你是一个程序员,假设你维护了两个服务 A 和 B。
A 服务负责转发用户请求到 B 服务,B 服务是个算法服务,GPU 资源有限,当请求量大到 B 服务处理不过来的时候,希望能优先处理会员用户的请求。
那么问题就来了,如果普通用户和会员用户同时发起请求,怎样才能做到会员优先呢?
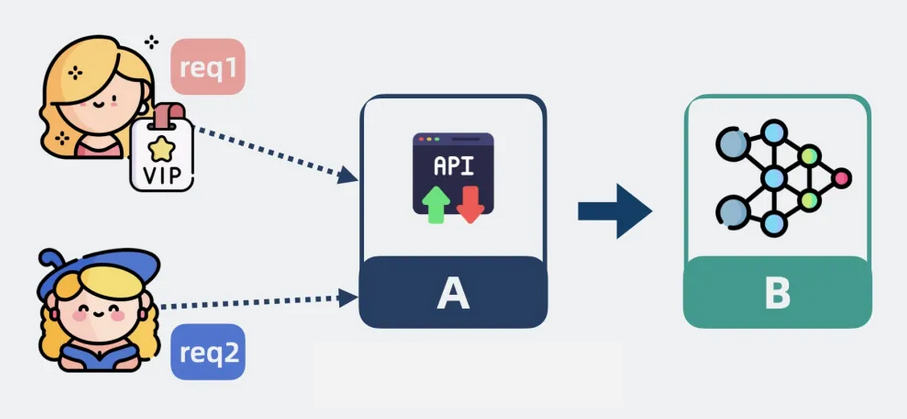
好办,没有什么是加一层中间层不能解决的,如果有,那就再加一层。
这次我们要加的中间层是 消息队列 RabbitMQ。

我们先来看下 RabbitMQ 里的核心概念,Queue。
一、Queue 是什么
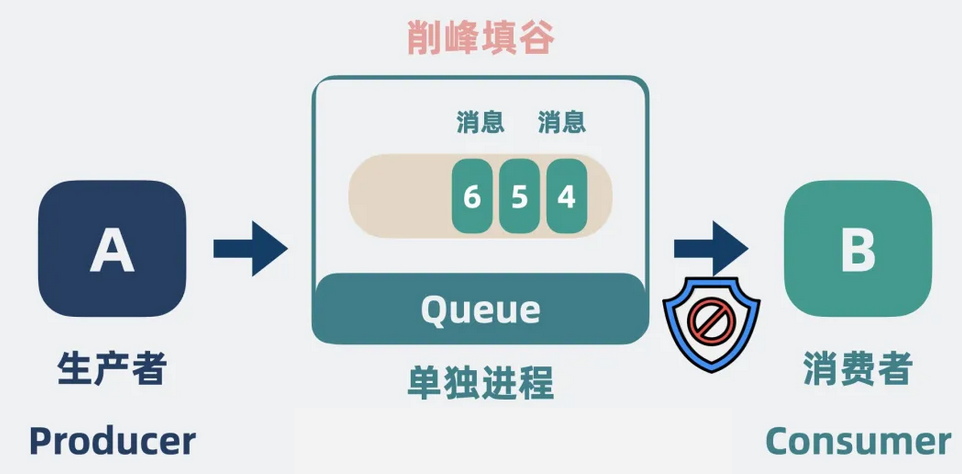
我们知道,消息队列本质上就是一个类似链表的独立进程。链表里的每个节点是一个消息。

【图】队列是类似链表的独立进程
它介于生产者和消费者之间,在流量高峰时先暂存数据,再慢慢消费数据,可以很好的保护消费者,也就是所谓的削峰填谷。
【图】削峰填谷
这个类似链表的进程,就是Queue,也叫队列。
但消息也分很多种类,比如订单消息和用户消息属于两类,为了更好地管理不同种类的数据, 可以提供多个 队列,生产者可以自定义 Queue 的名字,并且根据需要将消息投递到不同的 Queue 中。每个 Queue 都设计为独立的进程,某个进程挂了,不影响其他进程正常工作。
