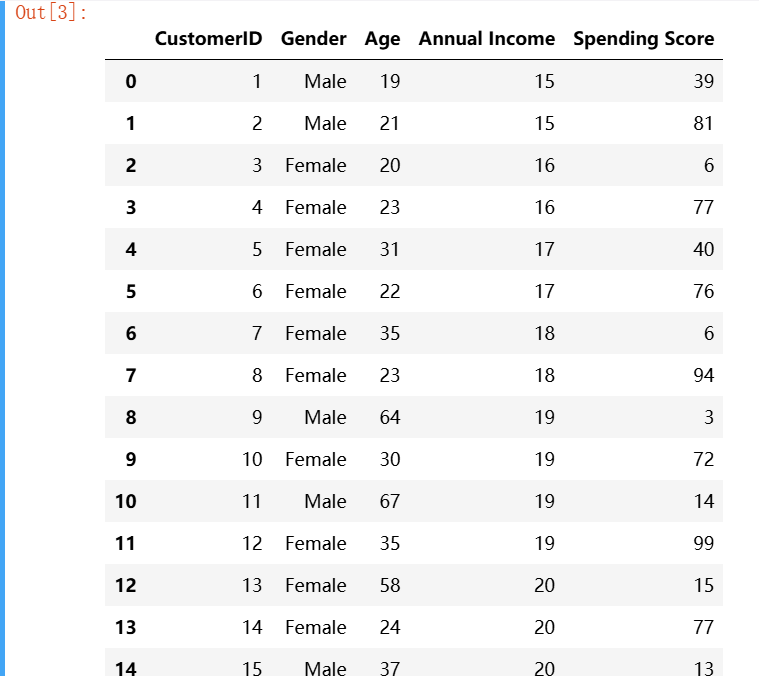
#获取数据 import pandas as pd infor=pd.read_csv('buy_input_1.csv') infor.head(20)
|
|
|
|
|
#选取预观察数据#方法1 # x1=infor["Annual Income"] # print(x1) # x2=infor["Spending Score"] # print(x2)# """ #方法2 # x1=infor.iloc[:,3] # print(x1) # x2=infor.iloc[:,4] # print(x2) # """#方法3 x1 = infor.loc[:, 'Annual Income'] print(x1) x2 = infor.loc[:, 'Spending Score'] print(x2)
|
|
|
|
|
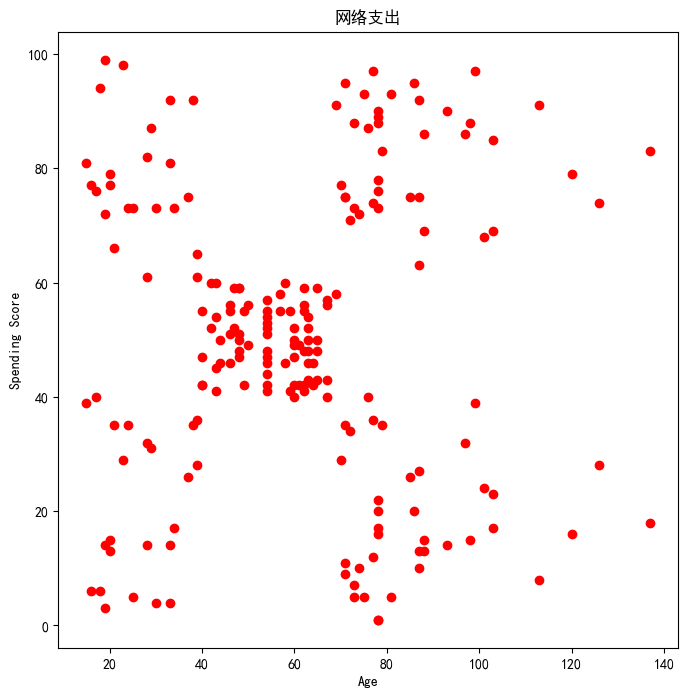
3.进行数据可视化,绘制散点图 |
|
import matplotlib.pyplot as plt
#保证可以显示中文字体
plt.rcParams['font.sans-serif']=['SimHei']
#正常显示负号
plt.rcParams['axes.unicode_minus']=False#绘制聚类结果2维的散点图
plt.figure(figsize=(8,8))#选取两个数据维度进行可视化(x1,x2)x1维度会呈现在x坐标轴,x2维度会呈现在y坐标轴
plt.scatter(x1,x2,c="red")
plt.xlabel('Age')
plt.ylabel('Spending Score')
plt.title("网络支出")
plt.show()
|
|
|
|
|
1.数据导入 |
|
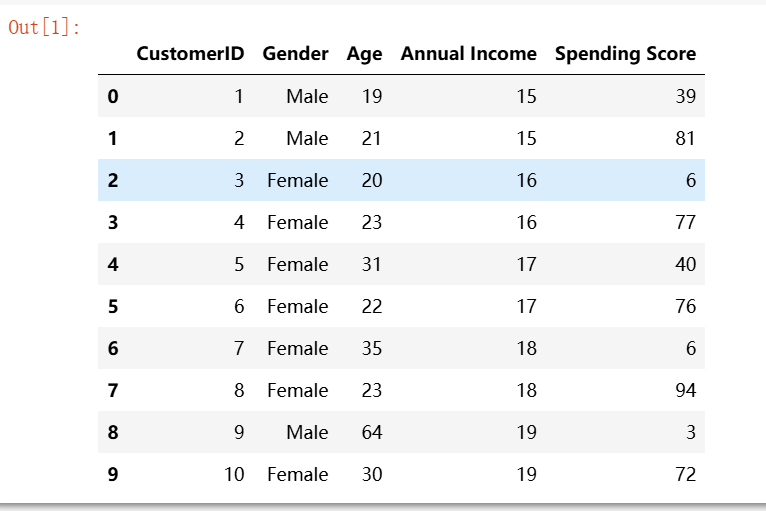
