系列文章目录和关于我
0.引入
最近笔者使用flink实现一些实时数据清洗(从kafka清洗数据写入到clickhouse)的功能,在编写flink作业后进行上传,发现运行的时候抛出:java.io.NotSerializableException,错误消息可能类似于 “org.apache.flink.streaming.api.functions.MapFunction implementation is not serializable”的错误。该错误引起了我的好奇:
- flink为什么要把map,filter这些function interface 进行序列化?
- 方法引用或者lambda如何进行序列化?
1.什么是flink、flink为什么要把map,filter这些function interface 进行序列化?
Apache Flink 是一个开源的分布式流批一体化处理框架。它能高效地处理无界(例如:前端埋点数据,只要用户在使用那么会源源不断的产生数据)和有界(例如:2024年的所有交易数据)数据流,并且提供了准确的结果,即使在面对乱序或者延迟的数据时也能很好地应对。Flink 在大数据处理领域应用广泛,可用于实时数据分析、事件驱动型应用、数据管道等多种场景。
如下是一个典型数据管道应用
public class SimpleDataPipelineExample {public static void main(String[] args) throws Exception {// 1. 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 定义数据源,这里简单模拟一个包含字符串的集合作为数据源// 可以想象这里是从kafka中读取数据DataStream<String> inputDataStream = env.fromElements("hello", "world", "flink");// 3. 