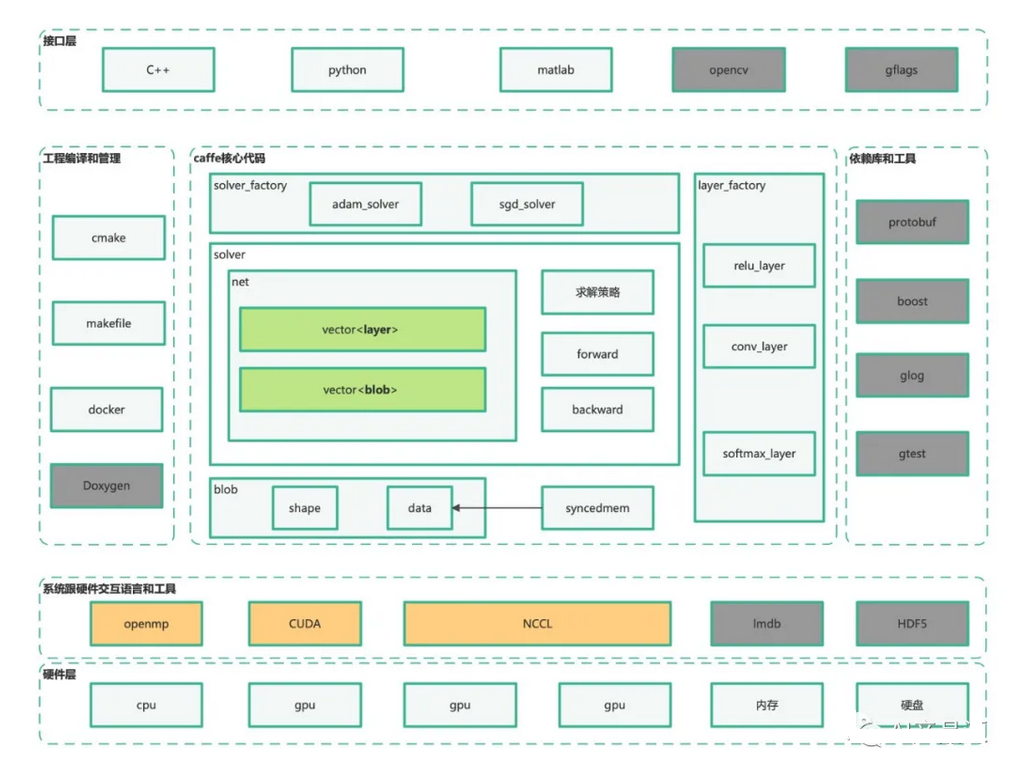
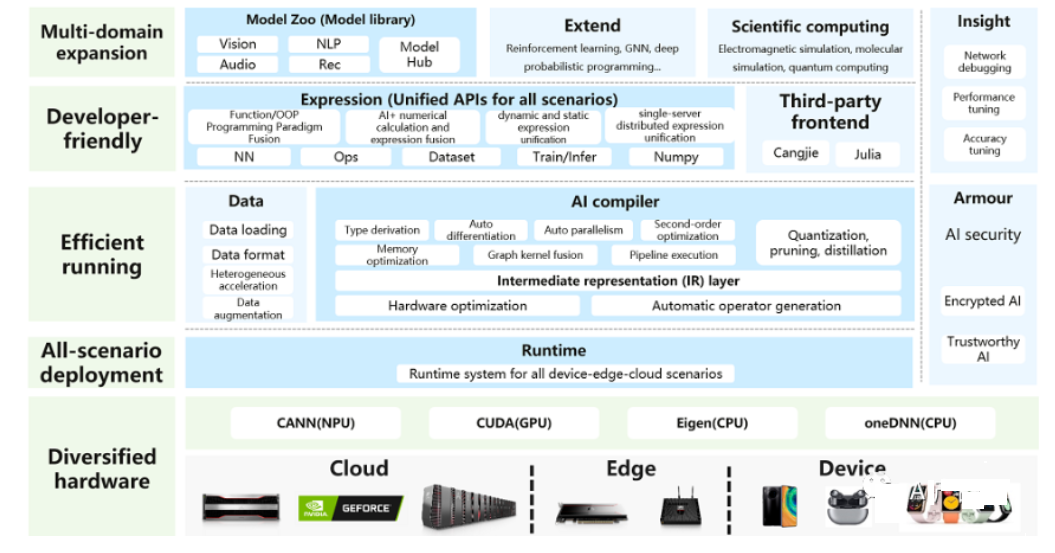
3D NAND中基于图的近似最近邻搜索的Proxima近存储加速
摘要——近似最近邻搜索(ANNS)在各种应用中起着不可或缺的作用,包括推荐系统、信息检索和语义搜索。在尖端的ANNS算法中,基于图的方法在海量数据集上提供了卓越的准确性和可扩展性。然而,性能最好的基于图的ANN搜索解决方案需要数百个内存占用以及昂贵的距离计算,从而阻碍了它们的大规模有效部署。3D NAND闪存因其高密度和非易失性而成为数据密集型应用的有前景的设备。在这项工作中,我们提出了基于近存储处理(NSP)的ANNS解决方案Proxima,在3D NAND闪存中通过算法硬件协同设计来加速基于图的ANNS。Proxima通过利用距离近似和提前终止显著降低了图搜索的复杂性。在算法增强的基础上,我们使用异构集成技术在3D NAND ffash中实现了Proxima搜索算法。为了最大限度地提高3D NAND的带宽利用率,我们提出了定制的数据流和优化的数据分配方案。我们的评估结果表明:与CPU和GPU上的图形ANNS相比,Proxima在吞吐量或能效方面有了显著提高。Proxima的速度比现有的ASIC设计提高了7倍至13倍。此外,与之前的基于NSP的加速器相比,Proxima在精度、效率和存储密度之间实现了良好的平衡。
尽管现有的基于图的ANN搜索算法在图构建过程中施加了发散的约束,但它们中的大多数都有类似的启发式搜索过程。搜索ffow是图1所示的最佳第一次遍历。当一个新的查询q到来时,搜索过程从预先定义的入口点(

