本文由 RTE 开发者社区成员通过社区网站投稿提供,如果你也有与实时互动(Real-Time Engagement,RTE)相关的项目分享,欢迎访问网站 rtecommunity.dev 发布,优秀项目将会在公众号发布分享。
目录
什么是 AI 记忆?
AI 记忆的类型
短记忆 vs. 长记忆User Memory vs. Agent Memory:两种记忆,两种侧重记忆 vs. RAG:到底有什么区别?
为什么 AI 应用需要记忆?
现在的长记忆方案有哪些?
记忆设计机制对比现有记忆方案的常见问题
Memobase:为 AI 原生应用打造的长记忆解决方案
为什么选择 Memobase?Memobase 的核心功能
Memobase 的应用场景
大模型厂商的记忆服务 vs. 第三方提供商如 Memobase,该如何抉择?
🚀 即刻启程,为你的 AI 产品注入长记忆
你是否也曾对 AI 聊天产品的“健忘症” 感到抓狂?聊了几句之后,它就忘了你是谁或者聊过什么?又或者,你正在开发一款 AI 应用,希望能加入 长期记忆功能 ,却不知从何下手?
其实,现在的很多 AI 产品团队都面临着同样的问题。如今大多数 AI 应用大多缺乏长期记忆,导致用户体验冷冰冰的、缺乏人情味。
Memobase 正是为了解决这个问题而生的:作为一个开源的记忆解决方案,我们希望可以彻底改变 AI应用记忆和理解用户的方式,让你的 AI 产品可以提供更贴心、更温暖、更懂你用户的互动体验。
在这篇文章中,我们将探讨:
-
什么是AI长记忆?
-
它为何重要?
-
Memory 和 RAG 的区别
-
User memory 和 Agent memory 的区别
-
现有解决方案的特点及其不足之处。 现有的解决方案有哪些,他们各自的优劣势,以及如何判断它是否适合你的 AI 应用
什么是 AI 记忆?
简单来说,AI 记忆可以看作是 AI 当前有限上下文的一种拓展。在产品的整个生命周期中,用户或者 agent 可能会产生海量的数据,甚至达到数百万到数千万条,然而 AI 大模型能够处理的上下文是有限的,通常在8K 到 128K tokens。这就意味着,仅靠 AI 自身的上下文处理能力,是无法完全应对如此庞大的数据量的。
因此,为了实现产品的完整功能,就需要引入一些额外的机制。例如,现在比较常见的对话 session 机制,就是通过重新开启对话窗口来清空之前的对话内容。但这种方式在一定程度上会导致信息的丢失。
AI 记忆的核心目标是在尽量减少信息损失的前提下,让产品能够容纳的上下文近乎无限。它就像是为 AI 打开了一扇通往更广阔数据世界的大门,使得 AI 能够更好地处理和利用海量数据,从而提升产品的性能和用户体验。
AI 记忆的类型
短记忆 vs. 长记忆
短记忆:就像电脑的内存,负责存储当前对话中的信息,帮助 AI 理解用户的实时意图。例如,用户问“第二个选项怎么样?”,AI 需要记住之前讨论过的选项才能给出合适的回答。
短记忆的特点:
-
维持当前对话的上下文,通常只针对一个会话。
-
依赖对话历史或会话状态实现。
-
受限于 token 长度(通常 4k 到 32k tokens)或会话时长。
-
会话结束后,自动清空。
长记忆: 就像电脑的硬盘,负责存储用户的身份、偏好、历史互动等信息,让 AI 产品能够像个知己一样,在每一次互动中都能更贴心更有温度。例如,AI 可以记住用户喜欢简单的解释,在某些事情上遇到过困难等等。
长记忆的特点:
-
跨会话保存:不局限于当前对话。
-
需要结构化存储和高效的检索机制。
-
用于存储模式、偏好和历史互动信息。
-
需要定期更新和维护。
User Memory vs. Agent Memory:两种记忆,两种侧重