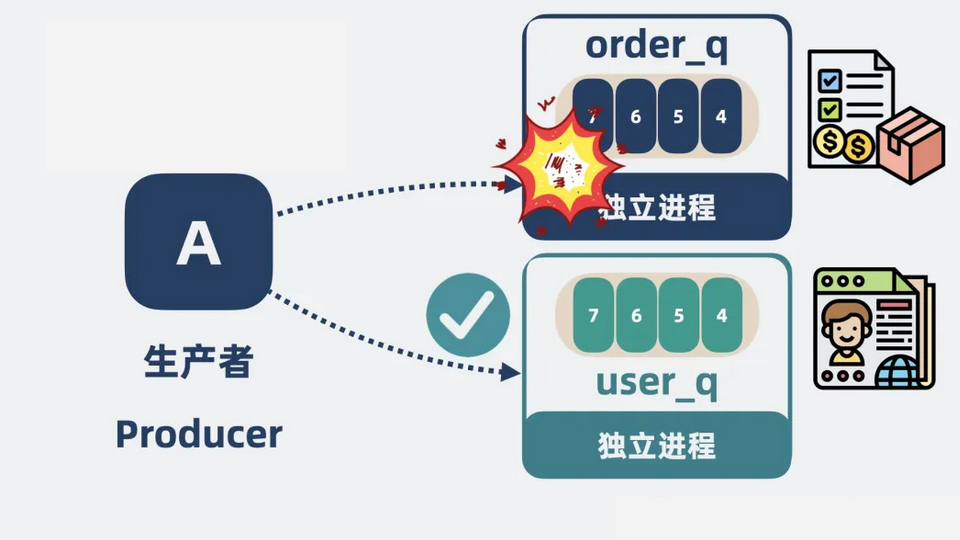
【图】A进程挂了不影响其他进程
二、Exchange 是什么
有些生产者想将消息发到一个 Queue 中,有些则是发给多个queue,甚至广播给所有 Queue ,于是 我们还需要一个可以定制消息路由分发策略的组件,交换器Exchange,将它与 Queue 绑定在一起,通过一个类似正则表达式的字符串 bindingKey声明绑定的关系,让用户根据需要选择要投递的队列。
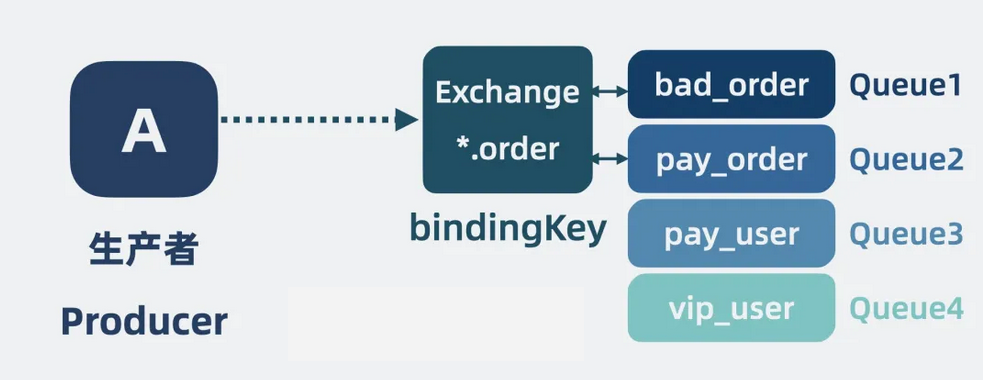
【图】Exchange是什么
这些维护在 Exchange 里的路由方式和绑定关系,我们称为元数据。
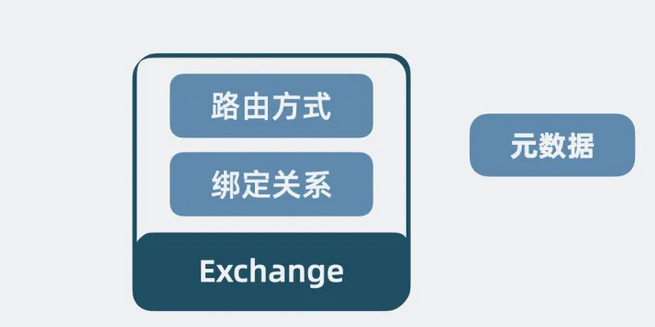
【图】元数据是什么
三、RabbitMQ 是什么
像这样一个包含多个 Queue 进程 和 Exchange 组件 的消息队列,就是所谓的 RabbitMQ。
每一台服务器上的 RabbitMQ 实例,就代表一个 Broker。
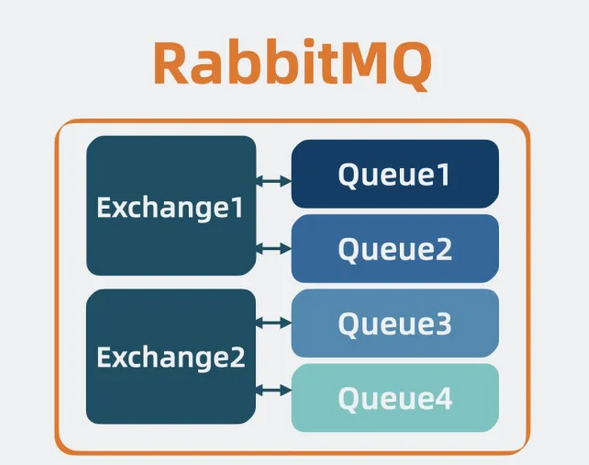