)开始,贪婪地遍历图以到达q的最近邻居。维护一个候选列表L来存储(距离,id)对评估最佳的顶点,这些顶点按它们到q的距离升序排列。L具有预先定义的大小L,并以

开头。
搜索过程通过访问其邻域并计算其邻居与q之间的距离,迭代地“评估”L中第一个未评估的候选对象。这些邻居与它们的距离一起插入L中。然后对L进行排序,只保留最接近q的前L个候选。重复此搜索过程,直到L中的所有候选都已被评估。然后,返回L中的前k个候选作为q的k个最近邻的近似值。候选列表大小L可用于控制搜索精度。特别是,L越高,在搜索终止之前,图中的顶点就越多。因此,搜索返回更准确的结果。

图1 基于图的ANN搜索示意图。
NSP的异构集成。尽管NSP避免了大量数据传输,但处理元件的集成可能会占用大量空间。使用阵列下CMOS(CUA)和Cu-Cu键合的异构集成可以解决与将处理元件集成到3D NAND芯片上相关的成本和面积问题。如图2所示,CUA与阵列下的内存外设重叠,减少了单层的面积。CMOS晶片和NAND晶片可以使用不同的技术节点独立制造。在完成CMOS和NAND晶片的制造后,高密度芯片间Cu-Cu键合将CMOS晶片上的处理元件连接到3D NAND晶片,提供无缝集成。因此,具有异构集成的NSP可以为大规模数据处理提供紧凑的解决方案,提高性能。这种方法为开发用于各种应用的低功耗、高性能和紧凑型数据处理系统开辟了新的机遇。

图2 Proxima采用3D NAND和异构集成技术的近存储架构。
2.计算并比较提取的数据向量的距离。图3-(a)中的rooffine分析显示,ANNS算法的计算强度较低,属于内存受限区域。此外,图遍历因其随机内存访问行为而臭名昭著。
图3-(b)描述了基于图的ANNS的平均末级缓存(LLC)错过率。由于随机接入模式,LLC在搜索过程中的漏报率高达80%至90%,成为另一个瓶颈。
挑战2:昂贵的距离计算。为了保证高召回率,基于图的ANNS依赖于高维原始数据的精确距离计算。如图3-(b)所示,D维数据的距离计算主要消耗CPU总运行时间的50%以上。
然而,大多数距离计算都是多余的,对最终结果没有影响。因此,如何在提供令人满意的性能的同时减少距离计算是加速图ANN算法的关键。

图3:ANNS工具的图形预览结果:(a)AMD EPYC 7543 CPU上的Roofline模型。(b) HNSW的LLC误码率和距离计算开销。
A.概述
图4显示了Proxima搜索优化的总体过程。Proxima图搜索是通用的,可以应用于各种图构建算法生成的图,如HNSW、DiskANN和NSG。在查询搜索之前,Proxima ffrst中的间隙编码会压缩构建的图以减小索引大小。在查询搜索过程中,我们提出了三种策略,包括基于产品量化(PQ)距离的搜索、基于精确距离的重新排序和具有提前终止功能的动态列表,以执行准确和低复杂度的搜索。

图4 Proxima图搜索算法。
E.顶点索引的间隙编码
图ANNS算法存储NN索引和原始数据。这导致了两个问题:
1. 获取顶点索引(NN索引)会在搜索过程中产生显著的数据访问开销,如图6-(b)所示,占80%至90%。
2. 神经网络指数的大小与原始数据相当。现有算法使用统一的32-b整数来表示顶点索引。但是,不同图尺度的统一位宽是多余的,因为log2 N⌉-b足以表示大小为N的数据集的顶点索引。Proxima使用间隙编码来节省NN索引所需的空间和数据移动。图5-(a)显示了由12个元素的邻接表表示的4个索引和3个NN的示例。未压缩的32-b邻接列表消耗384-b空间。相比之下,间隙编码包括两个步骤:
首先,按升序对每行中的NN索引进行排序,然后将排序后的索引转换为除第一个索引外的前一个索引的差值。在这种情况下,比特宽度由最大差值的比特决定。因此,所需的空间减少到168-b。我们的实验表明,1M到100M数据集的图形需要20-b到26-b的间隙编码,导致至少19%到37%的图形索引数据压缩。压缩的图索引也有助于实现更快的图遍历,因为索引获取的开销减少了。

图5 (a)Proxima中的间隙编码和(b)乘积量化(PQ)距离近似。


![[2025.1.21 MySQL学习] 基本概念](https://img2024.cnblogs.com/blog/3574171/202501/3574171-20250121030322226-820748876.png)