AI 的记忆系统可以针对两个对象设计:User Memory 和 Agent(智能体)Memory 。它们的功能各不相同,但目标都是提升用户体验。
User Memory:理解用户,建立“个人档案”
用户记忆的重点是围绕每位用户建立详细档案,从而记住他们的偏好、个性化需求和关键事件。
组成部分 :
-
用户画像: 包括基本信息(年龄、兴趣)、偏好、关系网络等。
-
应用场景数据: 比如心理咨询应用中用户的性格特质,或者教育应用中用户的学习风格(比如“视觉型”)。
-
关键事件: 比如某用户的健身计划开始日期,或某段感情关系的变化。
示例代码:
const userMemory = { profile: { learningStyle: 'visual', technicalExpertise: 'beginner', preferredExamples: 'real-world' }, events: [{date: '2025…', emotion: 'happy', learn: 'Memobase, a user-profile memory backend…'},{date: '2025…', emotion:...} ]};
适用场景: 需要高度个性化体验的应用,尤其是2C的应用,比如教育,笔记,陪聊,虚拟伴侣,游戏等泛娱乐类的应用。
Agent Memory: 则侧重于AI Agent 自身的学习与能力发展。它相当于为AI构建自己的记忆库,包括比如:
-
工作流程记忆:回忆多步骤流程、API调用以及与环境的互动,使其能够更高效地完成任务。这与开发者随时间积累编程技能颇为相似。
-
技能积累:学习特定技能,如编程、数据分析或图像识别,以应对日益复杂的任务。
-
错误日志:记住过去的错误,避免重复,并持续提升性能。
示例代码如下:
const agentMemory = { personality: { communicationStyle: 'friendly_professional', expertiseAreas: ['technical_support', 'onboarding'], responseFormat: 'step_by_step' }, skills: { Github_PR_Merge: 'When I merge a PR, I should use rebase rather than merge…', Buy_Flight_Tickets: 'I should first search for the starting location and landing location on Google, then select booking.com because I have the permission to …'… }};
Agent memory 更倾向于优化工作流程,适合生产力、服务与自动化类应用,例如客服机器人,生产力工具和智能助手。
记忆 vs. RAG:到底有什么区别?
严格来说,记忆是 RAG(Retrieval-Augmented Generation)的一个子集。两者都需要从外部提取信息并融入到AI的生成提示中,但它们的应用场景和目标差异明显。
核心区别:
1.规模和范围
-
RAG: 用于在大型文档集合中检索信息(如公司 Wiki、技术文档等)。
-
记忆: 专注于从用户互动中管理个性化信息,尤其是多用户环境。
2.信息密度
-
RAG: 处理密集型的非结构化数据,比如文本或表格,通常用于事实检索。
-
记忆: 处理多会话的用户/Agent 数据,更注重交互体验。
3.检索方式
-
RAG: 借助语义搜索和嵌入式检索,匹配精确文档。
-
记忆: 倾向于总结和压缩互动中的关键点,优化上下文体验。
如何选择?
