dog,dune共享的,u是和dune共享的
3. 我们要删除的单词不是另一个单词的子集
所以我们这样删:
把我们要删除的单词解散成字母,然后反相删除。从最后一个字母开始,看这个字母是否和其他单词共享,或者是其他单词的一部分,如果都不是,则把这个字母删除,然后相同的方法,查看前一个字母,直到字母和其他单词共享则停止。
我们删除duck后的前序树是这个样子:d,u还在,因为和其他单词共用,c,k被删除了。
*
a c d m
p a o u o
p t g n n
l e k
e e
y
前序树应用场景:
前序树应用,直接的例子,对于我们上面的前序树,加入你输入d,它会快速返回给你dog,duck,dune作为你可能要查找的目标。
1. 自动补齐或者预测文字:比如在搜索引擎,message app,email client,我们常会看到自动提示,或者自动补齐的功能;
2. 拼写检查和矫正:前序树可以用于存储字典,从而帮助查找和建议正确的单词;当一个不正确的字母输入时,我们可以回退几步,给出可能正确的单词选项;
3. IP路由和网络路由表:前序树中每个节点表示ip的一部分,子节点表示剩下部分可能的值,遍历前序树,路由器可以查看下一个hop;
4. 单词游戏:Wordle。
代码实现(javascript)
我们将要实现一下功能:
1. 插入一个单词
2. 查找一个单词是否存在
3. 检查是否有单词能匹配输入前缀
4. 返回所有匹配输入前缀的单词
class TrieNode {constructor() {// Each TrieNode has a map of children nodes,// where the key is the character and the value is the child TrieNodethis.children = new Map();// Flag to indicate if the current TrieNode represents the end of a wordthis.isEndOfWord = false;} }class Trie {constructor() {// The root of the Trie is an empty TrieNodethis.root = new TrieNode();} insert(word) {let current = this.root;for (let i = 0; i < word.length; i++) {const char = word[i];// if the character doesn't exist as a child node,// create a new TrieNode for itif (!current.children.get(char)) {current.children.set(char, new TrieNode());}// Move to the next TrieNodeecurrent = current.children.get(char);}// Mark the end of the word by setting isEndOfWord to truecurrent.isEndOfWord = true; } search(word) {let current = this.root;for (let i = 0; i < word.length; i++) {const char = word[i];// if the character doesn't exist as a child node,// the word doesn't exist in the Trieif (!current.children.get(char)) {return false;}// move to the next TrieNodecurrent = current.children.get(char);}return current.isEndOfWord;}startsWith(prefix) {let current = this.root;for (let i = 0; i < prefix.length; i++) {const char = prefix[i];if (!current.children.get(char)) {return false;}currrent = current.children.get(char);}return true;}getAllWords(prefix = '') {const words = [];// Find the node corresponding to the given prefixconst current = this.#findNode(prefix);if (current) {// if the node exists, traverse the Trie starting from that node // to find all words and add them to the 'words' arraythis.#traverse(current, prefix, words);}return words;}delete(word) {let current = this.root;const stack = [];let index = 0;// Find the last node of the word in the Triewhile (index < word.length) {const char = word[index];if (!current.children.get(char)) {return;}stack.push({ node: current, char });current = current.children.get(char);index++;}if (!current.isEndOfWord) {// word doesn't exist in the Trie, nothing to deletereturn;}// Mark the last node as not representing the end of a wordcurrent.isEndOfWord = false;// Remove nodes in reverse order until reaching a node // that has other children or is the end of another wordwhile (stack.length > 0) {const { node, char } = stack.pop();if (current.children.size === 0 && !current.isEndOfWord) {node.children.delete(char);current = node;} else { break; }}}#findNode(prefix) {let current = this.root;for (let i = 0; i < prefix.length; i++) {const char = prefix[i];if (!current.children.get(char)) {return null;}current = current.children.get(char);}return current;}#traverse(node, prefix, words) {const stack = [];stack.push ({ node, prefix });while (stack.length > 0) {const { node, prefix } = stack.pop();// If the current node represents the end of a word,// add the word to the 'words' arrayif (node.isEndOfWord) {words.push(prefix);} // Push all child nodes to the stack to continue traversalfor (const char of node.children.keys()) {const childNode = node.children.get(char);stack.push({ node: childNode, prefix: prefix + char });}}} }
使用Trie
cnost trie = new Trie(); trie.insert("apple"); trie.insert("app"); trie.insert("monkey"); trie.insert("monk"); trie.insert("cat"); trie.insert("dog"); trie.insert("duck"); trie.insert("dune");trie.search("apple"); // true tire.search("bat"); // false trie.getAllWords("ap"); // ['apple', 'app'] trie.getAllWords("b"); // [] trie.delete("monkey"); trie.getAllWords("m") // ['monk']
性能
前序树,我们底层使用了一个哈希表来实现的。性能来自两个因素:
1. 输入的单词或者前缀的长度
2. 给定一个字母,它下面所包含的子节点的数量
我们插入,查找,删除都是线性时间复杂度O(k),k是单词长度。我们底层是hashmap,一般检查一个字母是否存在是O(1)复杂度,最坏是O(n),这个发生在一个节点它有异常多的子节点。