数据处理

超参:人为指定不能改变
测试数据只有x没有标签y
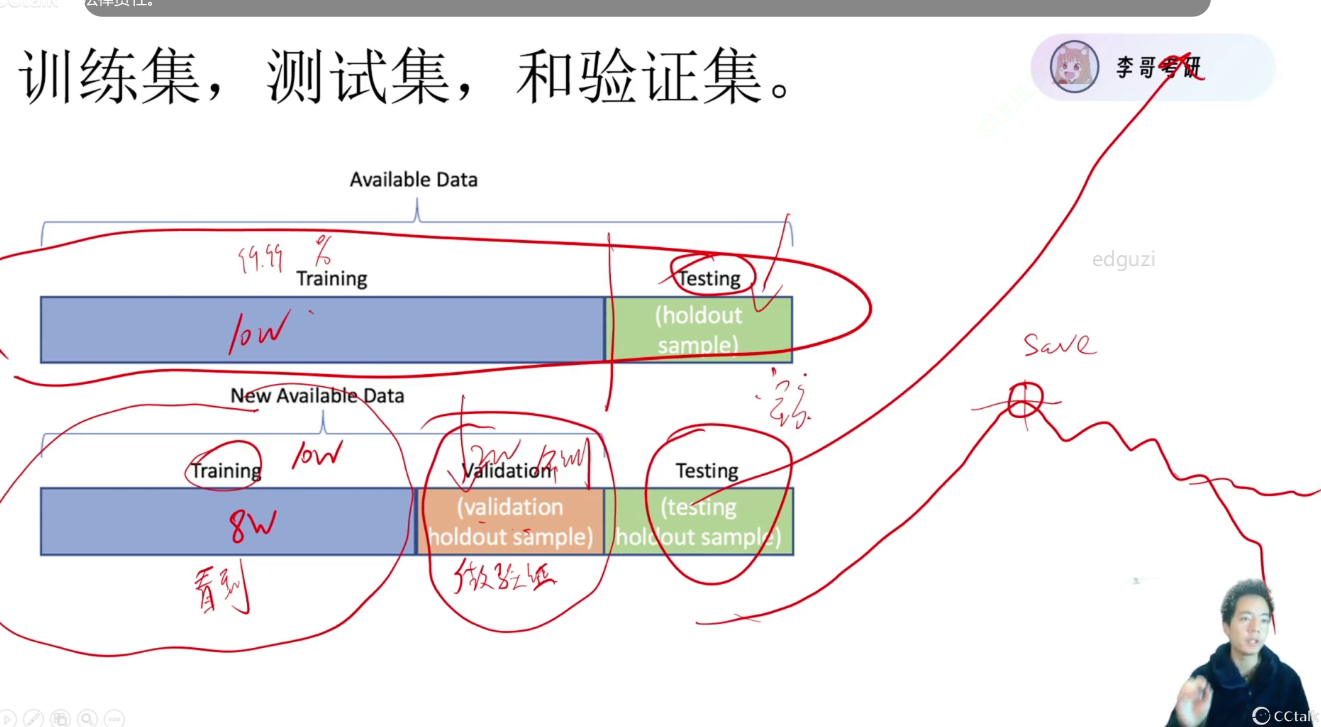
训练数据拆分,82开,作训练集和验证集(验证模型好坏),模型训练不是一路上升的过程,训练几次验证一次,最好的模型save下来
one-hot独热编码 猪(1 0 0) 狗(0 1 0) 猫(0 0 1)
def get_feature_importance(feature_data, label_data, k = 4, column = None):"""feature_data, label_data 要求字符串形式k为选择的特征数量如果需要打印column,需要传入行名此处省略 feature_data, label_data 的生成代码。如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。"""model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数feature_data = np.array(feature_data, dtype=np.float64)X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征print('x_new', X_new)scores = model.scores_ # scores即每一列与结果的相关性# 按重要性排序,选出最重要的 k 个indices = np.argsort(scores)[::-1] #[::-1]表示反转一个列表或者矩阵。# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。if column: # 如果需要打印选中的列名字k_best_features = [column[i] for i in indices[0:k].tolist()] # 选中这些列 打印print('k best features are: ',k_best_features)return X_new, indices[0:k] # 返回选中列的特征和他们的下标。
class Covid_dataset(Dataset):def __init__(self, file_path, mode, dim=4, all_feature=False):with open(file_path, "r") as f:csv_data = list(csv.reader(f))#list会变为数据data = np.array(csv_data[1:])#去掉第一行if mode == "train": #逢五取一indices = [i for i in range(len(data)) if i % 5 !=0]elif mode == "val":indices = [i for i in range(len(data)) if i % 5 ==0]if all_feature:col_idx = [i for i in range(0,93)]else:_, col_idx = get_feature_importance(data[:,1:-1], data[:,-1], k=dim,column =csv_data[0][1:-1])if mode == "test":x = data[:, 