#导入库函数 import pandas as pd #读取“用户信息”,并预览数据 user_infor=pd.read_csv('./buy_input_1.csv') user_infor.head(10)
|
|
|
|
|
2.数据处理2.1选取数据(特征) |
|
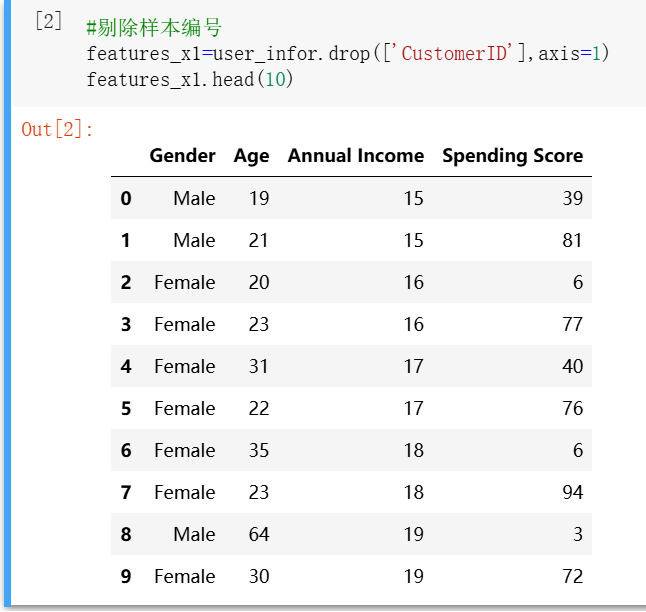
#剔除样本编号 features_x1=user_infor.drop(['CustomerID'],axis=1) features_x1.head(10)
|
|
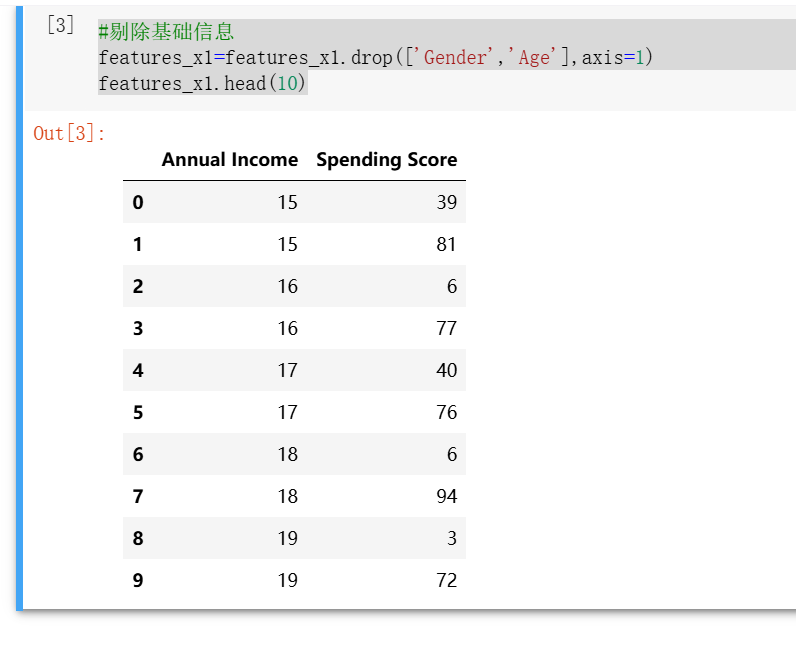
#剔除基础信息 features_x1=features_x1.drop(['Gender','Age'],axis=1) features_x1.head(10)
|
|
| ## 2.2数据可视化 | |
#选取预观察数据x1=user_infor["Annual Income"] print(x1) x2=user_infor["Spending Score"] print(x2)
#导入库函数
import matplotlib.pyplot as plt#创建图表,并设置属性
plt.figure(figsize=(8,8))plt.title('Annual Income/Spending Score')
plt.xlabel('Annual Income')
plt.ylabel('Spending Score')#选择特征数据(x1,x2)
plt.scatter(x1 ,x2 ,c='red')#显示图表
plt.show()
|
|
3.测试算法3.1配置算法(确定K值)¶ |
|
from sklearn.cluster import KMeans #进行K-Means聚类分析#修改n_clusters=? #修改n_init=? #修改max_iter=? kmeans=KMeans(n_clusters=2,init='k-means++',n_init=2,max_iter=100,random_state=0)
