大家好,我是土哥。
之前有位同学,在土哥的辅导下,居然飘了,当腾讯酷我音乐 HR 看完他的简历后,想邀约他面试,他直接一口回绝了。
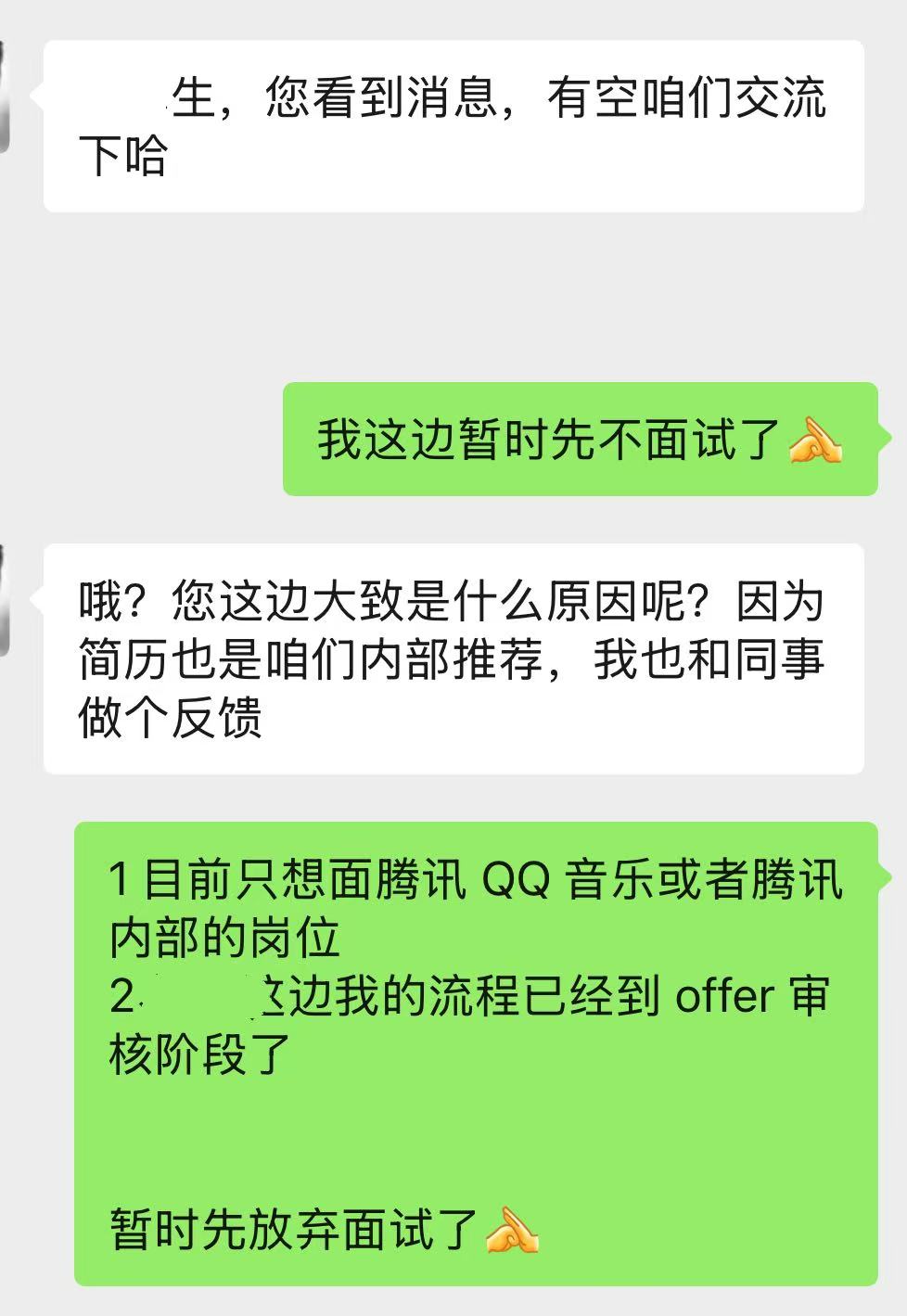
给的理由如下:
-
目前只想面腾讯 QQ 音乐或者腾讯内部的岗位
-
大厂流程已经到 offer 审核阶段了
基于上述两个条件,所以暂时放弃面试。
当土哥看到他的回复后,问到为啥只想面腾讯内部岗和腾讯QQ音乐之类的。
他回复:腾讯音乐目前包含酷狗音乐、QQ音乐、酷我音乐,毫无疑问,QQ 音乐占据主导地位,同时酷狗音乐盈利也不错,只有酷我音乐发展曲折,同时入职签合同时,还不是签约腾讯主体,所以不想面~
我看完后,只能说一个字,绝 还调侃他,你可真是涝的涝死~ 当然,这位小伙伴最后也成功入职字节~
在这里也想给正在找工作的小伙伴一个建议,当没有正式拿到 offer 之前,如果有机会面试,并且还不错,那还是先面着,毕竟 offer 审核阶段也非常容易被鸽的。
腾讯面试
这里给大家分享一个其他同学面试腾讯 QQ 音乐岗位的大数据面试题。具体的简单题,这里就暂不分享了,主要分享三道他第三轮面试过程中,部门负责人问到的问题
1 流任务运行在 K8S 上面,你们怎么做稳定性保障的?
要回答上述这个问题,可以从以下几个方面回答。这个问题,无论是数仓、平台、引擎同学,面试都会经常被问到,因为大领导一般更关注高可用性、稳定性、容灾、成本、以及收益。
下面给一些回答的案例~
1 机器下线、队列下线
在平台上,经常会遇到机器下线,队列下线的问题,这个时候,需要通知用户对任务进行任务重启,这样会遇到很多问题:
-
机器下线是常态化的事情,会频繁干扰用户。
-
当涉及的用户作业数较多,手动操作非常繁琐。
-
沟通成本较大,会浪费大量的时间。
所以针对机器下线、队列下线等问题。
K8S 任务在启动时,会让用户选择开启自动迁移的开关,开关打开后,会将该任务调度到不需要迁移的机器上。通过标签来控制。
