算法部署简介
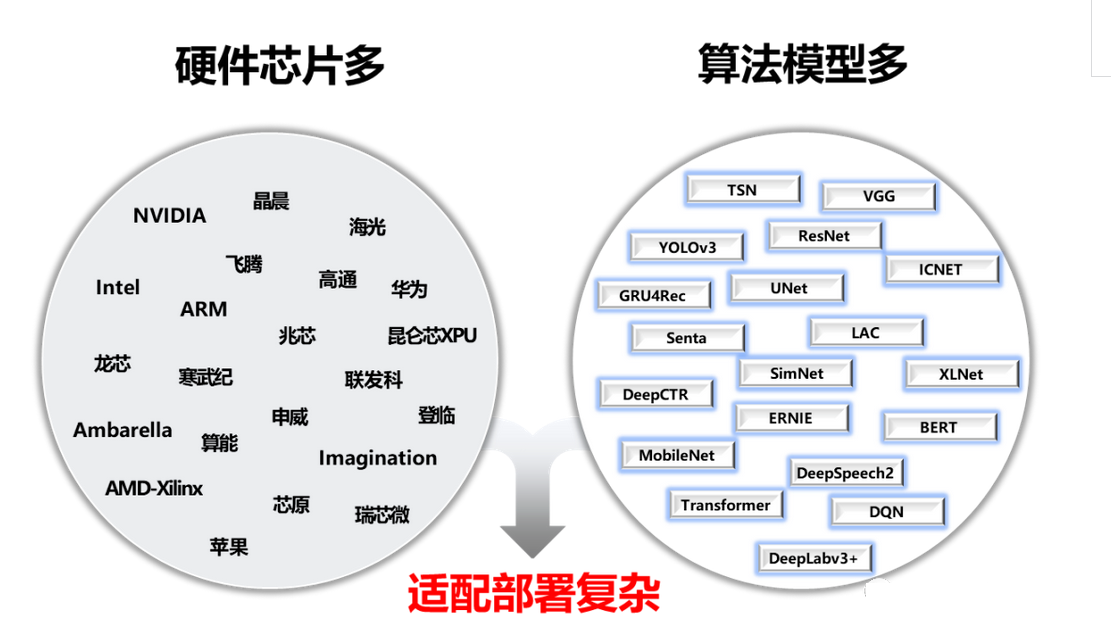
算法部署任务是将已开发的算法模型应用到实际场景中去的过程。这个过程通常需要在计算机、服务器或其它硬件设备上面运行算法模型,并编写一些代码来调用模型。任何模型其实都会涉及到模型部署任务,其实你在调用现成的API接口做推理的过程也可以叫做模型部署。模型部署任务的复杂度在于:需要利用N+个训练框架在N+个芯片上面部署N+个算法模型。
在算法部署任务中,需要考虑以下几个方面:
1、硬件环境:根据算法模型的规模和计算量,选择合适的硬件环境。例如,对于深度学习模型,可能需要使用GPU加速计算。
2、软件环境:根据算法模型的需求,选择合适的操作系统、开发工具和库等软件环境。例如,对于Python开发的机器学习算法,可能需要安装numpy、pandas、scikit-learn等库。
3、 数据输入输出:考虑如何将实际场景中的数据输入给算法模型,并将模型输出集成到业务流程中。例如,对于图像识别算法,可能需要通过摄像头捕捉图像,并将识别结果显示在屏幕上。
4、安全性:保护算法模型的安全性是非常重要的。需要考虑如何防止恶意攻击和未经授权的访问。例如,可以采用数据加密、身份验证和访问控制等措施来保护算法模型。
5、可扩展性:随着业务的扩展,可能需要在不同的计算机或服务器上部署多个算法模型,并将它们集成到一个系统中。需要考虑如何实现模型之间的协作和数据共享,并确保系统的高可用性和可扩展性。
算法部署任务需要综合考虑以上因素,以确保算法模型能够顺利地应用到实际场景中去。一个成功的算法部署可以帮助企业提高效率、降低成本,甚至创造新的商业机会。
算法部署工具链
算法部署工具链是指将AI算法从开发、测试到上线部署的整个过程所需要使用的软件工具集合。当前市面上的工具链可以划分为工业界部署工具链和学术界部署工具链。
工业界
1、MNN:https://www.mnn.zone/m/0.3/
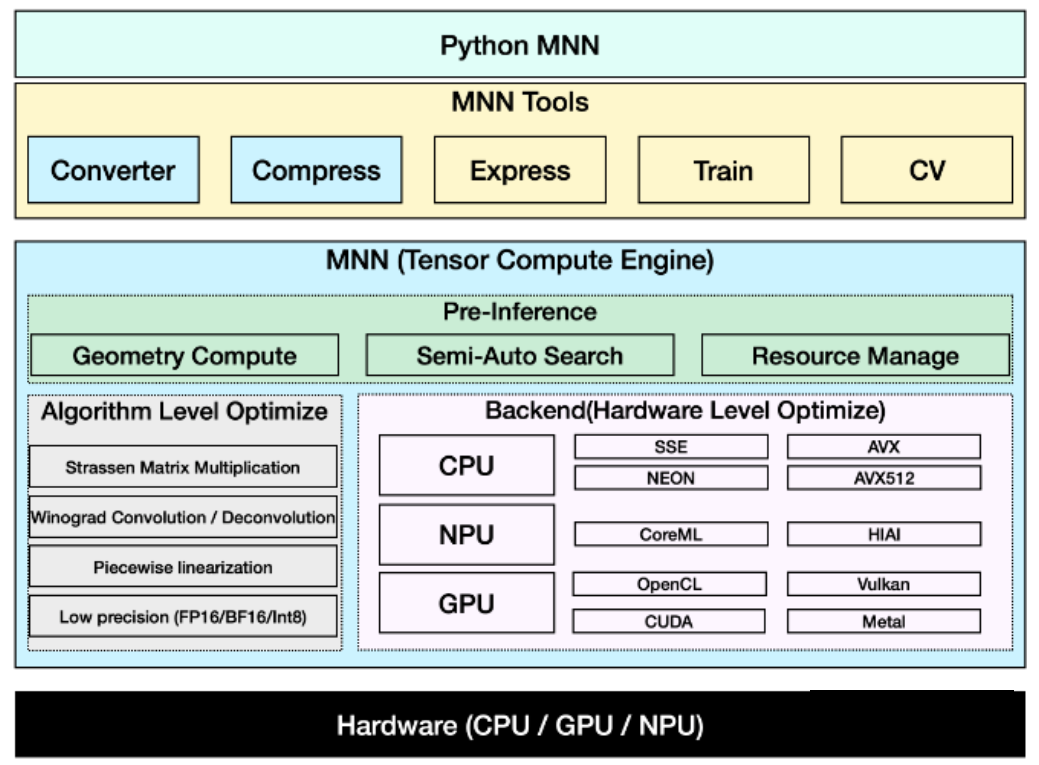
【简介】:
MNN是阿里巴巴开发的跨平台深度学习推理引擎,支持多种硬件平台和通用CPU,提供了C++、Java和Python等多种语言的API接口,可以快速地将训练好的深度学习模型部署到移动端、嵌入式设备和服务器等环境中。MNN的推理引擎具有高性能、低延迟和高灵活性的特点,支持多种常见的深度学习框架,包括Caffe、TensorFlow、PyTorch和ONNX等。同时,MNN也提供了丰富的模型转换和优化工具,可以帮助开发者更好地管理和调优模型。
