题目:
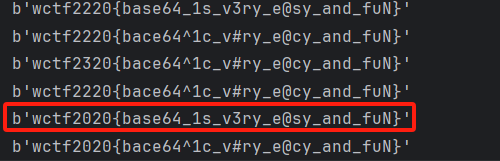
密文:MyLkTaP3FaA7KOWjTmKkVjWjVzKjdeNvTnAjoH9iZOIvTeHbvD==
JASGBWcQPRXEFLbCDIlmnHUVKTYZdMovwipatNOefghq56rs****kxyz012789+/oh holy shit, something is missing...第一行是密文,有明显的Base64编码特征(等号结尾)
第二行是大小写字母、数字、+、/,有明显的Base64编码表特征,但是多了四个星号,这个可以和标准编码表对比找到缺失部分,四个星号分别代表j、u、3、4,但顺序未知。
标准编码表:
standard_alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'接下来只需要将题目中的“密文”转化为使用正确编码表编码的“密文”,再转码为明文可得flag。脚本如下:
import base64
import itertoolsencoded_str="MyLkTaP3FaA7KOWjTmKkVjWjVzKjdeNvTnAjoH9iZOIvTeHbvD=="
standard_alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
chars=['j','u','3','4']
for comb in itertools.product(chars,repeat=4):wrong_alphabet_guess='JASGBWcQPRXEFLbCDIlmnHUVKTYZdMovwipatNOefghq56rs'+''.join(comb)+'kxyz012789+/'mapping = {wrong_alphabet_guess[i]: standard_alphabet[i] for i in range(len(wrong_alphabet_guess))}corrected_str = ''.join(mapping.get(c, c) for c in encoded_str)decoded_bytes = base64.b64decode(corrected_str)print(decoded_bytes)找到最像的一个