-
RAG 更适合: 搜索大规模知识库(如内部文档或技术资料),需要高度准确性和扩展性。
-
记忆更适合: 管理用户个性化信息,提升多会话的连续体验。
总之,RAG 和记忆并不是非此即彼的互斥关系,而是互补的工具。RAG 解决的是广泛的知识检索问题,而记忆的目标是让 AI 具备贴心的个性化互动能力。如果你想打造一款能记住用户需求、提供真正个性化服务的 AI 应用,记忆无疑是不可或缺的一环。
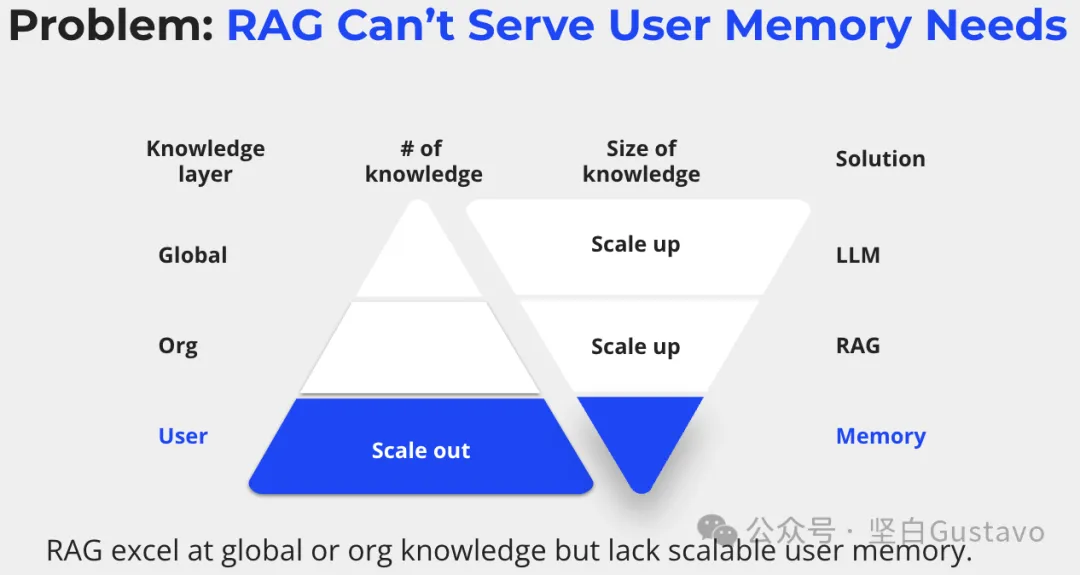
一个简化的知识分层框架
为了更好地理解记忆和 RAG 的区别,我们可以将知识分为三个层次:
-
通用知识: 通常已经内嵌入基座模型之中。
-
组织知识: 内部文档和数据集,通常使用基于向量数据库的RAG 。
-
用户特定知识: 以用户为中心的信息,需要作为用户和 AI 产品交互的上下文,这就是记忆不可或缺的地方。
啥时候用 RAG?
如果你的应用需要在大型知识库中进行精确搜索,例如公司内部维基、技术文档或大量数据集,那么 RAG 会是你的首选。
啥时候用记忆?
如果你关注的是长期交互,尤其是信息密度较低的对话数据(例如,总结一系列聊天),那么记忆是更好的选择。
为什么 AI 应用需要记忆?
我们已经了解到,AI 能够利用各种类型的知识,从海量的全球数据到公司特定的信息,但 用户级记忆 的真正价值在于,它可以让 AI 更加智能和贴心。为什么记忆对 AI 应用这么重要?让我们一起来看看:
1. 个性化互动
想象一下,一个 AI 助手不仅能记住你的兴趣爱好,还能记得你喜欢的笑话风格。每次跟你聊天时,它都能聊到点上,让你感觉它更像一个真正的朋友,而不是冰冷的机器。这种个性化的体验,不仅更有趣,也让用户更愿意长期使用。
2. 上下文连贯性
如果你告诉 AI 聊天产品:“我今天想吃汉堡和薯条。”普通的 AI 可能会直接给你推荐附近的餐馆。但一个有记忆的 AI 可能会提醒你:“可你不是说要锻炼三个月练出六块腹肌吗?”这样的互动不仅更聪明,也让用户觉得 AI 更懂自己。
3. 节约成本
我们参与的一个聊天机器人项目,在引入 Memobase 后,通过从 32K 切换到 8K 上下文窗口模型,把大语言模型(LLM)的成本降低了多达 70-75% 。因为 Memobase 可以有效地管理用户特定知识,而无需在输入提示中不断重复冗长的对话历史记录。这种优化不仅节约了资源,还让应用运行得更快。
总结一下,记忆不仅仅是一个锦上添花的功能,它是让 AI 从普通的工具变成真正有温度的助手的关键。而像 Memobase 这样的专业解决方案,可以帮助你有效管理大规模用户的长记忆。
现在的长记忆方案有哪些?