【文档】:
https://github.com/alibaba/MNN/tree/master/docs
【特点】:
高性能、低延迟、高灵活性、支持多种前端、完整的模型与转换工具
2、TIDL:https://github.com/TexasInstruments/edgeai-tidl-tools
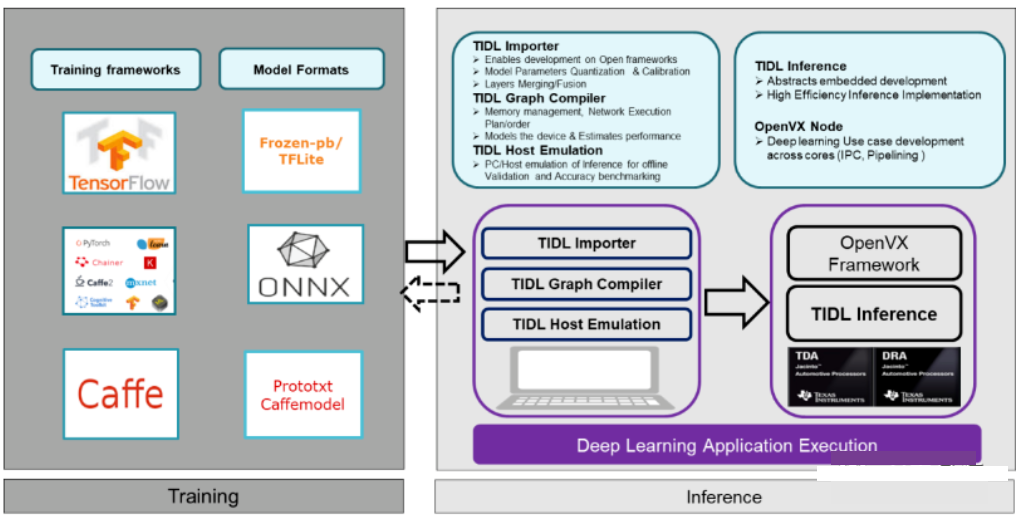
【简介】:
TIDL(Texas Instruments Deep Learning)是Texas Instruments公司开发的一个深度学习推理引擎平台,旨在为基于TI处理器的嵌入式应用提供高效、低功耗的深度学习模型推理方案。TIDL部署工具提供了一系列工具和库,包括基于OpenMP加速的CPU推理库、支持C66x DSP硬件加速的DSP推理库、以及TensorFlow Lite、ONNX等深度学习框架的接口支持等。这些工具可以帮助开发者将训练好的深度学习模型有效地部署到TI处理器平台上。
【文档】:
https://software-dl.ti.com/jacinto7/esd/processor-sdk-rtos-jacinto7/06_02_00_21/exports/docs/tidl_j7_01_01_00_10/ti_dl/docs/user_guide_html/index.html
【特点】:
支持多种硬件平台、多前端支持、灵活的定制能力、高效的性能和低延迟、易于集成与部署
3、SNPE:https://developer.qualcomm.com/sites/default/files/docs/snpe/overview.html
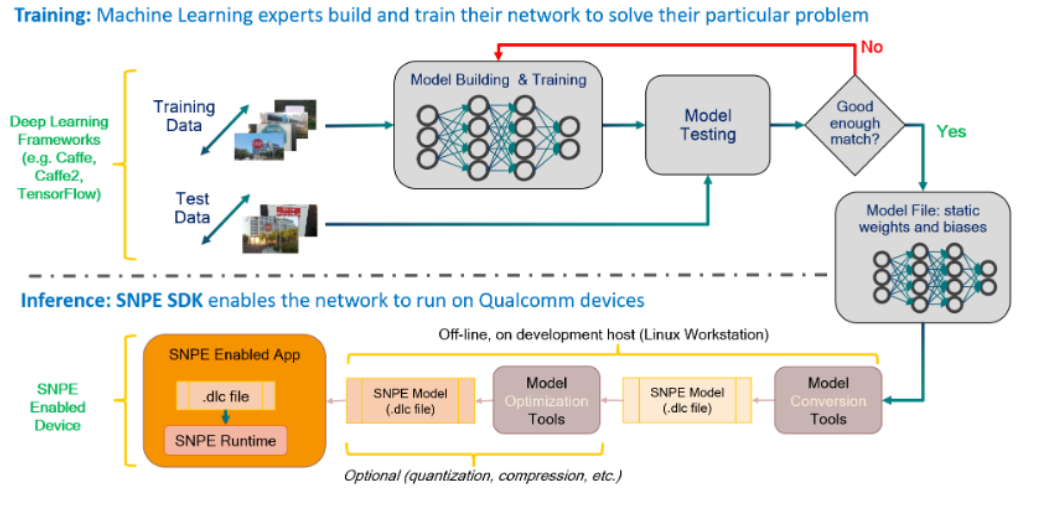
【简介】:
高通的SNPE(Snapdragon Neural Processing Engine)工具链是一种用于加速神经网络推理的软件工具链,它可以在高通的骁龙芯片上运行,实现高效、低延迟的推理计算。
【文档】:
https://developer.qualcomm.com/sites/default/files/docs/snpe/overview.html
【特点】:
支持多种神经网络模型、支持异构计算平台、高性能、易使用、支持多种编程语言、支持移动端应用
4、MACE:https://github.com/XiaoMi/mace
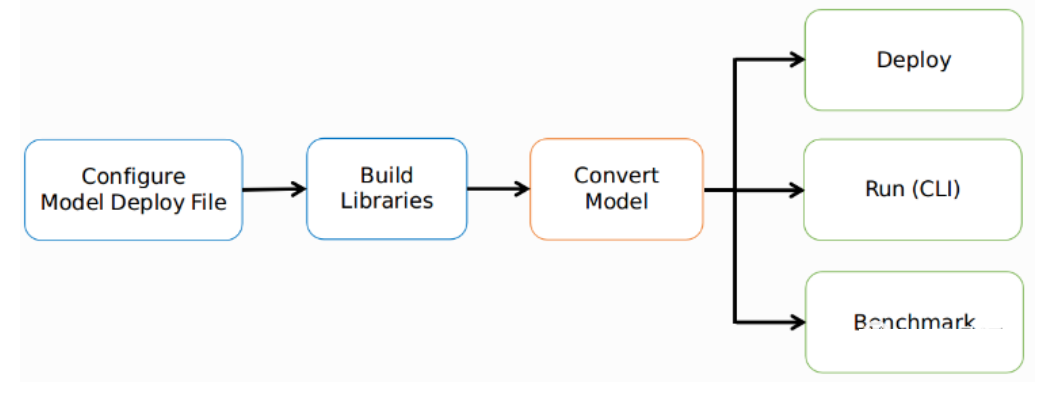
【简介】:
小米MACE(MACE AI Computing Engine)部署工具是小米公司推出的一个深度学习计算引擎。它提供了高效的模型框架、模型转换工具以及部署库,支持多种硬件平台,并且为嵌入式设备提供了低功耗的深度学习解决方案。MACE还提供了用于量化、融合和剪枝等模型优化工具,以便在硬件上部署更小、更快、更准确的模型。
【文档】:
https://github.com/XiaoMi/mace/blob/master/README_zh.md
【特点】:
高性能、低功耗、内存占用少、模型加解密、支持多种硬件和系统
5、RKNN:https://github.com/rockchip-linux/rknn-toolkit
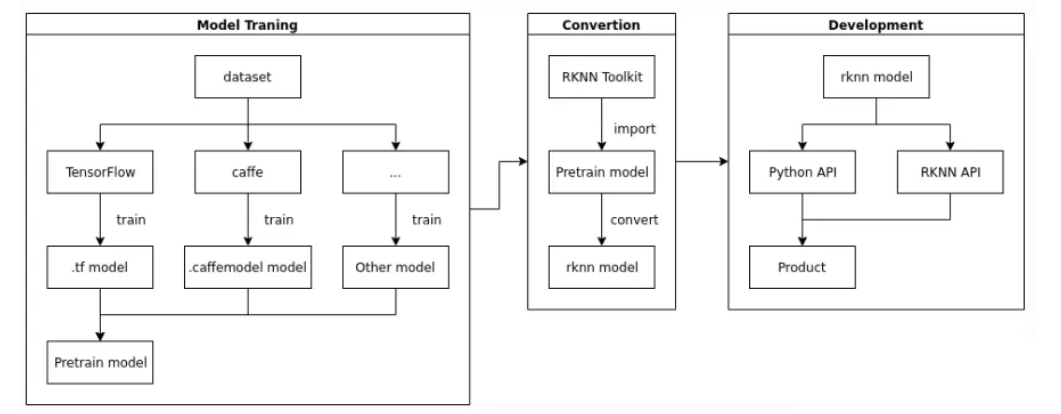
【简介】:
瑞芯微RKNN(Rockchip Neural Network)是一款高效、轻巧的深度神经网络(DNN)算法部署工具。它支持多种常见的深度学习框架(如TensorFlow、Caffe和MXNet等),可以将训练好的模型导出为RKNN格式,然后在RK3399Pro等瑞芯微开发板上进行部署。正在构建的一代RKNN NPU也将支持异构硬件部署。
【文档】:
https://wiki.t-firefly.com/en/3399pro_npu/npu_rknn_toolkit.html
【特点】:
支持多种前端、支持多种硬件、高性能、社区完善
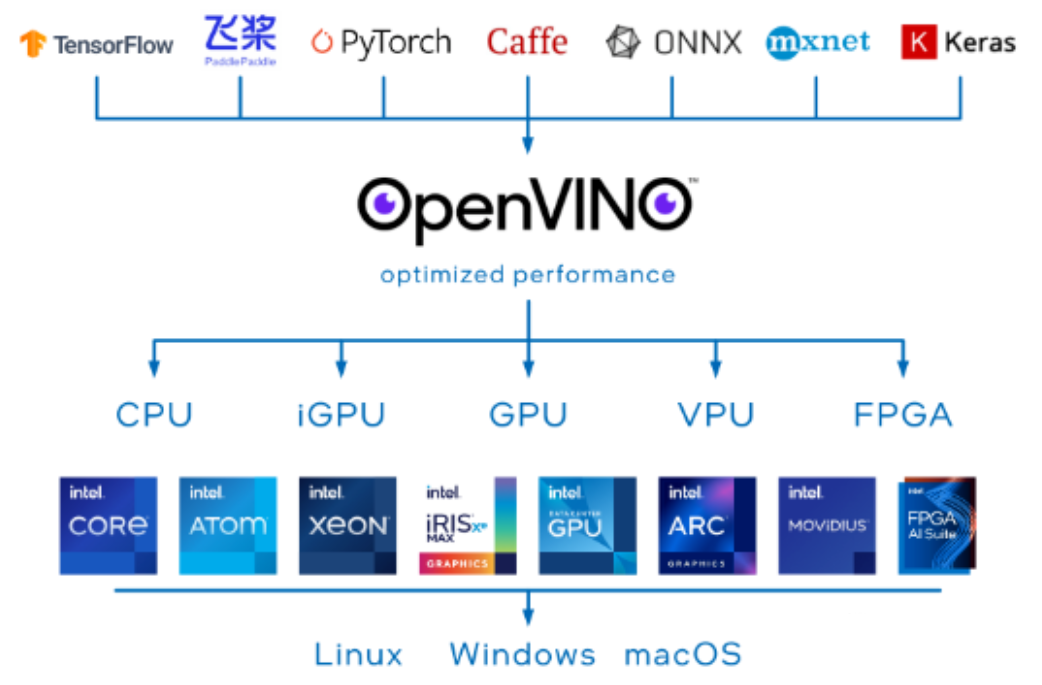
6、OpenVIO:https://github.com/openvinotoolkit/openvino
【简介】:
Intel的OpenVINO(Open Visual Inference and Neural Network Optimization)工具链是一个允许用户优化和部署深度学习模型的平台。它提供了许多工具,允许用户使用已经存在的框架(例如TensorFlow,Caffe,ONNX等)来构建深度学习模型,并使用特定于Intel处理器的优化工具来加速模型在设备上的推断。
【文档】:
https://docs.openvino.ai/latest/home.html
【特点】:
高性能、跨平台、多前端支持、多硬件支持
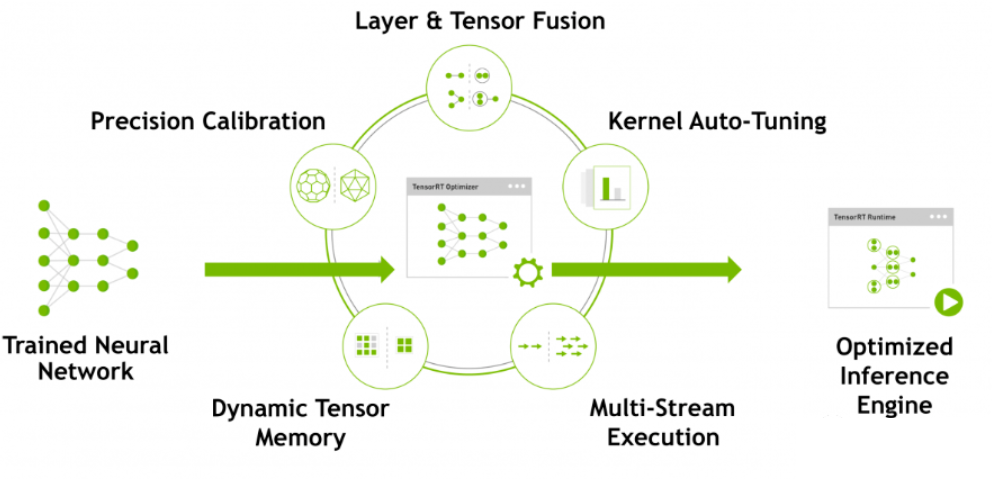
7、TensorRT:https://github.com/NVIDIA/TensorRT
【简介】:
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。
【文档】:
https://developer.nvidia.cn/zh-cn/tensorrt
【特点】:
针对GPU特定优化,支持TensorCore、多语言支持、多框架支持、高效灵活
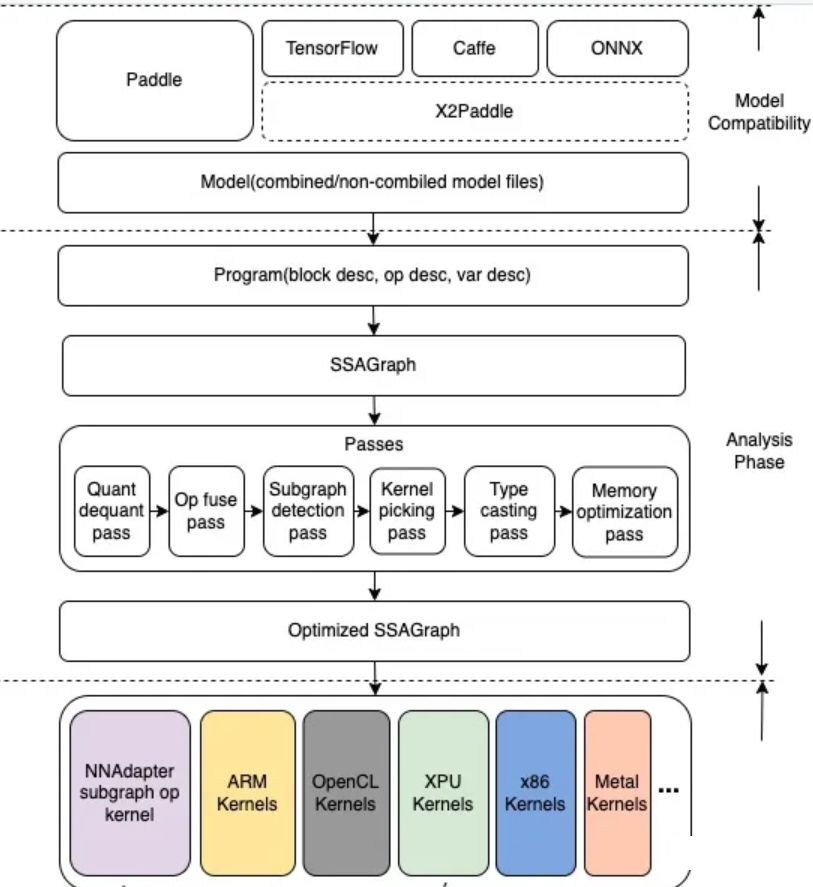
8、PaddleLite:https://github.com/PaddlePaddle/Paddle-Lite
【简介】:
百度的PaddleLite是一个面向端侧场景的轻量化推理引擎,它可以实现飞桨模型在x86/ARM平台下多种OS内的高效部署,同时支持在10种以上的GPU/NPU异构后端上进行推理加速和混合调度。
【文档】:
https://www.paddlepaddle.org.cn/lite
【特点】:
支持多平台、支持多种语言、轻量化、高性能
9、ONNXRuntime:https://github.com/microsoft/onnxruntime
【简介】:
ONNX Runtime是由Microsoft等机构开发的深度学习推理引擎,可以将已经训练好的深度学习模型转换为ONNX格式后进行高效的推理,支持多平台、多框架的部署。
【文档】:
https://onnxruntime.ai/
【特点】:
跨平台、多后端、易使用、性能一般
10、NNIE-https://github.com/mxsurui/NNIE-lite
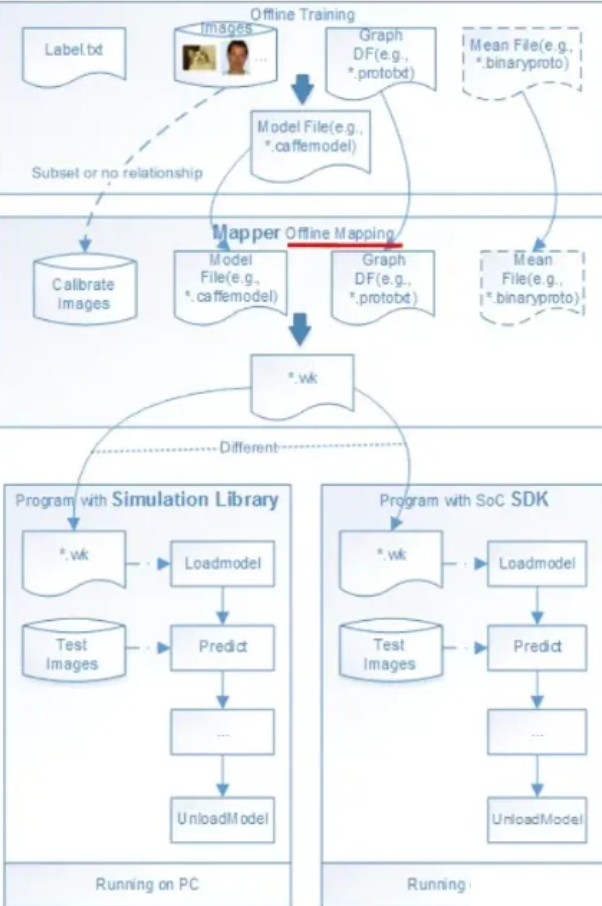
【简介】:
NNIE(Neural Network Inference Engine)工具链是华海思自研的深度学习推理框架,用于加速神经网络模型的推理过程。下面是NNIE工具链的一些名称、链接和特点。
【文档】:暂无
【特点】:高性能、多前端支持、易使用、当前已经没落
11、XLA:https://github.com/openxla/xla
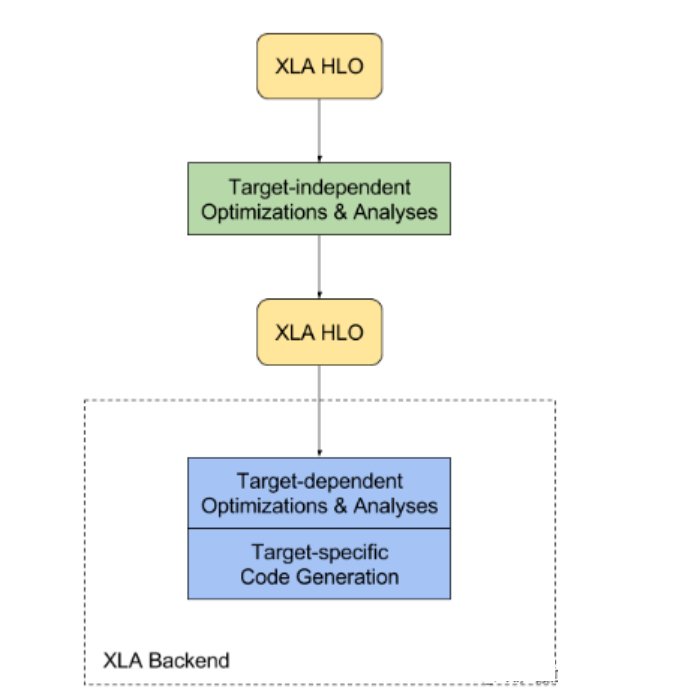
【简介】:谷歌的XLA(Accelerated Linear Algebra)是一款高性能的TensorFlow编译器,使用XLA将TensorFlow图编译成高效的、可部署的低级码,可以在多种设备上使用。
【文档】:
https://www.tensorflow.org/xla?hl=zh-cn
【特点】:
高性能、分布式、易使用、可扩展
12、ARM NN:https://github.com/ARM-software/armnn
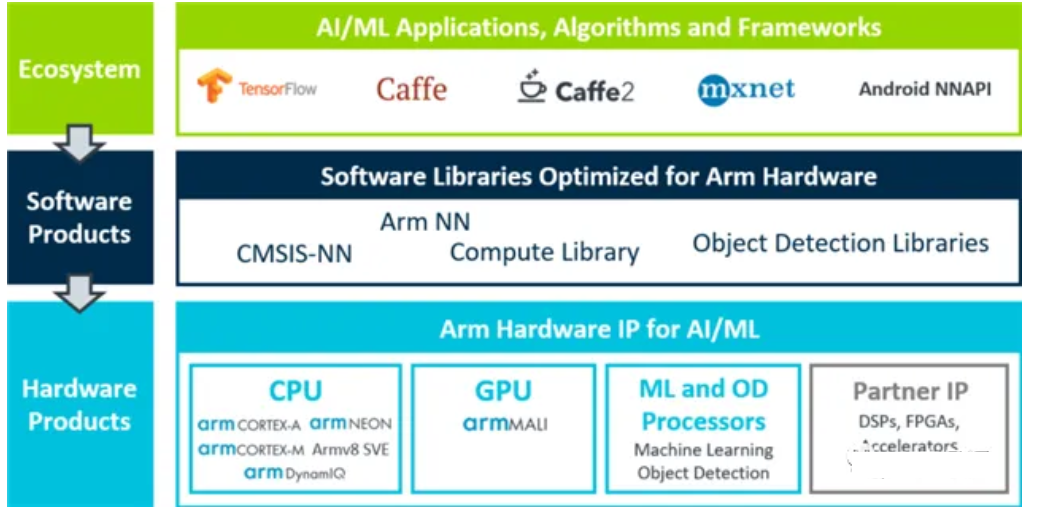
【简介】:
Arm NN 是适用于 Android 和 Linux 平台的最高性能的机器学习推理引擎,可以加速 Arm Cortex-A CPU 和 Arm Mali GPU 上的机器学习。这个推理引擎是一个开源的 SDK,可以弥合现有神经网络框架和功耗效率高的 Arm IP 之间的差距。
【文档】:
https://arm-software.github.io/armnn/20.02/
【特点】:
多前端、高性能、支持多种硬件
13、TNN:https://github.com/Tencent/TNN
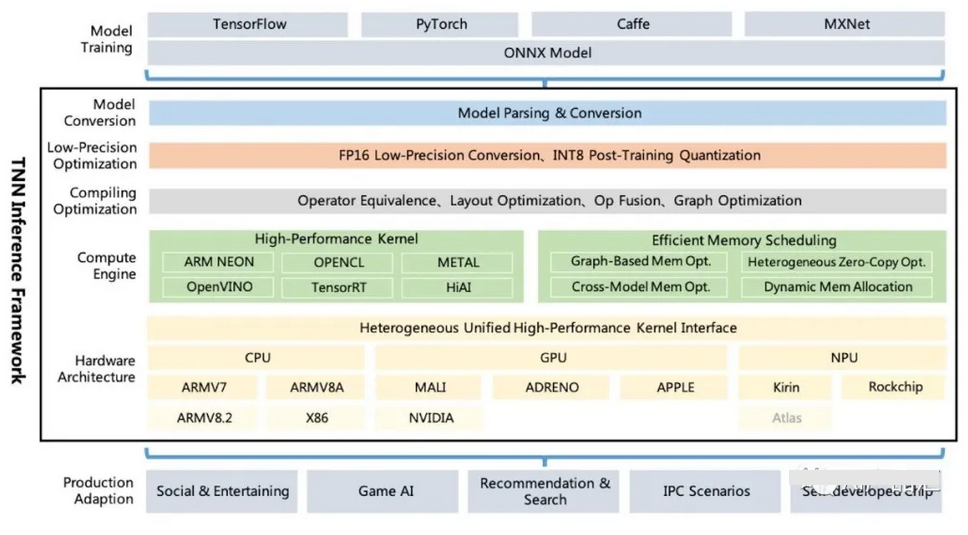
【简介】:
Tencent Youtu Lab开源的高性能、轻量级神经网络推理框架。它还具有跨平台、高性能、模型压缩和代码裁剪等诸多突出优势。TNN框架在原有Rapidnet和ncnn框架的基础上进一步加强了对移动设备的支持和性能优化。同时,它借鉴了业界主流开源框架的高性能和良好的可扩展性特点,并扩展了对X86和NV GPU的支持。在手机上,TNN已被许多应用程序使用。作为腾讯云人工智能的基本加速框架,TNN为许多业务的实施提供了加速支持。
【文档】:
https://github.com/Tencent/TNN/blob/master/doc/cn/user/api.md
【特点】:
计算优化、低精度计算加速、内存优化、易于使用、社区开源
14、NCNN:https://github.com/Tencent/ncnn
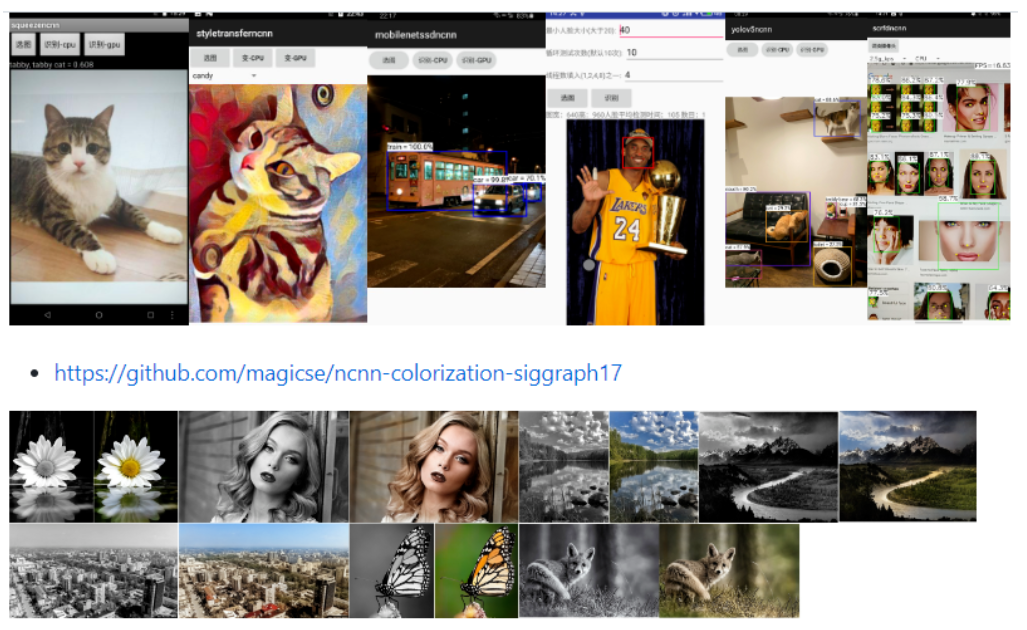
【简介】:
ncnn 是一个为手机端极致优化的高性能神经网络前向计算框架。ncnn 从设计之初深刻考虑手机端的部署和使用。无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行, 开发出人工智能 APP,将 AI 带到你的指尖。ncnn 目前已在腾讯多款应用中使用,如:QQ,Qzone,微信,天天 P 图等。
【文档】:
https://github.com/Tencent/ncnn/tree/master/docs
【特点】:
纯 C++ 实现、跨平台、支持 Android / iOS 、精细的内存管理和数据结构设计、内存占用极低、支持直接内存零拷贝
15、TVM:https://github.com/apache/tvm
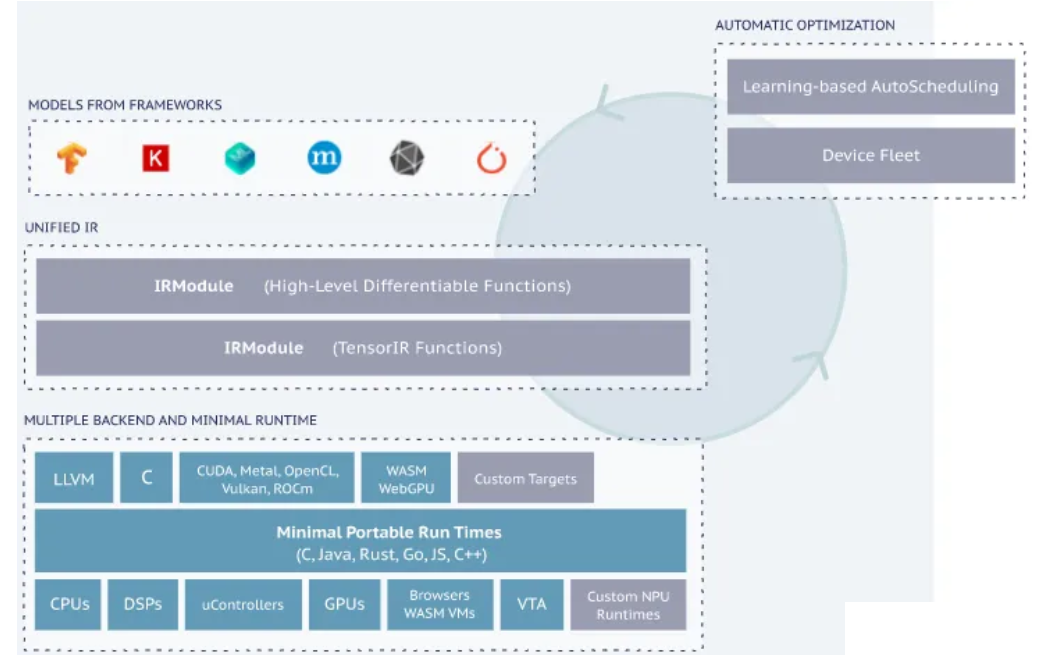
【简介】:
TVM(又称深度学习优化器)是一个开源的端到端深度学习编译器和优化器,旨在通过图优化、IR端的自动优化和Tensor级的调度优化等方法来提供高效、通用的编译解决方案,使得模型的训练和部署可以更加高效完整。
【文档】:
https://docs.tvm.ai/
【特点】:
支持多前端、支持多后端、图优化、AutoTVM、Ansor优化
16、OpenPPL:https://github.com/openppl-public/ppl.nn

【简介】:
商汤OpenPPL是商汤科技公司开源的人工智能框架,它可以帮助开发者快速实现各种深度学习任务。它可以很好的支持各种onnx模型,并提供优于OpenMMLAB的性能。
【文档】:
https://github.com/openppl-public/ppl.nn/blob/master/docs/en/lua-api-reference.md
【特点】:
灵活性、高效性、易用性和可扩展性