node-selector=music.da/op:0。
这样,在进行机器下线和队列下线时,Flink 平台会自动帮助用户进行操作。
-
将下线机器标记为不可调度,同时会自动拉取该机器上运行的 tm 和 jm pod ,然后根据 pod 名 找到对应的 flink 作业。
-
基于用户之前开启的自动迁移开关配置进行自动化迁移,迁移前会基于部门、作业负责人自动根据筛选的任务拉群。
-
所有作业都迁移完成后,机器就会正式下线。
2 硬件故障
硬件故障,主要有以下三点。
-
磁盘故障,比如磁盘坏道、内核故障等引起的读写卡顿问题。
-
内存故障,比如部分数据脏写、gc 频繁等。
-
网络故障,比如网卡异常导致无法连接等问题。
这些问题的共性是,导致作业卡顿或者表现异常,但又不是彻底的失败,定位非常困难,甚至无法查出问题所在。当规模比较大时,这种问题会频繁出现。
所以我们的解决方案是:
- 当某台节点非常容易出现负载、IO、网卡等问题了,会直接将这台节拉黑,驱逐上面的pod。
- 我们集群的任务,划分等级,通过 P0, P1, P2, P3 四个等级来划分任务。不同等级的任务有不同的保障策略。
P0 为双 AZ 容灾(热备)、P1 为双 AZ 容灾(冷备)、P2 表示单集群常规作业、P3 表示不重要的作业资源,一般采用混部资源,随时可能被抢占,同时稳定性一般。
双 AZ 容灾:双 AZ(可用区)容灾是指在分布式系统中采取的一种高可用性策略。
AZ 是指不同的可用区域,通常是指在不同的地理位置或数据中心内部署系统的部分。
双 AZ 容灾意味着系统在两个不同的可用区域内有备份或镜像,以确保即使一个可用区域发生故障,系统仍然可以继续运行。
热备:在双 AZ 容灾中,热备通常指的是备用系统处于实时准备就绪状态,可以立即接管主系统的工作负载,以确保系统在主系统发生故障时可以快速切换到备用系统,实现高可用性和容灾能力。
2 你们如何做的冷热容灾?