随着 AI 技术的发展,很多长记忆方案被设计出来以提升用户体验。接下来,我们一起看看这些方案的优缺点,以及它们各自适用的场景。
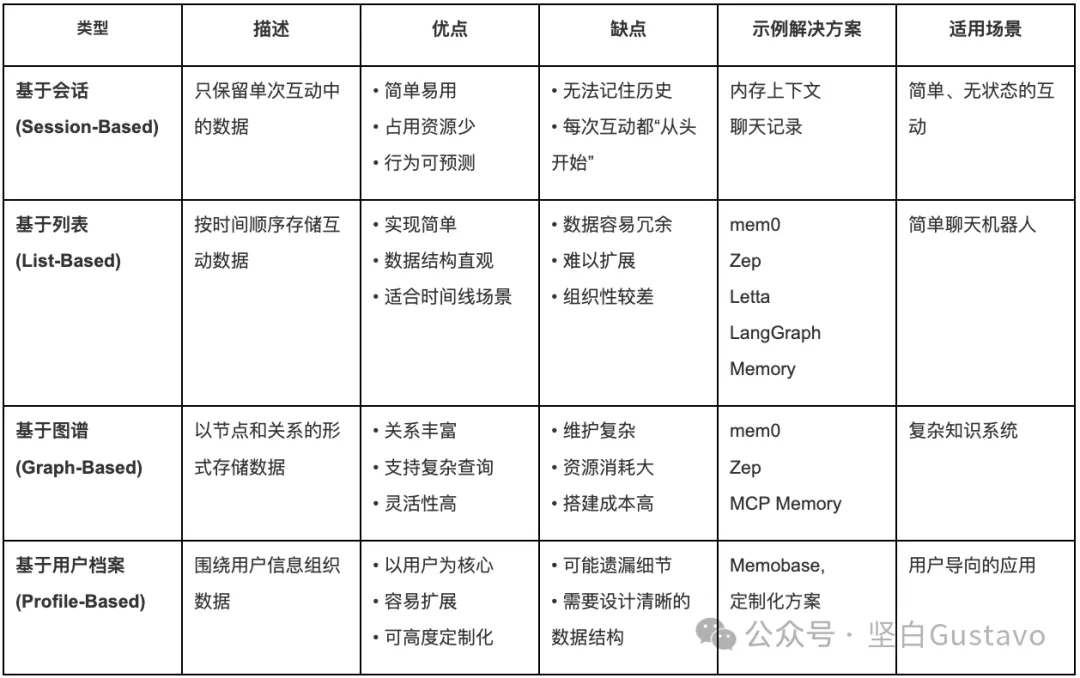
记忆设计机制对比
这里我们以一个表格的形式,对比现在最主流的记忆设计机制:
下面是一个具体的例子,帮助大家理解这几种记忆机制的区别:
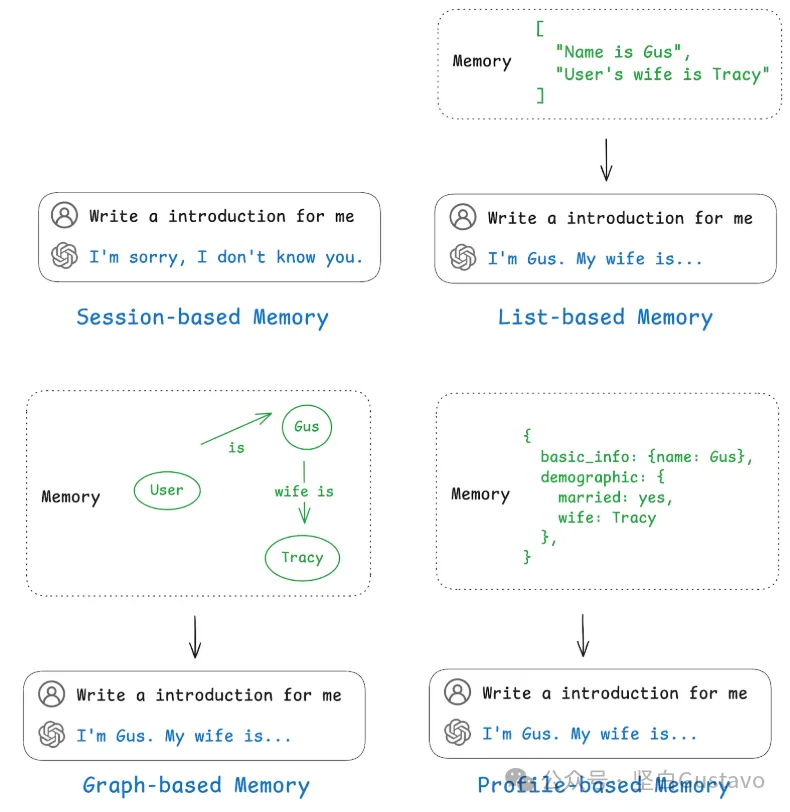
现有记忆方案的常见问题
尽管市面上有很多记忆解决方案,但它们往往存在一些局限性。LangGraph 团队总结得很好:
“目前的大多数‘智能体记忆’产品都太通用化了。试图满足所有需求,结果却没有一个能真正解决用户的痛点。”
如果你计划为自己的应用增加记忆功能,以下几个问题值得认真思考:
1. 记忆系统会记住哪些内容?
你清楚系统会记录什么吗?很多现有方案并不允许开发者决定记什么、不记什么。但不同的 AI 应用对记忆的需求完全不同,比如:
-
一个老师的 AI 助手需要记住学生的学习习惯;
-
一个虚拟秘书需要记住会议日程;
-
一个陪伴型 AI 则更关注你的兴趣和情感状态。
然而,现在许多解决方案完全依赖 AI 来决定记录什么。这种做法要么会导致 过度记忆(无用信息太多,成本飙升),要么会 遗漏重点 (关键信息没被记住)。
2. 增加记忆功能会影响性能吗?
有些记忆系统要求在用户互动过程中实时更新记忆(比如通过函数调用或工具操作)。这种方式可能导致:
-
性能下降: AI 同时处理记忆更新和用户交互,效率低下;
-
提示复杂: 为了管理记忆,提示词会变得复杂难懂,难以优化和调试。