【图】RabbitMQ是什么
大佬们在这个架构的基础上,为 RabbitMQ 实现了各种丰富的特性,你能想到的 MQ 功能它基本都实现了,比如延时队列,死信队列,优先级队列等等。
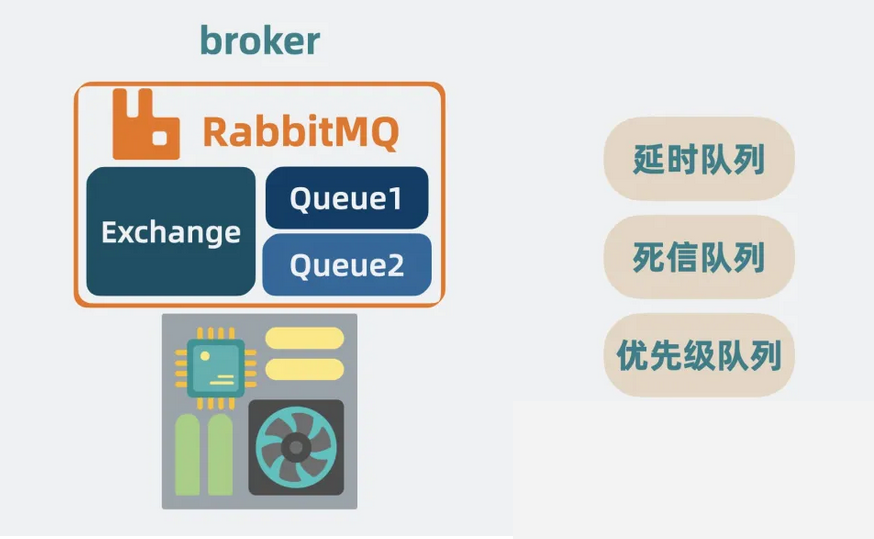
【图】RabbitMQ的功能
前两者跟 RocketMQ 的一样,在之前的视频里有提到过。这里重点看下优先级队列是什么。
三、优先级队列是什么
RabbitMQ 支持在生产者发送消息的时候,为消息标记上优先级,消费者总是消费优先级高的消息。
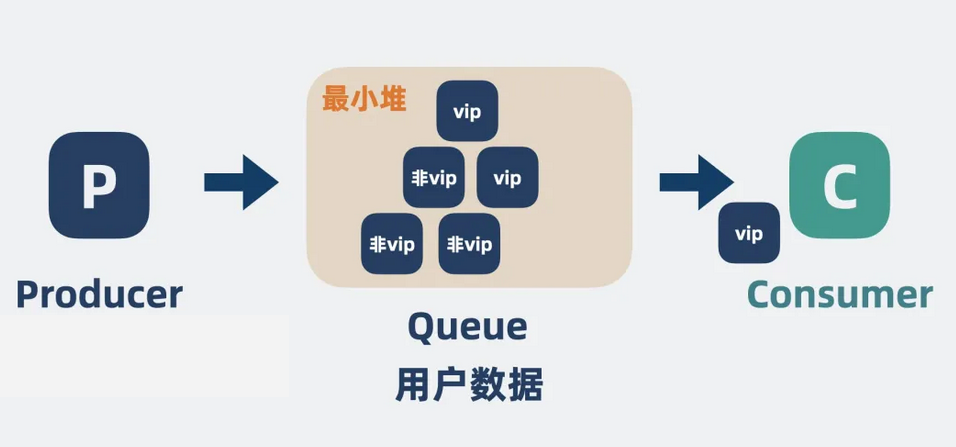
【图】优先级队列是什么
视频开头的问题,就可以通过优先级队列来完成。我们可以在 A 服务,根据用户会员等级,为消息打上对应的优先级,再投递到 RabbitMQ 中,B 服务永远优先消费高优消息,当高优消息处理完后再处理普通消息。

【图】优先级队列的应用1
这个功能非常有用,现在到处都是 AI,恨不得将一块 GPU 掰成 10 块用,比如某聊天 AI,当服务遭到大量访问时,免费用户会感觉很慢甚至报错,但会员用户依旧响应丝滑。

【图】优先级队列的应用
到这里,大家估计也发现了,虽然 RabbitMQ 功能很丰富,但它的架构就是个单实例节点,有些过于简单了,像什么高可用和高扩展,那是一个都不沾。