3.2使用算法(计算类别标签)kmeans.fit(features_x1) #将数据特征喂入模型 label_y1=kmeans.predict(features_x1) #预测类别标签 print(label_y1) #打印类别标签
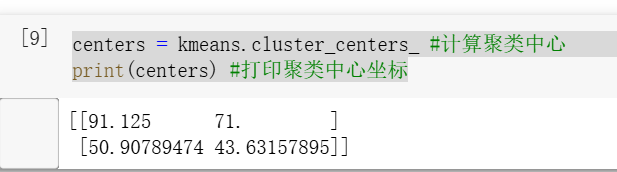
3.3计算聚类中心(质心)centers = kmeans.cluster_centers_ #计算聚类中心 print(centers) #打印聚类中心坐标
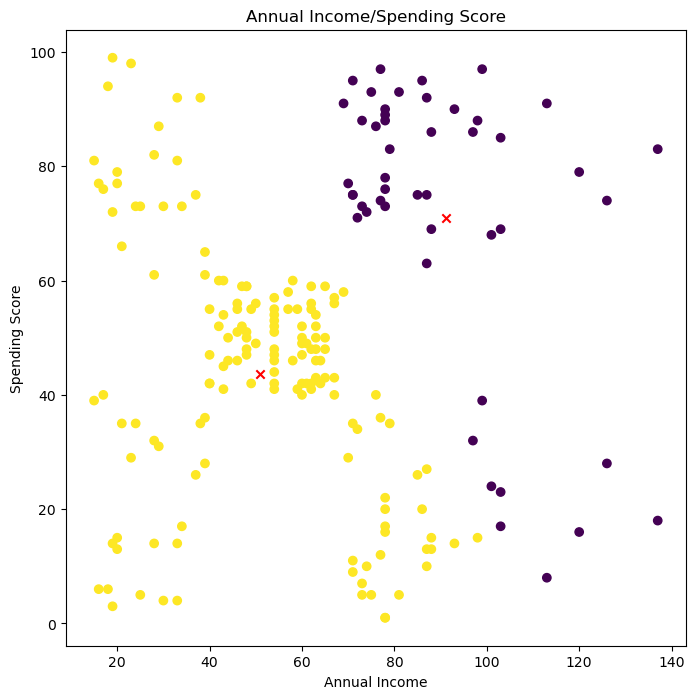
3.4标记聚类中心(质心是否改变)¶
import matplotlib.pyplot as plt#创建图表,并设置属性
plt.figure(figsize=(8,8))plt.xlabel('Annual Income')
plt.ylabel('Spending Score')
plt.title('Annual Income/Spending Score')#按类别绘制“用户画像”
plt.scatter(x1,x2, c=label_y1)#标注聚类中心坐标
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='x')#显示图表
plt.show()
3.5应用算法
kmeans.fit(features_x1) #将数据特征喂入模型 label_y1=kmeans.predict(features_x1) #预测类别标签 print(label_y1) #打印类别标签
|
|
| buy_input_1.csv | |
|
CustomerID,Gender,Age,Annual Income,Spending Score |










![[护网必备]2018年-2024年HVV 6000+个漏洞 POC 合集分享](https://img2024.cnblogs.com/blog/3593954/202501/3593954-20250118123446654-72153953.png)