更高效的解决方法是将记忆功能解耦——也就是让记忆成为一个独立的存储层,专门负责记忆的读写操作,而不干扰 AI 产品的主要交互职责。
3. 记忆功能会不会增加太多成本?
记忆不是免费的,更新和管理记忆需要消耗额外的计算资源。常见的两种更新机制:
-
实时更新(Hot-Path Update): 每次用户互动后立即更新记忆。这种方式可以保证记忆是实时的,但会:
-
增加延迟: 等待记忆更新会拖慢响应速度;
-
提高成本: 更新频繁,计算资源需求更大。
-
批量更新(Batch Update): 会话结束后统一处理记忆更新。这种方式更经济:
-
减少延迟: 用户体验更流畅;
-
节约成本: 批量处理更高效。
其实,大多数场景下并不需要实时更新记忆,因为 AI 本身可以暂时记住当前对话的上下文。只要确保下次用户互动前,记忆能被正确更新就足够了。所以,对于用户记忆来说,批量更新 往往是更合适的选择。
总结
虽然目前有许多 AI 记忆解决方案,但大多数都存在定制化不足、效率低下或成本高昂的问题。那些一刀切的方法、复杂的函数调用以及实时更新的弊端表明,开发者需要更灵活、更实用的解决方案。我们 Memobase 团队坚信以用户为核心设计、优先采用批量更新以及存储层解耦的理念,相信这对大部分 AI 应用,尤其是2c应用,是更高效更实用的记忆方案。
Memobase:为 AI 原生应用打造的长记忆解决方案
通过深入分析现有的 AI 记忆方案,我们发现了一个明显的问题:当前的大多数解决方案在构建一个高效、灵活、可控的记忆系统上捉襟见肘,无法满足大多数 AI 原生应用的需求。这也是为什么我们开发了 Memobase,希望可以填补这个记忆解决方案的空白,帮助 AI 产品团队打造全新一代的 AI 原生应用。
为什么选择 Memobase?