下面重点介绍一下 冷备方案 和 抢占方案。
Flink 的冷备方案既支持 Flink 冷备,也支持 Kafka AZ 容灾,主要指消费两个同名的 Topic 和写出两个同名的 Topic。同名 Topic 在不同的 AZ 下,两个同名的 Topic 共同组成一份完整的数据。
这时如果上游的一个 Kafka 集群挂掉,Flink 会自动容灾,并推动 watermark 的前进,整个作业不受影响。Flink 在常规情况下,通过轮转写的方式,将数据写到下游的两个 Topic。如果一个 Topic 挂掉,数据会全部导到另一个 Topic。
针对 Flink 作业,我们会定期将快照写到备集群。一旦作业管理平台监测到 Flink 所在的 AZ 挂掉,会自动在备集群拉起一个一样的 Flink 作业。
常见的保障措施,主要包括以下四点:
-
资源隔离。高优作业可以单独划定队列,实现物理隔离,同时不与离线作业混部。
-
资源抢占。在资源紧张情况下,高优作业可自动抢占低优作业的资源。
-
AZ 容灾。高优作业可实现 AZ 容灾,包括冷备和热备。
-
智能监控报警。高优作业配套的报警更加完善,一旦出现预期之外的问题可快速人工介入。
3 半夜任务运行失败,如何保障业务稳定?
1 自动巡检
我们开发了自动巡检功能,每分钟都在巡检机器中任务运行的真实状态,若遇到运行失败或一直存于调度中的任务,会尝试将其拉起。
5分钟内,每隔 10 秒拉起一次,若重试 10 次都不行,就会通知用户发送告警通知,同时单任务也有告警通知,任务失败或者延迟等,都会发相应的告警。
同时 Flink 日志目前统一被写入 ck 中,并增加了智能诊断、指定异常定位等功能。帮助用户开始定位问题。
2 P0 级任务双跑 + 双监控 + 智能拉起
-
巡检时,就运行失败的人物进行智能拉起,若拉起不成功,根据任务等级选择不同方式: P0 会立刻切换到热备链路。
-
双监控。双监控是指业务一套监控、平台一套监控,(这套流程目前只适用 P0 级任务),同时立刻通知平台操作紧急值班人员进行处理,15 分钟后,再告警通知业务人员。(在这15分钟期间,平台紧急人员已经将任务处理完成,这样业务人员就不会收到告警和电话)。
这种设计,真的对平台的紧急值班人员是一种非人类折磨,哈哈哈哈~
以上就是关于腾讯 QQ 音乐面试中,土哥根据小伙伴被问的问题,给的解决方案哈~
增值服务
增值服务:简历修改|面试辅导|Flink资料|模拟面试
你好,我是土哥,计算机硕士毕业,现某大厂资深大数据开发工程师。出生在一个 18 线开外的小村庄,通过自己努力毕业一年在新一线城市买房,在社招、校招斩获 28 家中大厂 offer。
土哥社招参加 28 场面试,100% 通过率,拿到全部 offer!
土哥这半年的悲惨人生,经历过被鸽 offer,最终触底反弹~
25 年新的一年,很多公司已经开启了节前面试-年后入职的流程。如果你想跳槽,但苦于一个人孤军奋战、无人指导、复习无从下手,或者不擅长写简历,手上只有拿不出手的毫无难点亮点的项目经历...
那么我的建议是多和身边的大佬沟通,哪怕是付费咨询,只要你能从他身上学到经验,那就是值得的。如果身边没有这样的人,那么我就毛遂自荐一下吧,毕竟,茫茫网络你能看到这篇文章何尝不是一种命运安排。
如果这篇文章对您有所帮助,或者有所启发的话求一键三连:点赞、转发、在看。





![P3586 [POI2015] Logistyka](https://cdn.luogu.com.cn/upload/image_hosting/5o4u7lct.png)