我们来看下 RabbitMQ 是怎么扩展这部分能力的。
四、RabbitMQ 集群
既然单节点存在诸多问题,那就让多个节点构成集群。
我们可以在多个服务器上各部署一个 RabbitMQ 实例,并通过执行 RabbitMQ 提供的命令,将这些实例组成一个集群。
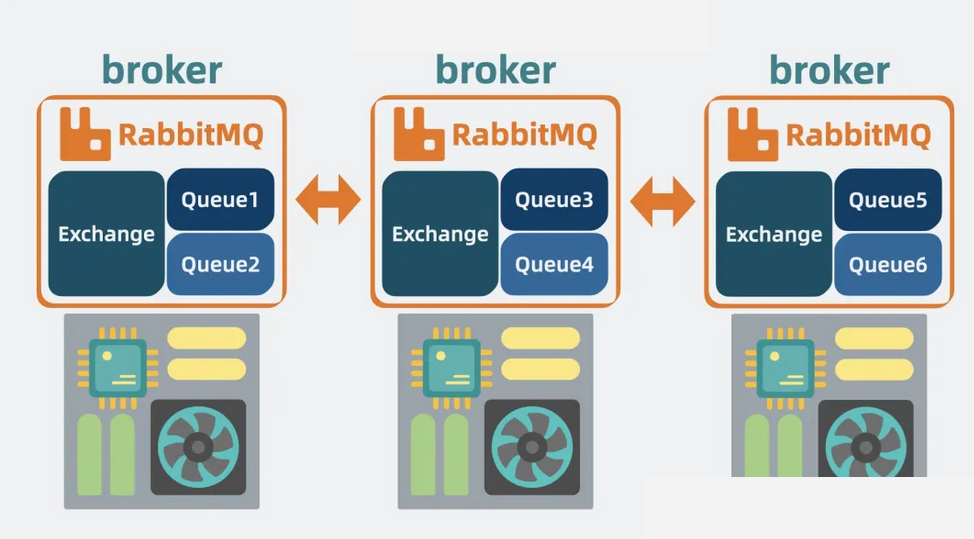
【图】RabbitMQ集群
RabbitMQ 支持多种集群模式。我们依次来看下。
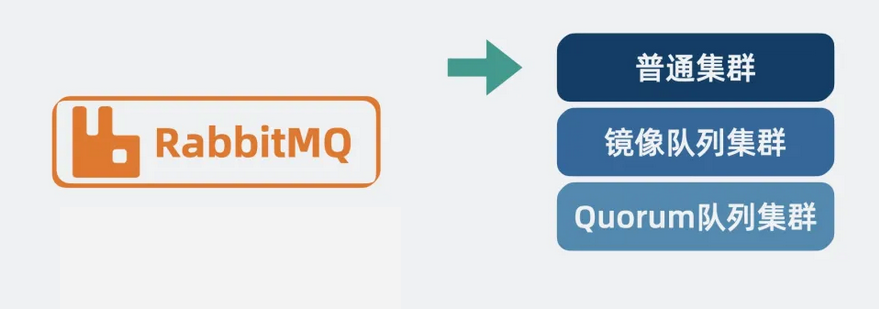
【图】多种集群模式
普通集群模式
在普通集群模式中,每个 Broker 都是一个完整功能的 RabbitMQ 实例,都能进行读写。
他们之间会互相同步 Exchange 里的元数据,但不会同步 Queue 数据。
假设 Queue1、Queue2、Queue3 分别部署在 Broker1、Broker2、Broker3中。
• 对于写操作:生产者将消息写入到 Broker1 的 Queue1 后,Queue1 里的数据并不会同步给其他 broker。但如果此时 Broker1 的 Exchange 元数据有变化,则会将元数据同步到其他两个 Broker 中。