对数据进行转换操作,这里将每个字符串转换为大写形式// 这里要去map(xxx),filter(xxx) 可以序列化DataStream<String> transformedDataStream = inputDataStream.map(String::toUpperCase).filter(s->s.length(s)>0);// 4. 定义输出,// flink中addSink就是定义数据最终存储到何处transformedDataStream.addSink(new org.apache.flink.streaming.api.functions.sink.PrintSinkFunction<>());// 5. 执行任务env.execute("Simple Data Pipeline Example");}
}
可以看到flink中的编程方式有点类似于java8中的stream,但是我们编写stream流代码的时候,并不需要刻意关注流中的function interface对象是否要序列化,那么flink为什么强制要求能序列化呢?
分布式环境下的任务分发与执行需求
- Flink 是一个分布式处理框架,任务会被分发到集群中的多个节点上执行。当在
DataStream或DataSet上应用map、filter等操作时,这些操作对应的函数(如MapFunction、FilterFunction)定义了具体的数据处理逻辑。 - 为了能够将这些处理逻辑发送到不同的计算节点,需要对这些函数进行序列化。例如,假设有一个 Flink 集群包含多个节点,在一个节点上定义了一个
DataStream并应用了map操作,其map函数是对输入数据进行某种复杂的转换。这个map函数需要被序列化,以便可以传输到其他节点,从而在整个集群中正确地执行数据转换任务。
2.方法引用和lambda如何被序列化
解释完为什么flink要序列化map,filter这些function interface对象,接下来用一个简单例子来分析下方法引用和lambda如何被序列化
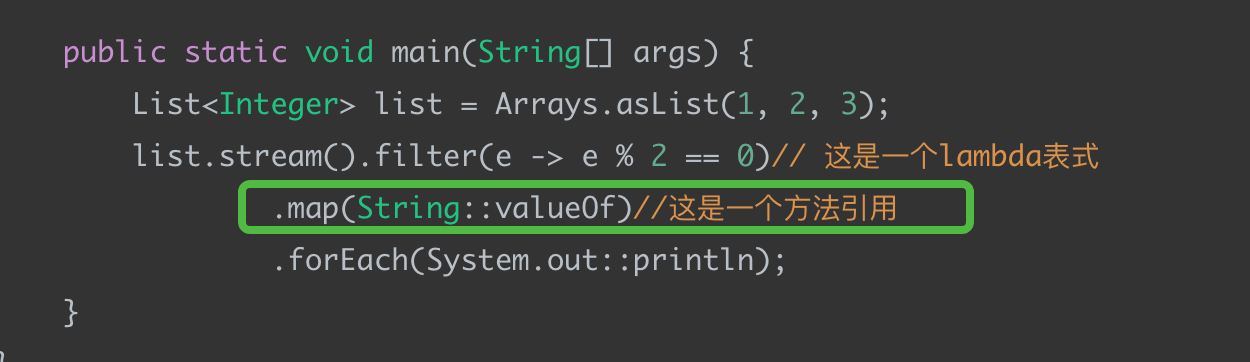
public class SimpleTest {public static void main(String[] args) {List<Integer> list = Arrays.asList(1, 2, 3);list.stream().filter(e -> e % 2 == 0)// 这是一个lambda表式.map(String::valueOf)//这是一个方法引用.forEach(System.out::println);}
}
2.1 对象如何被序列化
如下是一个Java对象使用ObjectOutputStream进行序列化,并打印序列化内容的例子
import java.io.*;
import java.util.Arrays;
import java.util.List;public class SimpleTest2 {static class Test implements Serializable {private int a;public int getA() {return a;}public void setA(int a) {this.a = a;}}public static void main(String[] args) throws Exception {Test t = new