17、MegEngine:https://github.com/MegEngine/MegEngine
【简介】:
MegEnigne是旷视完全自主研发的深度学习框架,中文名叫“天元”,它是旷视 AI战略的重要组成部分,负责AI三要素中的算法。MegEngine的研发始于2014年,旷视内部全员使用。如今,旷视的所有算法均基于MegEngine进行训练和推理。
【文档】:
https://www.megengine.org.cn/doc/stable/zh/user-guide/index.html
【特点】:
训练推理一体化、动静图合一、兼容并包、灵活高效
学术界
1、Pytorch:https://github.com/pytorch/pytorch
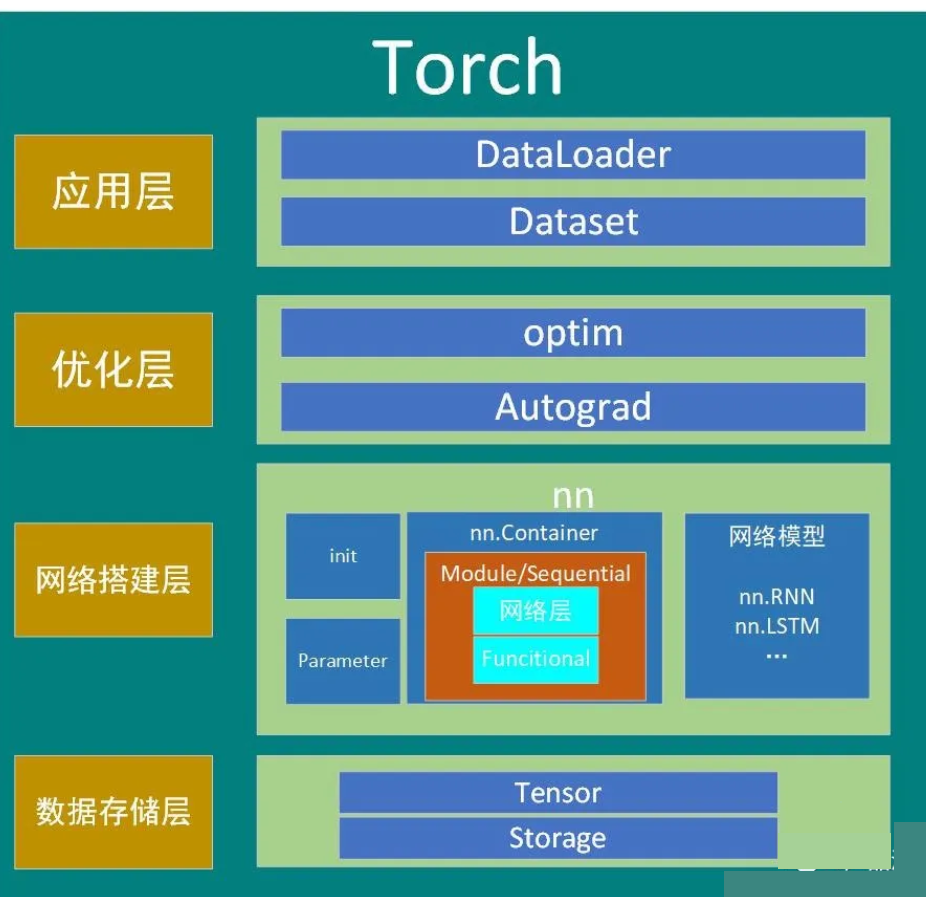
【简介】:
PyTorch是由Facebook AI研究院开发的一种基于Python的科学计算框架,它支持动态计算图技术,易于使用,对于深度学习初学者来说是一个非常好的选择。
【文档】:
https://pytorch.org/docs/stable/index.html
【特点】:
简单易用、支持动态计算图、分布式计算、丰富的工具包、社区友好
2、Tensorflow:https://github.com/tensorflow/tensorflow
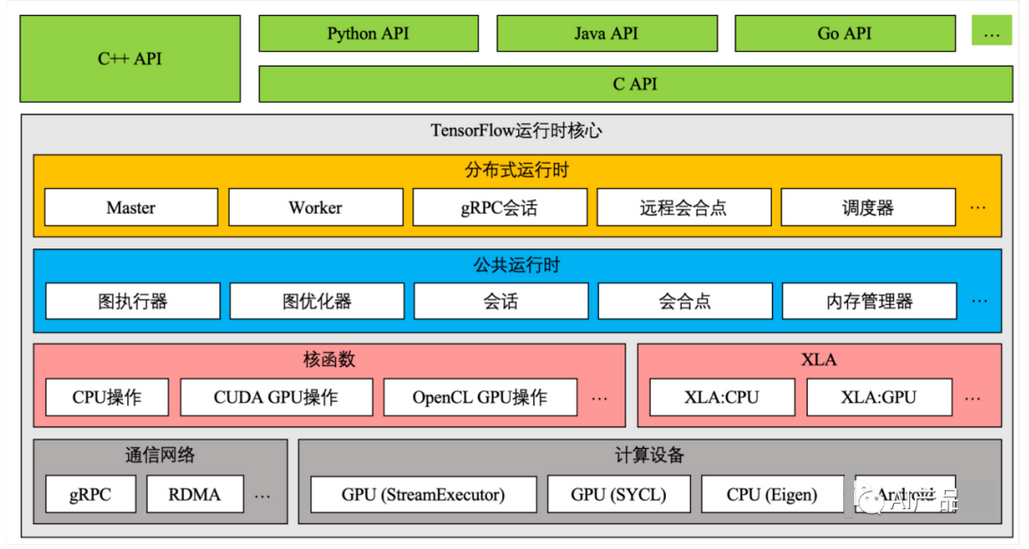
【简介】:
TensorFlow是由Google开发的开源人工智能软件库,用于实现深度神经网络。它可以运行在多种平台上,包括手机、电脑、服务器和云端。TensorFlow支持多种编程语言,包括Python、C++和Java等。
【文档】:
https://www.tensorflow.org/api_docs
【特点】:
基于数据流图的计算模型、分布式计算、代码开源、社区开放
3、ONNX:https://github.com/onnx/onnx
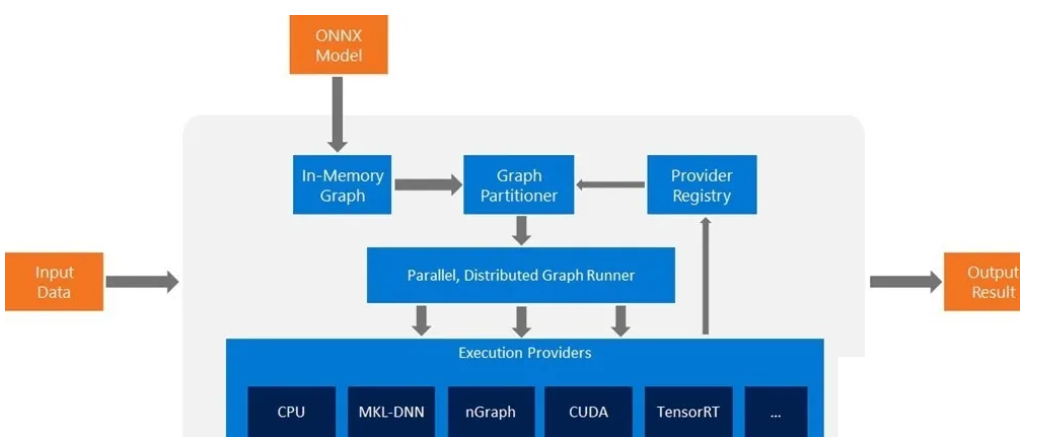
【简介】:
ONNX(Open Neural Network Exchange)是一个开放式的神经网络交换格式,是由微软和 Facebook 共同开发并推出的。它是一种跨平台、跨框架的深度学习模型交换格式,目的是提高不同深度学习框架之间的互操作性。