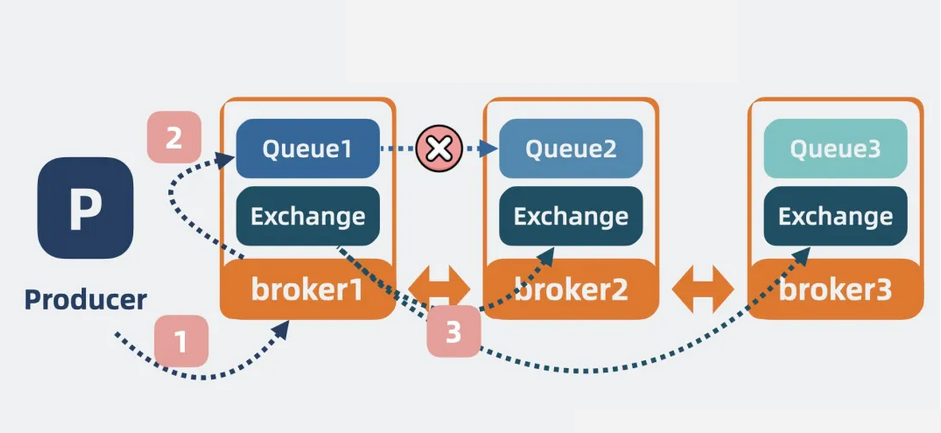
【图】写操作
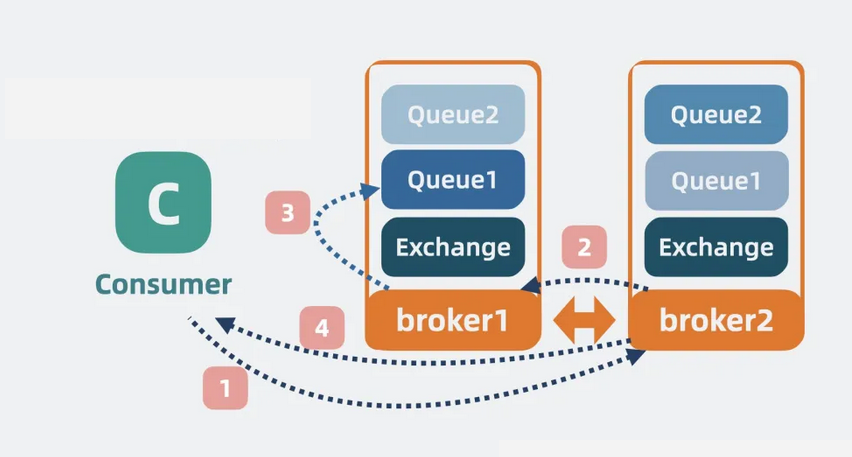
• 对于读操作:消费者想要读取 Queue1 数据时,如果访问的是 Broker1,则直接返回 Queue1 中的数据。
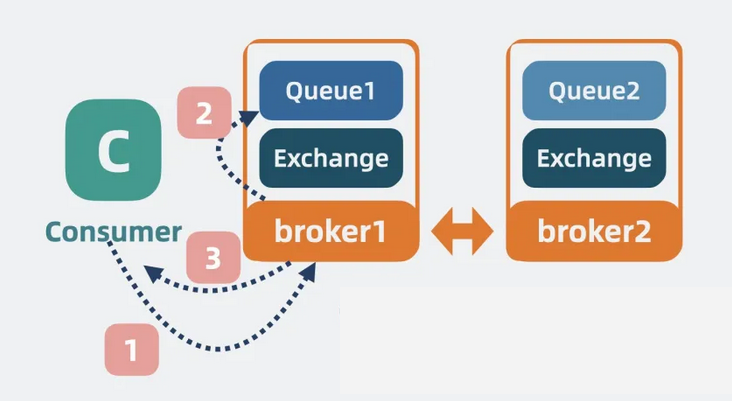
【图】消费消息1
但如果访问的是 Broker2,Broker2 则会根据 Exchange 里的元数据,从 Broker1 那读取数据,再返回给消费者。
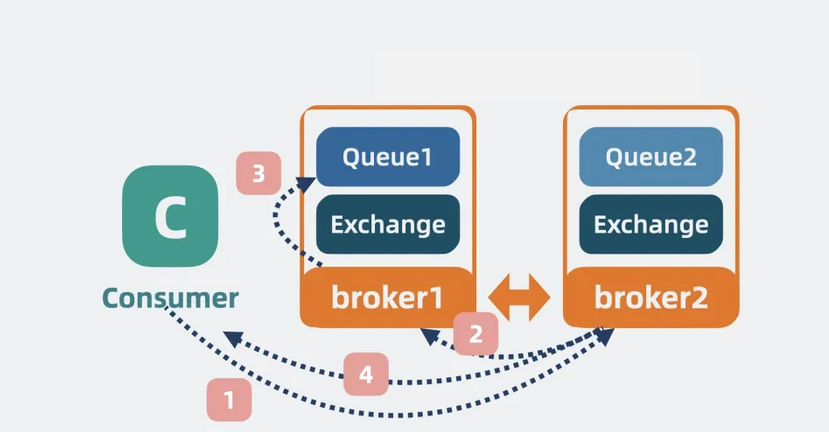
【图】消费消息2
这样就可以通过增加 Broker,提升 RabbitMQ 集群整体的吞吐量,保证了扩展性。
但问题也很明显。
• 虽然支持读写 Queue 的数量是增加了,但对于单个Queue 本身的读写能力,并没有提升。
• 而且更重要的是,每个 Broker 依然有单点问题,Broker 之间并不同步 Queue 里的数据。某个 Queue 所在的 Broker 要是挂了,就没法读写这个 Queue 了。
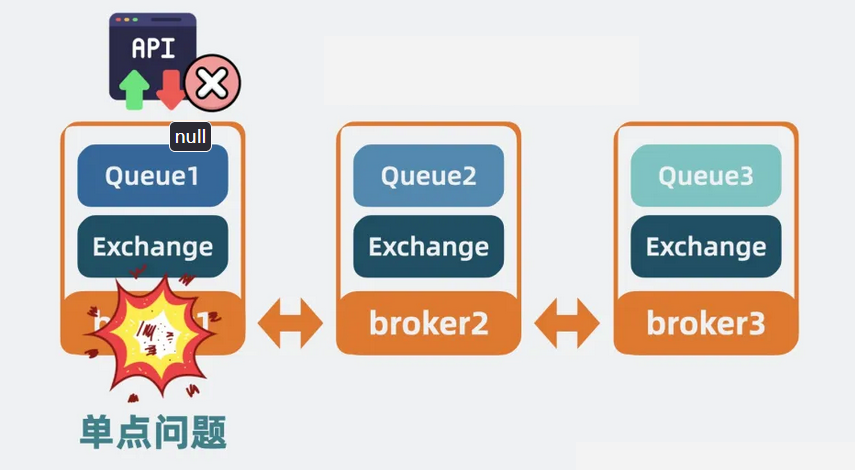
【图】单点问题