Test();t.setA(1);ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(10000);ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);objectOutputStream.writeObject(t);objectOutputStream.flush();objectOutputStream.close();System.out.println(byteArrayOutputStream.toString());}
}
可以看到会判断对象是不是实现了Serializable,没有实现会抛出异常
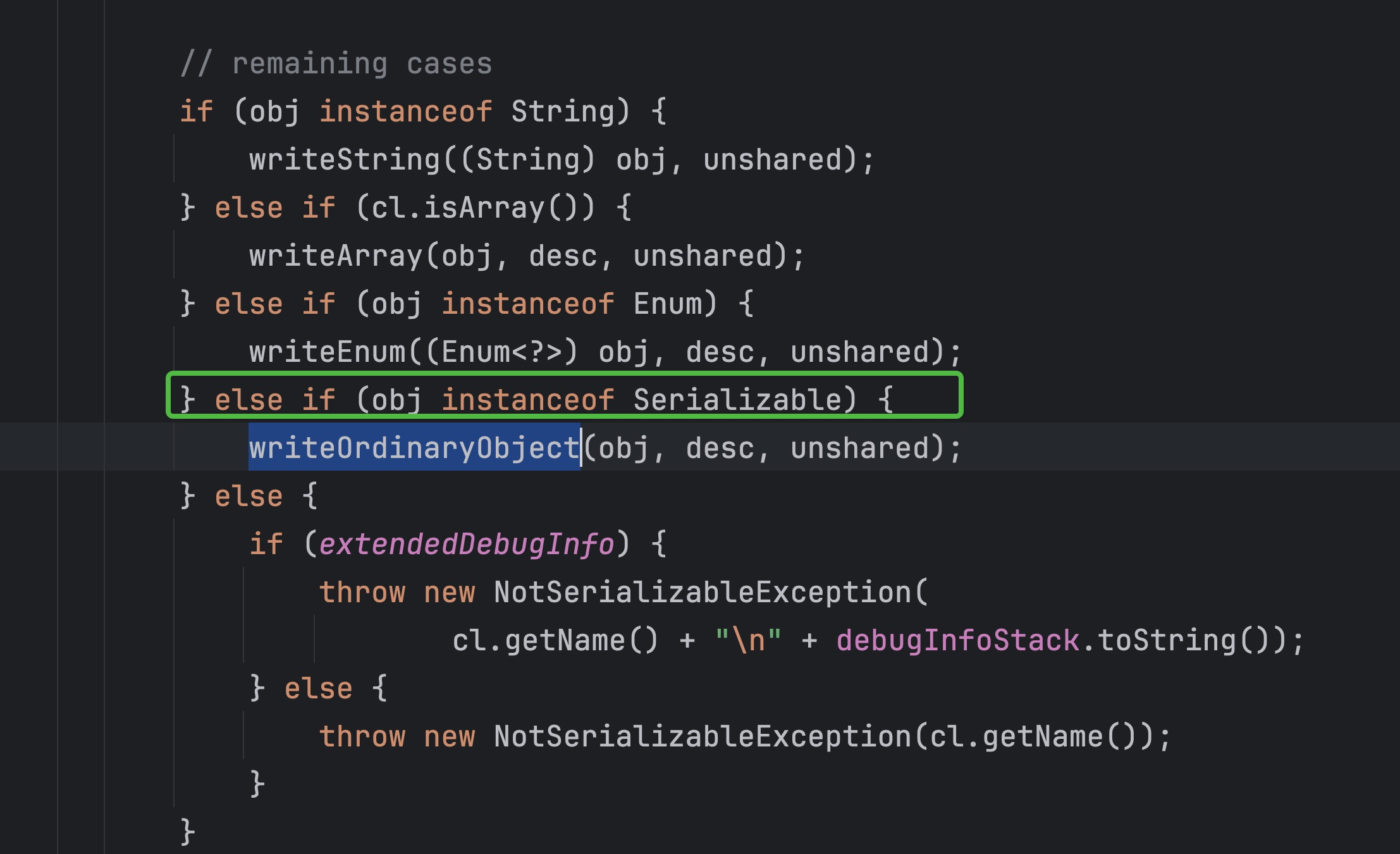
如果实现了那么先写类的描述信息(类名,是否可序列化,字段个数等等)进一步判断是否实现了Externalizable,Externalizable支持我们自定义序列化和反序列化的方法,接着会写每一个字段的值:
可以看到本质上类似于JSON序列化,有自己的对象序列化协议。
2.2 方法引用和lamda如何被序列化,方法引用和lambda是对象么
Java中一切皆对象,虽然方法引用和lambda看似和对象不同(没有被new出来)但是本质上仍然是一个对象。可以通过下面两张方式验证:
-
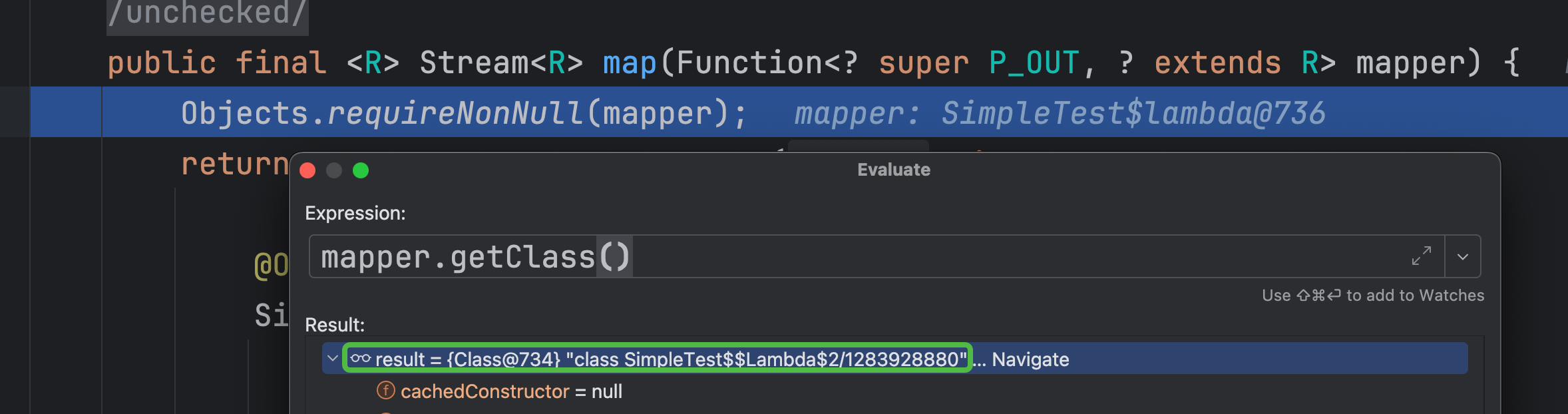
idea断点
可以看到是一个SimpleTest$$Lambda$xx类的实例对象
-
字节码层面
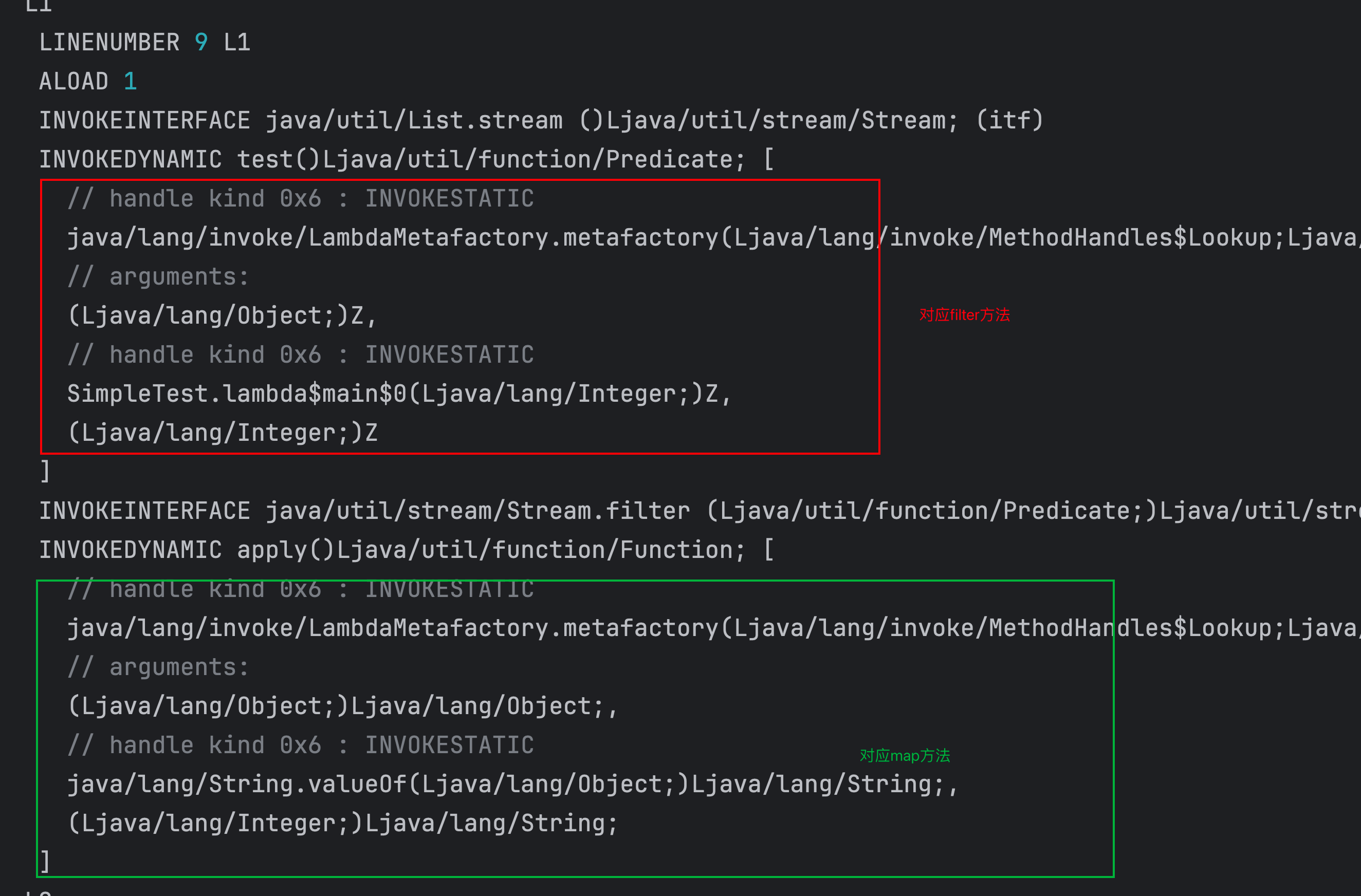
可以看到filter对应的lamda最终会调用SimpleTest.lambda$main$0(Ljava/lang/Integer;)Z,方法引用则有所不同调用并没有生成一个独特的方法?这是为什么呢?