【文档】:
https://onnx.ai/onnx/intro/
【特点】:
跨平台、跨框架、多硬件支持、多系统支持、丰富的三方包
4、MxNet:https://github.com/apache/incubator-mxnet
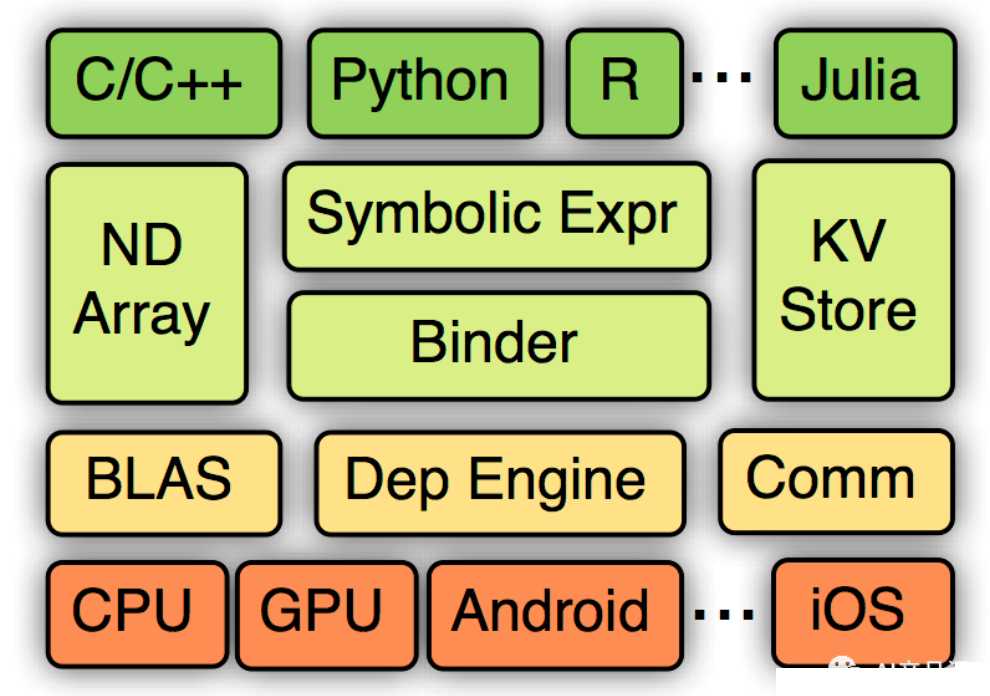
【简介】:
MXNet是一种快速,高效和可扩展的深度学习框架,用于构建与训练神经网络。它具有许多独特的功能和最新的研究成果,使其成为开发深度学习应用程序的理想选择。
【文档】:
https://mxnet.apache.org/versions/1.9.1/api
【特点】:
超低内存占用、分布式训练、支持多语言、高性能
5、PaddlePaddle:https://github.com/PaddlePaddle
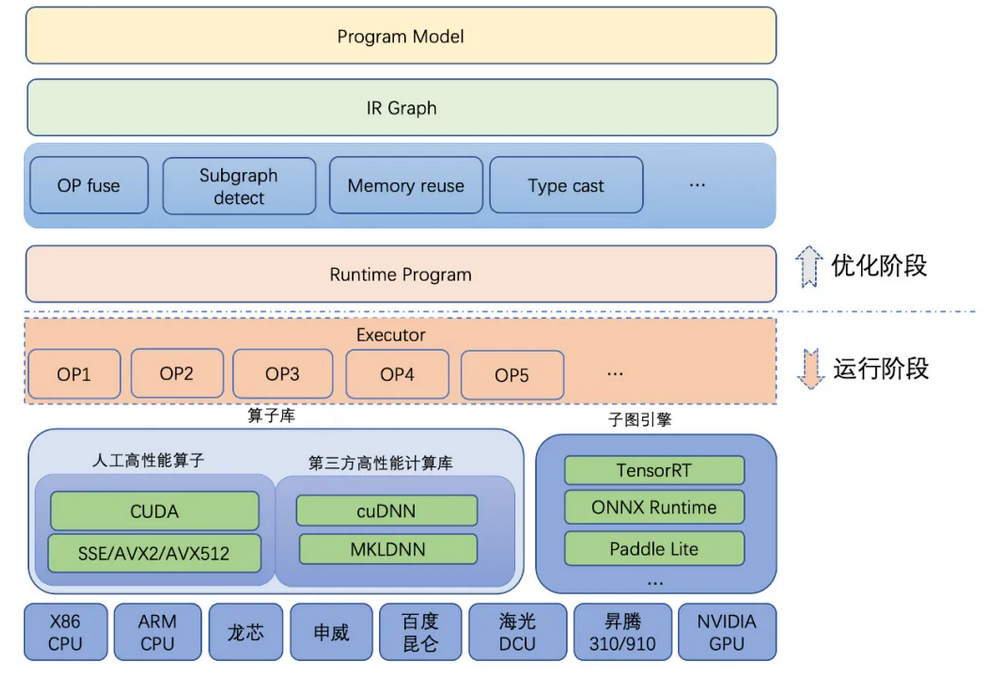
【简介】:
PaddlePaddle是中国第一个独立研发深度学习平台,自2016年以来已正式开源给专业社区。它是一个拥有先进技术和丰富特性的工业平台,涵盖了核心深度学习框架、基本模型库、端到端开发工具包、工具和组件以及服务平台等方面。
【文档】:
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/index_cn.html
【特点】:
高性能推理、分布式训练、社区开发、国产平台
6、MindSpore:https://github.com/mindspore-ai/mindspore
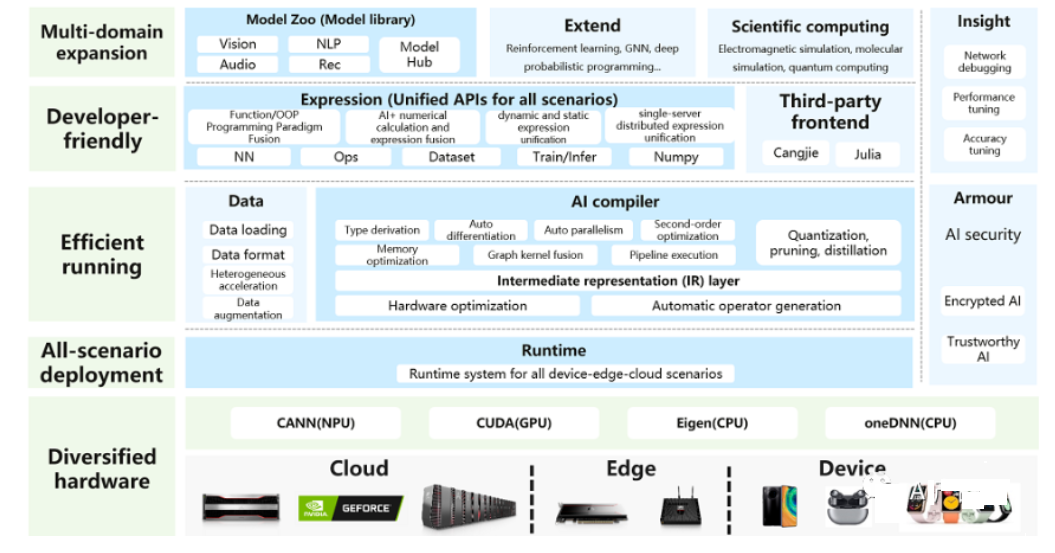
【简介】:
MindSpore是一款适用于移动、边缘和云场景的全新开源深度学习训练/推理框架。MindSpore旨在为数据科学家和算法工程师提供友好的开发体验和高效的执行,具有本地支持Ascend AI处理器和软硬件协同优化的特点。同时,作为全球AI开源社区,MindSpore的目标是进一步推进AI软硬件应用生态系统的发展和丰富。
【文档】:
https://www.mindspore.cn/docs/en/r0.7/index.html
【特点】:
自动差分、动静图结合、自动并行、社区开放
原创 Luce AI产品汇