这跟高可用毫不沾边。
有更好的方案吗?
镜像队列集群
参考下你那个,手机里有很多沸羊羊的相亲对象,没人比 ta 更懂什么是高可用。
我们可以在普通集群模式的基础上, 给 queue 在其他 broker 中加几个副本, 它们有主从关系,主 queue 负责读写数据,从 queue 负责同步复制主 queue 数据, 所以从 Queue 也叫镜像队列。
一旦主 Queue 所在的 broker 挂了,从 Queue 就可以顶上成为新的主 Queue,实现高可用。这就是所谓的镜像队列集群。
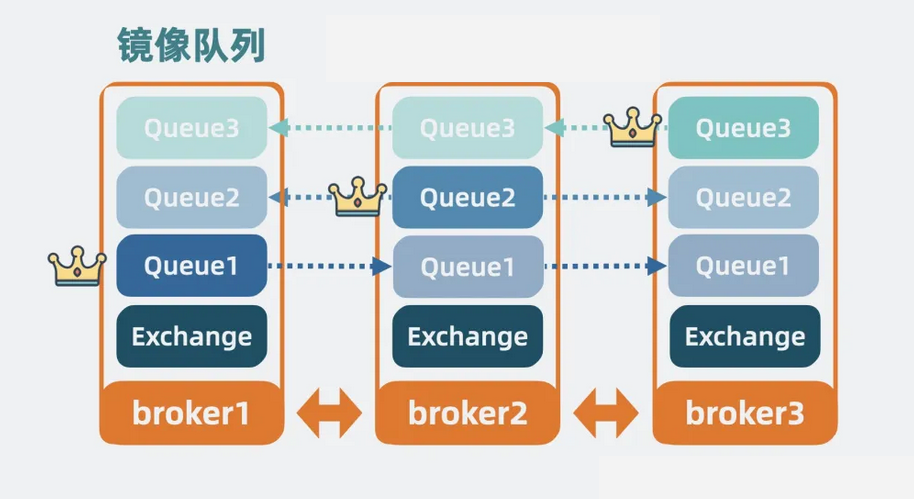
【图】镜像队列集群
• 对于写操作:数据写入主 Queue 后,会将 Exchange 和 Queue 数据同步给其他 Broker 上。
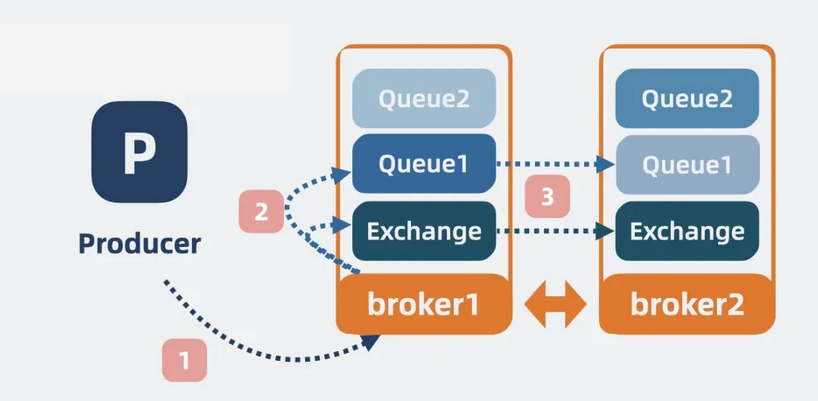
【图】写操作
• 对于读操作:消费者读取数据时,如果访问的是主 Queue所在的broker,则直接返回数据。
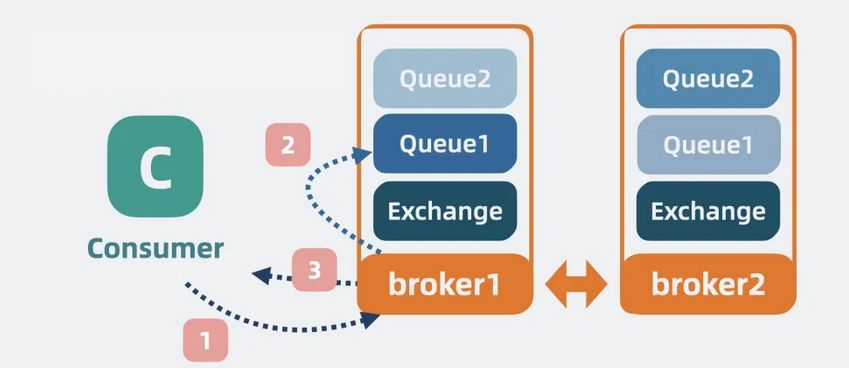
【图】消费消息1
• 否则,当前 broker 会从主 queue 所在的 broker 上读取数据,之后返回给消费者。