- Lambda 表达式生成静态方法的原因
- 在 Java 编译器处理 Lambda 表达式时,对于在
main方法(或其他非实例方法)内部定义的 Lambda 表达式,它会生成一个静态私有方法来实现 Lambda 表达式的逻辑。这是因为在这个场景下,没有合适的实例来关联这个 Lambda 表达式的逻辑。以filter(e -> e % 2 == 0)为例,这个 Lambda 表达式的逻辑需要一个独立的方法来承载。 - 生成的方法被命名为
lambda$main$0,其中main表示所在的主方法,0表示这是在main方法中生成的第一个 Lambda 表达式对应的方法。这种命名方式有助于编译器在内部管理和引用这些自动生成的方法。
- 在 Java 编译器处理 Lambda 表达式时,对于在
- 方法引用与 Lambda 表达式在字节码生成上的区别
- 对于方法引用(如
String::valueOf),它不需要像 Lambda 表达式那样生成一个新的静态方法。这是因为方法引用本身就是指向一个已经存在的方法。在字节码生成过程中,字节码指令会直接利用这个已有的方法。 - 以
INVOKEDYNAMIC apply()Ljava/util/function/Function;部分为例,字节码通过java/lang/String.valueOf(Ljava/lang/Object;)Ljava/lang/String;直接指向了String类中已有的valueOf方法,这个方法会在map操作的实际执行过程中被调用,用于将流中的元素转换为字符串。它不需要像 Lambda 表达式那样额外生成一个新的方法来承载逻辑,因为方法引用所引用的方法已经有了明确的定义和实现。
- 对于方法引用(如
至此我们明白了方法引用和lambda是如何执行的——Lambda 表达式生成静态方法,方法引用则是调用INVOKESTATIC指令调用到对应的方法
那么lambda和方法引用对应生成的对象在哪里呢?
3 INVOKEDYNAMIC是如何生成对象的
INVOKEDYNAMIC apply()Ljava/util/function/Function; [// handle kind 0x6 : INVOKESTATICjava/lang/invoke/LambdaMetafactory.metafactory(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;// arguments:(Ljava/lang/Object;)Ljava/lang/Object;, // handle kind 0x6 : INVOKESTATICjava/lang/String.valueOf(Ljava/lang/Object;)Ljava/lang/String;, (Ljava/lang/Integer;)Ljava/lang/String;]
如上的字节码对应stream中的map执行
INVOKEDYNAMIC 指令的核心作用之一就是在运行时动态地生成对象(准确说是生成调用点 CallSite 以及对应的可调用对象等相关机制来实现类似生成对象的效果),用于适配相应的函数式接口,比如这里的 Function 接口。
LambdaMetafactory.metafactory 方法的逻辑
java/lang/invoke/LambdaMetafactory.metafactory 方法在这个过程中起着关键作用,下面来详细解析一下它相关参数对应的逻辑以及整体是如何实现生成符合要求对象的:
- 参数说明:
MethodHandles$Lookup参数:它提供了一种查找和访问方法的机制,决定了可以访问哪些类以及这些类中的哪些方法等权限相关内容。简单来说,它用于定位后续所涉及方法的 “查找上下文”,确保能够正确找到要使用的方法。String参数:通常是一个名称,用于标识生成的这个调用点(CallSite)相关的逻辑等,不过在实际常见使用场景下,它的作用相对不是特别直观地体现给开发者。MethodType参数(多个):- 第一个
MethodType描述了所生成的函数式接口实现的方法整体的类型签名,比如对于Function接口对应的这里就是(Ljava/lang/Object;)Ljava/lang/Object;,意味着生成的实现Function接口的对象其apply方法接收一个Object类型的对象作为输入,然后返回一个Object类型的对象作为输出(这是从通用、抽象层面描述的接口方法签名情况)。 - 第二个
MethodType对应着具体实现逻辑的方法(也就是实际指向的那个已有方法或者对应的 Lambda 表达式转化后的方法等)的类型签名,像此处指向java/lang/String.valueOf方法,其签名是(Ljava/lang/Object;)Ljava/lang/String;,表明它接收一个Object类型的输入并返回一个String类型的输出。 - 第三个
MethodType则再次强调了在具体使用场景下(结合当前流中元素类型等实际情况)的方法签名,比如这里针对map操作中流里是Integer类型元素,所以是(Ljava/lang/Integer;)Ljava/lang/String;,也就是说明这个动态生成的Function接口实现对象在应用于当前map操作时,其apply方法接收Integer类型的输入并返回String类型的输出。
- 第一个
MethodHandle参数:它用于指向具体实现逻辑的方法,在这个例子中就是指向java/lang/String.valueOf这个已有的静态方法,相当于告诉LambdaMetafactory具体通过调用哪个方法来实现Function接口的apply方法所要求的逻辑。
- 整体生成对象的过程:
LambdaMetafactory.metafactory方法基于这些参数,在运行时会根据函数式接口(这里是Function接口)的定义以及所指定的具体实现逻辑(通过String.valueOf方法),动态地构造出一个符合该接口要求的对象(也就是实现了Function接口,并且其apply方法在调用时会按照指向的String.valueOf方法来执行相应逻辑)。这个生成的对象随后就能被用于像map操作这样的场景中,作为Stream中map方法的参数,使得流里的元素可以按照这个Function接口实现对象所定义的逻辑进行转换。
类似地,对于 filter 操作对应的 Predicate 接口,也是通过同样的机制,只是具体的参数(比如方法签名、指向的实现逻辑对应的方法等)会根据对应的 Lambda 表达式或具体实现方法有所不同,来生成符合 Predicate 接口要求的对象,进而用于流元素的筛选操作。 所以说,INVOKEDYNAMIC 结合 LambdaMetafactory.metafactory 的这套机制就是在字节码层面实现了在运行时动态生成适配函数式接口对象的关键所在。
4.用 LambdaMetafactory.metafactory生成CallSite调用String#valueOf
import java.lang.invoke.CallSite;