1:].astype(float)#将数据由字符型转为浮点型x = torch.tensor(x[:, col_idx])else:x = data[indices, 1:-1].astype(float) #x 选indices的行 x要去掉最后一列x = torch.tensor(x[:, col_idx])y = data[indices, -1].astype(float)self.y = torch.tensor(y)self.x = (x-x.mean(dim=0, keepdim=True))/x.std(dim=0, keepdim=True)#数据的量纲不同,要归一化.每列的数值差距大 mean()平均值要在一列中取第0维同时保持维度不变self.mode = mode #把mode传到self中def __getitem__(self, item):if self.mode == "test":return self.x[item].float()#测试集没有y float是把变量变为32位,消耗不会太大,else:return self.x[item].float(), self.y[item].float() def __len__(self):return len(self.x)
Dataset类 xy
- init 初始化 filepath x[] Y[]
- getitem 取数据 idx->X[idx] Y[idx]
- len 数据长度

模型部分
class myModel(nn.Module):#模型首先关注维度变化 回归中用全连接linear 上一层输出一定是下一层输入 输入维度(16,93)16为样本数量,93为样本维度def __init__(self, dim):#初始化 模型长什么样 dim为输入维度super(myModel, self).__init__()#修改这里的初始化self.fc1 = nn.Linear(dim, 100)#全连接(输入维度,输出维度)self.relu = nn.ReLU() #激活函数 不需要参数self.fc2 = nn.Linear(100, 1) #输入100维 输出1维def forward(self, x):#模型前向过程x = self.fc1(x) x = self.relu(x)x = self.fc2(x)if len(x.size())>1: #x有两维要减去一维 去掉第二维,去掉第二个x = x.squeeze(dim=1)return x
超参部分

config = {"lr" : 0.001,"momentum": 0.9,#动量,惯性,继续冲一下"epochs":20,"save_path": "model_save/model.pth", #保存路径"rel_path" : "pred.csv" #
}
loss = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=config["lr"], momentum=config["momentum"])train_val(model, train_loader, val_loader, device, config["epochs"], optimizer, loss, config["save_path"])evaluate(config["save_path"], device, test_loader, config["rel_path"])