【图】消费消息2
但这个方案的缺点也很明显,broker 间同步的数据量会变大,集群节点越多带宽压力越大,本质上镜像队列模式是通过牺牲吞吐量换取的高可用。
反观前面的普通集群模式,虽然吞吐高但却牺牲了高可用
还是那句话,做架构做到最后,都是在做折中。又升华了。
Quorum 队列集群
看到这里不知道大家有没有发现一个问题,RabbitMQ 集群中每个节点都能知道某个 Queue 具体在哪个 Broker 上,说明 Broker 间有个机制可以互相同步元数据,但架构中却没有一个类似 kafka 的zookeeper那样的中心节点。那它是怎么在多个节点间同步数据的呢?
这是因为 RabbitMQ 基于 erlang 进行开发,这是个很特别的语言,它自带虚拟机和分布式通信框架,RabbitMQ 通过这个分布式通信框架,在 Broker 间同步元数据。
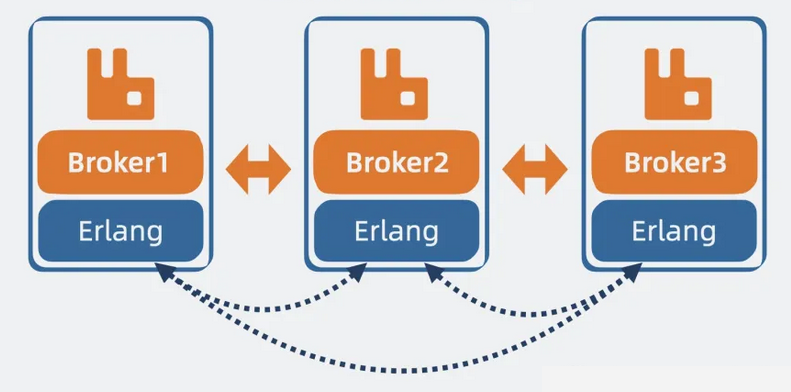
【图】基于erlang分布式通信框架同步元数据
但它有个问题,如果broker间通信断开,镜像队列可能出现多个节点都认为自己是主节点的情况,导致数据不一致,也就是所谓的脑裂问题。
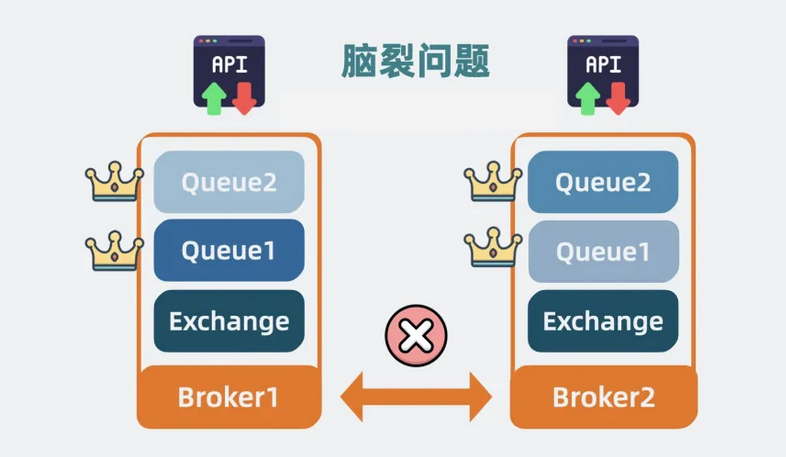
【图】脑裂问题
有解法吗?有!