import java.lang.invoke.LambdaMetafactory;
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.MethodType;
import java.util.function.Function;public class LambdaMetafactoryCallSiteExample {public static void main(String[] args) throws Throwable {// 1. 获取查找上下文(caller),代表调用者的查找上下文及访问权限MethodHandles.Lookup lookup = MethodHandles.lookup();// 2. 定义invokedName,即要实现的方法名称,这里对应Function接口的apply方法名String invokedName = "apply";// 3. 定义invokedType,CallSite预期的签名,返回类型是要实现的接口(这里是Function接口)// 参数类型(这里无捕获变量,所以为空),返回类型为Function接口类型MethodType invokedType = MethodType.methodType(Function.class);// 4. 定义samMethodType,函数对象要实现的方法的签名和返回类型// 对于Function接口的apply方法,接收Object类型参数,返回Object类型结果MethodType samMethodType = MethodType.methodType(Object.class, Object.class);// 5. 定义implMethod,指向具体实现逻辑的方法句柄,即String类的静态方法valueOfMethodHandle implMethodHandle = lookup.findStatic(String.class, "valueOf", MethodType.methodType(String.class, Object.class));// 6. 定义instantiatedMethodType,调用时动态强制执行的签名和返回类型,这里和samMethodType保持一致MethodType instantiatedMethodType = samMethodType;// 7. 使用LambdaMetafactory.metafactory生成CallSiteCallSite callSite = LambdaMetafactory.metafactory(lookup,invokedName,invokedType,samMethodType,implMethodHandle,instantiatedMethodType);// 8. 获取生成的函数式接口实例(这里是Function接口实例)Function<Object, String> function = (Function<Object, String>) callSite.getTarget().invoke();// 9. 使用生成的函数式接口实例进行操作String result = function.apply(42);System.out.println("Result: " + result);}
}
至此我们明白了Stream.map传入方法引用的时候,其实是使用LambdaMetafactory.metafactory生成callSite然后生成Function,这个Function保存在流的内部,当流开始执行的时候会调用Function对应的方法