Memobase 不只是一个普通的记忆解决方案。它是一种全新的理念,专门用来解决传统 AI 记忆的限制:
1. 基于用户档案的强大系统
虽然“用户档案记忆”的概念已经存在,但却缺乏真正强大、易用的开发者友好型工具,能充分释放其潜力。Memobase 则正是为了解决这一问题而生。
2. 灵活定制,让产品团队掌控记忆
我们深信,AI 产品团队应该对存储的数据以及其组织方式拥有完全的掌控权。Memobase 的灵活架构让你可以根据应用需求,自定义记忆结构。
3. 记忆分层:减负提效
Memobase 将记忆当作一个独立的存储层,而不是让 AI 在每次互动时都实时更新记忆。这种解耦的设计不仅提升了性能,还降低了成本,同时简化了开发流程。
4. 核心设计:批量处理
Memobase 支持批量处理,以异步方式更新记忆。即便你的应用需要服务大量用户,它也能保持快速响应。
Memobase 的核心功能
📁 Profile-based 的架构
-
结构化存储,易于理解和检索: Memobase 围绕用户 profile 构建记忆,提供清晰的结构,便于存储和调用信息。
-
量身定制: 你可以根据自己产品需要自定义 profile 结构。例如,健身应用可以存储用户的锻炼历史、饮食偏好和健身目标,而语言学习应用则可以记录词汇进度、语法熟练度和学习偏好。
-
随用户成长动态调整: 随着 AI 对用户了解的深入,profile 内容可以动态更新和扩展,提供更个性化的体验。
🔐 隐私与安全
-
数据所有权: Memobase 让你完全掌控用户的数据。你来决定存储什么、怎么用以及保留多久。
-
隐私至上: 内置的隐私保护功能确保符合 GDPR 等数据隐私法规。
-
审计与监控: 提供了工具来监控记忆使用情况、跟踪变化并确保数据完整性。
🌐 可扩展性与高性能
-
可扩展性: Memobase 可以轻松支持数百万用户,并随你的应用扩展而无缝扩展。
-
数据库级的效率: Memobase 借鉴成熟的数据库设计原则,确保快速、高效的信息存储和检索。
-
最低延迟: 经过性能优化,确保 AI 能在毫秒级别访问所需信息。
🤖 开发者友好
-
简单易用的 API: Memobase 提供干净、直观的 API,方便与现有工作流集成。
-
内置批量处理: 不用你自己构建异步更新机制,Memobase 已为你打包好所有必要功能。
-
丰富的文档与支持: 我们提供详细的文档和支持社区,帮你快速上手。
🚀 内置记忆模板
-
利用最佳实践: Memobase 的模板融入了来自教育、虚拟伴侣、游戏等领域的最佳实践,为主流AI 产品品类预设了一系列高效的记忆模板。
-
快速开发,专注创新: 通过直接使用模板,你可以节省时间,将精力集中在打造应用的核心差异化功能上。
-
示例: 比如,AI 伴侣模板可能会包含预定义的字段,像个性特征、用户兴趣(书籍、电影、音乐、爱好)、关系历史(重要日期、共享经历)、沟通风格偏好,甚至还有内部笑话。它还可以建议根据对话更新记忆的方法,比如情感分析来衡量用户的情绪状态,主题提取来识别关键讨论点。你可以直接使用这些模板,或者根据自己的特定需求进一步定制它们。
为了给你一个更直观的体感,下面是从我们的一个模板中摘录的一段,大致展示了可以存储的信息类别。
- topic: "Special Events"description: "用户生活中的重大事件和里程碑。"sub_topics:- name: "Anniversaries"description: "结婚纪念日、恋爱纪念日等。"- name: "Trips"description: "用户和 AI 伴侣一起进行的旅行。"- name: "Date Plans"description: "关于未来约会或外出的计划和讨论。"- topic: "Relationships"description: "记录用户的关系信息,特别是和 AI 伴侣的关系。"