训练流程
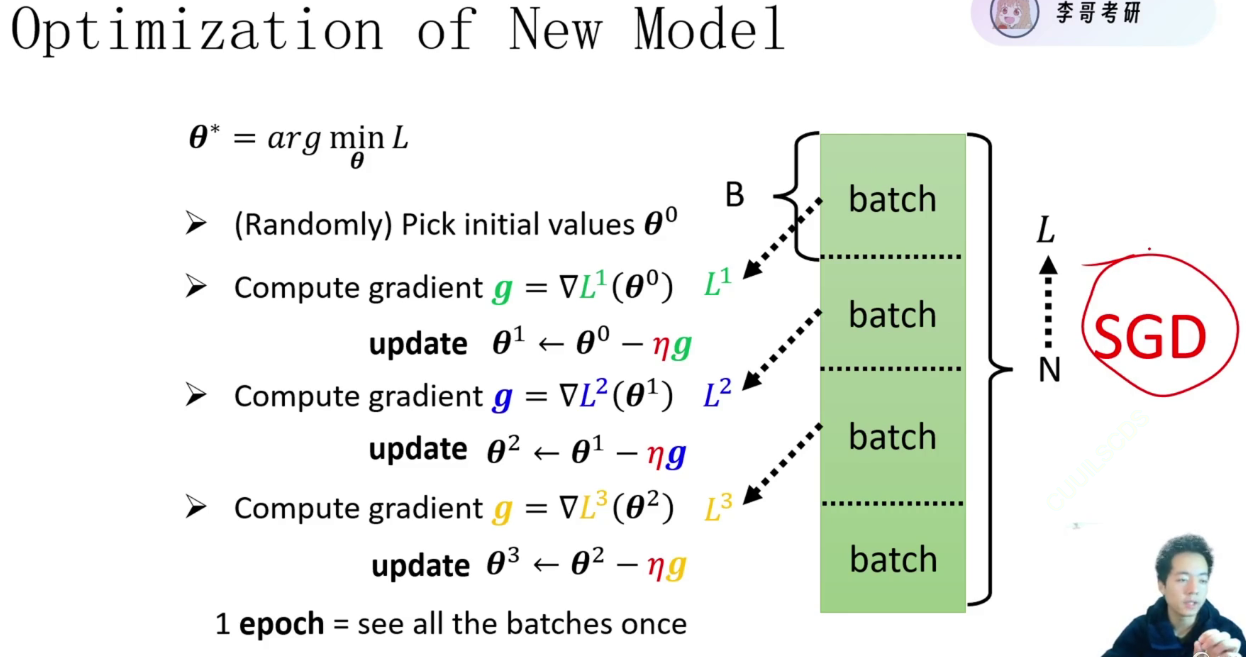
def train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path):model = model.to(device)plt_train_loss = [] #每轮训练记录loss值,记录所有轮次loss值plt_val_loss = []min_val_loss = 9999999999 #记录最好的模型,最小的loss值for epoch in range(epochs): #冲锋的号角train_loss = 0.0val_loss = 0.0start_time = time.time()model.train() #模型调整为训练模式for batch_x, batch_y in train_loader:x, target = batch_x.to(device), batch_y.to(device)pred = model(x) #得到预测值# train_bat_loss = loss(pred, target,model)train_bat_loss = loss(pred, target) #得到losstrain_bat_loss.backward() #回传optimizer.step() #更新模型optimizer.zero_grad() #模型梯度清0train_loss += train_bat_loss.cpu().item()#在gpu上是张量没法和浮点数相加 item为把数值取出来plt_train_loss.append(train_loss/train_loader.dataset.__len__())#加在所有的loss值里,记录的是平均值model.eval() #调整为验证模式with torch.no_grad(): #所有在张量网上的计算都会计算梯度,验证集不会更新模型for batch_x, batch_y in val_loader:x, target = batch_x.to(device), batch_y.to(device)pred = model(x)# val_bat_loss = loss(pred, target,model)val_bat_loss = loss(pred, target)val_loss += val_bat_loss.cpu().item()plt_val_loss.append(val_loss / val_loader.dataset.__len__())if val_loss < min_val_loss: #模型效果最好,保存模型torch.save(model, save_path)min_val_loss = val_lossprint("[%03d/%03d] %2.2f secs Trainloss: %.6f Valloss: %.6f"%(epoch, epochs, time.time()-start_time,plt_train_loss[-1],plt_val_loss[-1]))plt.plot(plt_train_loss)#画图函数plt.plot(plt_val_loss)plt.title("loss")plt.legend(["train","val"])#图例plt.show()