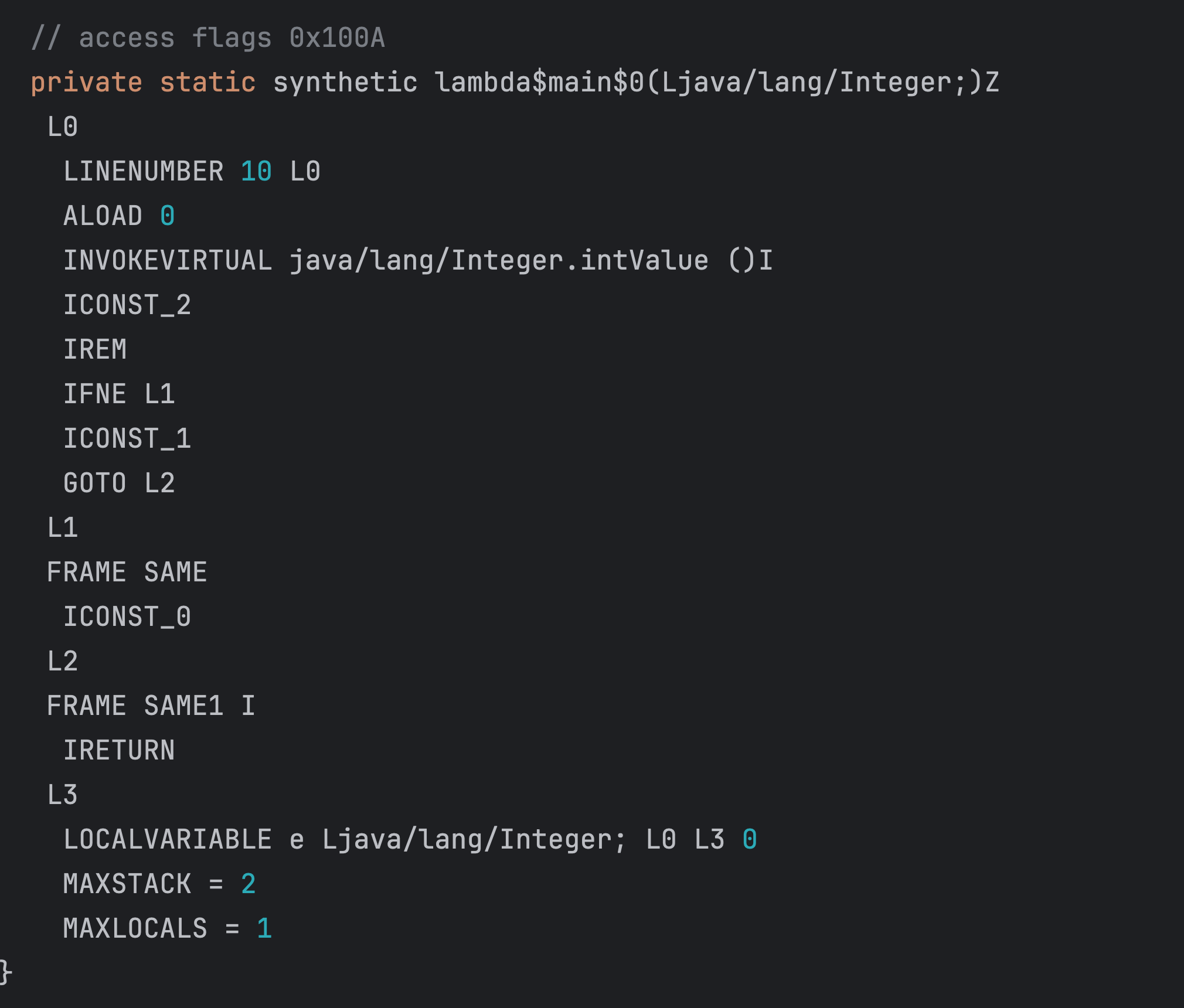
5.lambda生成的静态方法在哪里
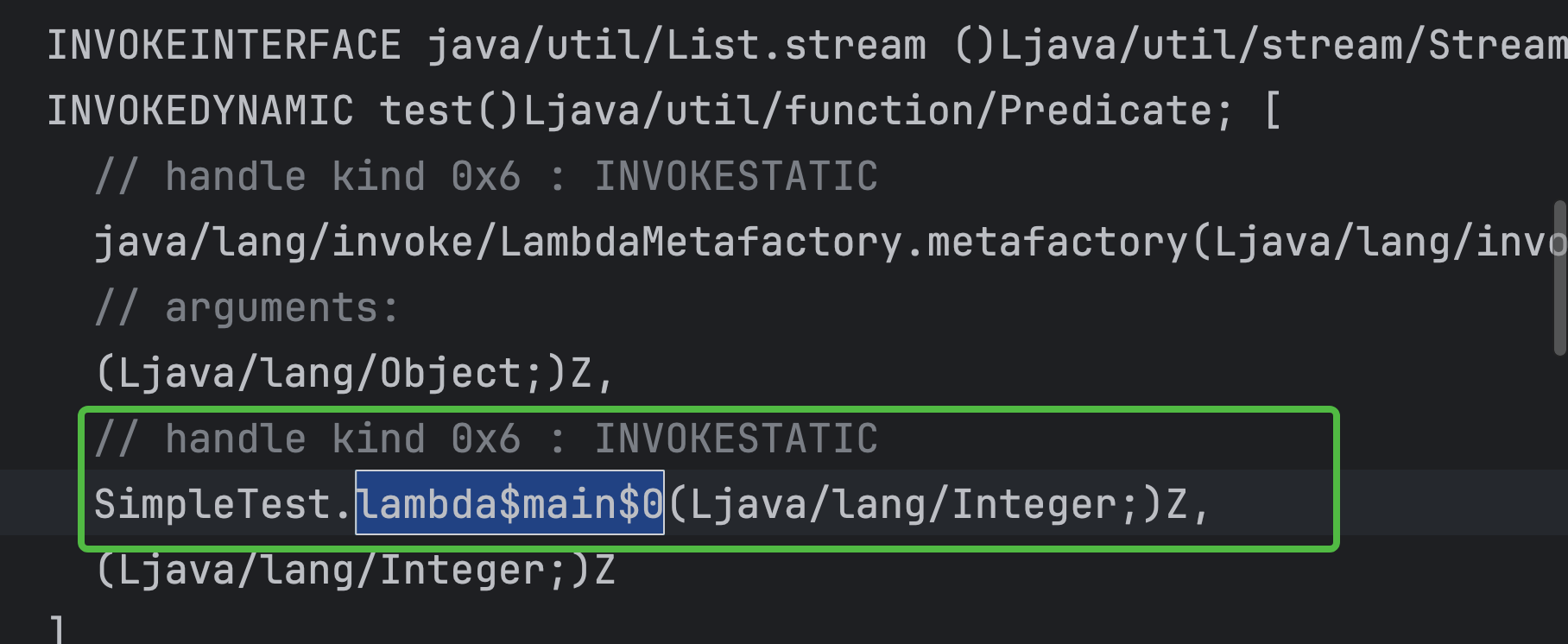
如上字节码对应filter的执行逻辑

可以看到这里其实是用了INVOKESTATIC来调用SimpleTest.lambda$main$0方法,也就说说filter的执行类似map,也是用LambdaMetafactory.metafactory生成callSite然后生成Function,但是这个Function的执行是使用INVOKESTATIC来执行生成的SimpleTest.lambda$main$0方法。
INVOKESTATIC指令的核心功能就是发起对一个类中静态方法的调用操作。它允许在字节码层面直接指定要调用的类以及对应的静态方法,并且按照方法定义传递相应的参数,执行完该静态方法后,根据方法的返回类型获取返回结果(如果有返回值的话)
import java.lang.reflect.Method;
import java.util.Arrays;
import java.util.List;public class SimpleTest {public static void main(String[] args) {List<Integer> list = Arrays.asList(1, 2, 3);list.stream().filter(e -> e % 2 == 0).map(String::valueOf).forEach(System.out::println);for (Method method : SimpleTest.class.getDeclaredMethods()) {System.out.println(method.getName());}}
}执行这段程序可以看到输出了
2//流的打印
main//SimpleTest中有main方法
lambda$main$0//还有个叫lambda$main$0的方法
该类的字节码也可以看到存在lambda$main$0(表示是main方法中第一个lambda)
在 Java 中,Lambda 表达式本质上是一种匿名函数的语法糖,编译器会将其转换为一个对应的方法,并在合适的地方生成相应的字节码来调用这个方法。对于像你展示的这种带有一定逻辑判断的 Lambda 表达式(从字节码中可以看出包含了加载参数、方法调用、算术运算以及条件跳转等操作),编译器会按照一定的规则来生成对应的字节码表示的方法,使其能实现 Lambda 表达式所定义的逻辑功能。
具体是如何生成方法对应字节码的,这就是JVM对应功能实现了,笔者还没有进一步查看JVM源码。
5.个人思考
lambda和方法引用是Java8新增的语法糖,针对Java开发者来说提供了函数式编程更加简洁的写法,虽然看起来和原来面向命令编程有很大的区别,但是底层还是Java 方法调用那一套。
新语法糖的引入并没有打破底层原有逻辑,而是通过引入新的INVOKEDYNAMIC和LambdaMetafactory.metafactory 将新语法糖嫁接到原来的方法调用实现上,这也是一种开闭原则的体现,这样实现的好处是:影响面可控,如果开发一个新功能要打破原有架构,原有代码,那么回归覆盖测试的范围将不可控。另外lambda和方法底层的使用对开发者完全透明,对开发者友好。