sub_topics:- name: "Marital Status"- name: "Friendships"- name: "Family Relationships"- topic: "Personality"description: "记录用户的个性或偏好的他人个性特征。"sub_topics:- name: "User Personality"- name: "Preferred Personality"description: "AI 伴侣的偏好个性特征(例如,温柔、冷静、有点受虐倾向、外表冷漠但内心热情、忠诚)。"- topic: "Basic Information"sub_topics:- name: "Birthday"- name: "Age"- name: "Occupation"- name: "Habits"- topic: "Interests and Hobbies"sub_topics:- name: "History"- name: "Fortune Telling"- name: "Food"- topic: "Important Memories"description: "收集事件的记忆,例如生病,每个事件类别都有子类型。"sub_topics:- name: "Illness"- name: "Final Exams"- name: "..."Memobase 的应用场景
Memobase 立志帮助 AI 原生产品打造更贴心更有温度的产品。我们在与多家头部 AI 应用的种子客户深入合作,这些应用涉及AI 虚拟陪伴,AI教育、AI 游戏等等。在这些合作中,这些合作中我们不仅共同开发并完善 Memobase 的功能,还帮助我们打磨了最佳实践的记忆模板。以下是 Memobase 的一些典型应用场景:
🎓 AI 虚拟陪伴:建立更深层的连接
-
个性化互动:让你的 AI 虚拟陪伴产品能够好的记住用户喜好、生活事件和对话内容的 ,给用户更贴心更温暖的互动体验。
-
高情商回复:记录用户的情绪状态变化,让产品能够调整自己的回应。比如当用户经常表现出低落情绪时,为用户提供适当的支持或鼓励。
-
共同成长:打造与用户一同成长和进化的产品,逐步积累共同的经历,深化彼此的情感连接。
🛎️ 教育平台:个性化学习
-
详细学生档案: 包括学习风格、优点、缺点、进步速度等,把教育体验根据每个学生的独特需求来量身定制。
-
个性化课程: 根据学生的表现动态调整课程。比如学生在某个领域很厉害,AI 就能引入更高级的概念,或者跳过他们已经掌握的内容。
-
精准帮助: 找出学习上的漏洞,及时干预。要是学生在某个概念上卡壳了,AI 就能提供额外的练习、其他的解释方式,或者给他们找些相关的资源。
✍️ AI 游戏:打造沉浸式体验
-
有记忆的 NPC : 为 NPC添加记忆功能,让他们能够记住玩家的行为,增加真实感。比如,一个商店老板记住了你的购买记录,一位任务发布者记得你的功绩,或者一个竞争对手根据你的玩法调整策略。
-
动态叙事: 根据玩家的选择和行动来编织故事。Memobase 能存玩家旅程的详细历史,让游戏生成个性化的故事线和剧情。
🏥 AI 笔记和情感疗愈
-
深入洞察: AI 可分析日记内容,发现模式、反复出现的主题和情感趋势,给用户对自己想法和感受的宝贵洞察。比如,一款应用可能发现你在缺乏运动的日子情绪较低,或者某些主题总会引发焦虑情绪。
-
个性化反思: AI 能找出相关的过往条目,帮用户反思个人成长、追踪目标进度,或者从新角度看待当前的挑战。
-
动态干预: AI 能根据用户当前的情绪状态和过往经历来调整回复和干预方式。比如用户要是正经历某种情绪问题,AI 就能想起之前成功的应对策略,或者引导他们做些稳定情绪的练习。
大模型厂商的记忆服务 vs. 第三方提供商如 Memobase,该如何抉择?