我们可以使用更靠谱的一致性算法raft,来同步多个broker的元数据和队列数据,通过引入选举机制来解决网络分区问题,这就是所谓的 Quorum 队列集群。
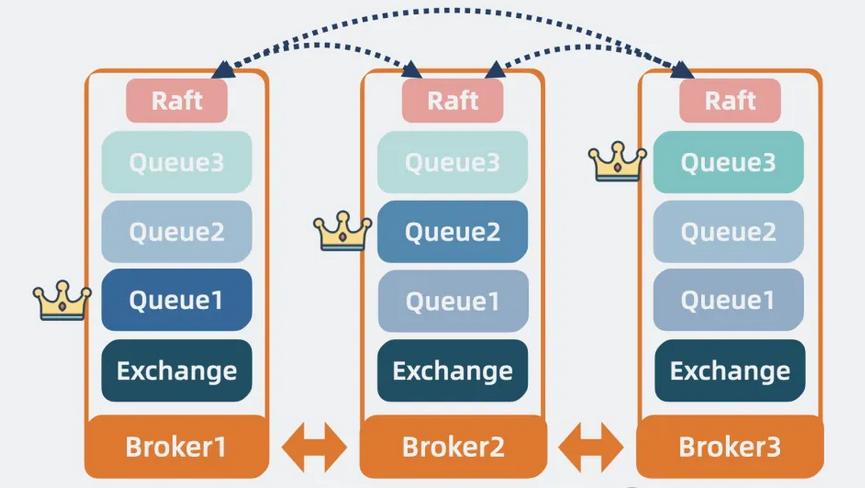
【图】Quorum队列集群
虽然官方推荐大家使用 Quorum 队列集群,并宣布镜像队列集群已被弃用,但目前大部分公司还是用的镜像队列集群。
嘿嘿,做架构,又不是追时髦,在成本和效率可控的情况下,人和系统,有一个能跑就行。
现在大家通了吗?
最后遗留一个问题。
想必你听说过互联网三大消息队列,kafka、rocketMQ、RabbitMQ。曾经阿里云团队对它们做过压测,同等条件下,kafka 吞吐量是每秒 17w ,rocketMQ 每秒 10w,而 RabbitMQ 则是 5w。
这就很奇怪了,RabbitMQ 虽然比 RocketMQ 功能要丰富些,但差异却并不大,为什么性能比 RocketMQ 差这么多?
如果大家感兴趣,我们有机会聊聊。
但问题又来了,我怎么才能知道大家感兴趣呢?
总结
RabbitMQ 是一个消息队列系统,它通过队列(Queue)来暂存数据,实现生产者和消费者之间的解耦,以及流量高峰时的削峰填谷。
Queue(队列)是 RabbitMQ 中的基本存储单元,用于存储消息。Exchange 是路由分发组件,用于将消息分发到一个或多个队列。
RabbitMQ 原生支持多种高级特性,如延时队列、死信队列和优先级队列。特别是优先级队列,允许根据消息的优先级进行消费,在 GPU 资源紧俏的 AI 服务场景中非常好用。
RabbitMQ 集群:为了提高性能和可用性,RabbitMQ 可以通过多节点构成集群:
• 普通集群模式:每个节点都有完整的 RabbitMQ 实例,可以实现读写分离,但单个队列的读写能力没有提升,且存在单点问题。
• 镜像队列模式:主节点将数据同步到从节点,实现高可用性,但会牺牲一定的吞吐量。
• Quorum 队列模式:通过 raft 的一致性算法来同步多个 broker 间的 queue 和元数据。
原创 靓仔白 小白debug