不少朋友可能会有这样的疑问:大模型厂商会不会自己推出记忆解决方案呢?我们的答案是:也许会。
据我们了解,目前大多数大模型厂商尚未推出独立的记忆服务,只有比如字节在小规模测试豆包的记忆方案。即使未来他们推出了相关解决方案,像 Memobase 这样独立且专注的记忆服务仍然是不可或缺的,其原因主要有以下几点:
1. 摆脱供应商锁定,保持灵活性
-
与不同基座模型的兼容: 大部分 AI产品团队希望保持灵活性,不和单一大模型厂商深度绑定。他们希望根据具体需求选择最合适最便宜的基座模型,甚至随着技术演变随时切换。Memobase 提供了完全独立的记忆层,无论你使用哪种基座模型都能完美兼容。
-
解耦记忆层: 通过将记忆管理与基座模型解耦,Memobase 让你的开发团队可以快速独立性构建记忆管理功能,并不对任何基座模型有依赖关系。
2. 聚焦于记忆,功能更强大
-
聚焦 AI 记忆: 打造最优质的记忆解决方案是 Memobase 的核心愿景,而不是几十甚至上百个功能之一。这使我们能够聚焦解决 AI 记忆的问题,这种专注使我们可以打磨出更具创新性、更高效的解决方案。
-
经过验证的性能: 在和我们种子用户的测试中,Memobase 的性能已超越对比基座模型厂商提供的记忆方案。
-
记忆对大模型厂商的优先不高: 大模型厂商更多关注于扩展模型能力和提升通用性能,大多数大模型厂商现在的估值让他们无法聚焦记忆,给记忆功能分配较高的优先级和投入大量的资源。
3.开源的力量
-
公开透明: 大多数大模型厂商提供的记忆功能,已经部分第三方的记忆方案是闭源的或者是黑盒模式运作,Memobase 是完全开源的。
-
社区驱动: 开源的方式鼓励社区参与和贡献,同时让开发者可以根据自己的需求对 Memobase 进行定制和扩展。
-
快速迭代创新: 开放协作的开发模式让创新速度更快,为每个人打造出一个更强大、更灵活的记忆解决方案。
🚀 即刻启程,为你的 AI 产品注入长记忆
想为你的 AI 产品快速加入长记忆功能,让她提供更贴心更温暖的用户体验吗?以下是几种快速入门方式供你选择:
1.浏览我们的 GitHub 仓库(https://github.com/memodb-io/memobase):深入了解 Memobase 的工作原理。
2.查看完整文档(https://docs.memobase.io/):我们的文档包括简单易懂的分步教程,帮助你轻松上手集成 Memobase。
3.加入我们的微信群: 与其他开发者交流,分享你的问题和反馈。也可以通过下面的二维码扫码入群,也可以添加 Memobase 团队小伙伴的微信:zhao-hanbo

Memobase 是开源项目,欢迎你贡献代码、改编项目,或基于它开发属于自己的解决方案。现在就开始着手打造更智能、更个性化、靠记忆驱动的 AI 应用吧!

以上信息由 RTE 开发者社区成员通过社区网站投稿提供,如果你也有与实时互动( Real-Time EngagementRTE) 相关的项目分享,欢迎访问网站rtecommunity.dev 发布,优秀项目将会在公众号发布分享。同时还有 RTEMeetup demo 分享、《编码人声》播客录制、RTE Open Day 展位优先申请等机会。
有意投稿者请联系微信 creators2022请备注身份和来意。