一、背景
1.1 问题描述
不知道大家在开发过程中有没有遇到过类似的问题,明明通过JVM参数-Xmx256m设置了最大堆内存大小为256m,但是程序运行一段时间后发现占用的内存明显超过了256m,却并没有出现内存溢出等问题,那是什么东西占用了额外的内存空间呢?
通过ps查看java进程项目启动命令为:
java -jar -Xmx256m -Xms128m -XX:+UseParNewGC -XX:PretenureSizeThreshold=40960 -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m xxxxxx-RELEASE.jar
通过top命令查看资源使用情况;
[root@test2 server]# top -p 21270

VIRT:virtual memory usage虚拟内存;
- 进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等;
- 假如进程申请
100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量;
RES:resident memory usage常驻内存;
- 进程当前使用的内存大小,但不包括
swap out; - 包含其他进程的共享;
- 如果申请
100m的内存,实际使用10m,它只增长10m,与VIRT相反; - 关于库占用内存的情况,它只统计加载的库文件所占内存大小;
SHR:shared memory共享内存;
- 除了自身进程的共享内存,也包括其他进程的共享内存;
- 虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小;
- 计算某个进程所占的物理内存大小公式:
RES – SHR; swap out后,它将会降下来。
1.2 JVM内存
先复习一下JVM内存划分图,基于Java8:

其中:
(1) Java堆内存,-Xmx选项限制的就是Java堆的大小;
(2) Java堆外内存(广义上指除了堆以外的所有内存),包含了:
Native Memory:本地内存;Direct Memory:直接内存,直接内存是和java.nio.DirectByteBuffer类相关联的,常被用在第三方库,比如nio和gzip;JNI Memory:通过java JNI调用的native方法分配的内存;Metaspace:元数据区或者叫元空间,它用于存储虚拟机加载的类信息、常量、静态变量,以及编译器编译后的代码等数据,可以通过-XX:MaxMetaspaceSize限制大小;Compressed Class Space:类压缩空间,可以通过-XX:CompressedClassSpaceSize限制大小;
Code cache:代码缓存,JIT产生的汇编指令所占的空间;简言之code Cache是存放JIT生成的机器码(native code)。当然JNI(Java本地接口)的机器码也放在Code Cache里,不过JIT编译生成的native code占主要部分;Stack:JVM Stack:每个线程分配的内存大小,可使用-Xss调整,64位操作系统中默认1MB;Native Stack:作用与虚拟机栈发挥作用类似,本地方法栈是为虚拟机使用的native方法服务;
补充:大家都知道javac编译器,把java代码编译成class字节码,它和JIT编译器的区别是,javac只是前端编译(有的叫前期编译),jvm是通过执行机器码和底层交互的,这样我们编写的业务代码才能生效。所以还要把字节码class编译成与本地平台相关的机器码,这个过程就是后端编译。
Native方法相当于C/C++暴露给 Java的一个接口,Java通过调用这个接口从而调用到C/C++方法。当线程调用Java方法时,虚拟机会创建一个栈帧并压入Java虚拟机栈。然而当它调用的是native方法时,虚拟机会保持Java虚拟机栈不变,也不会向Java虚拟机栈中压入新的栈帧,虚拟机只是简单地动态连接并直接调用指定的native方法。
二、内存监控
整理了堆内内存相关的工具。建议从上往下逐一执行命令,从整体到局部,逐步排查出具体的问题。
不同的内存区域可以使用不同的命令进行排查,同时也留意合理设置对应内存区域的参数。
内存使用过高或者OOM整体排查思路:
2.1 堆内存分析
2.1.1 jstat
jstat命令可以查看堆内存各部分的使用量,以及加载类的数量。命令:
[root@test2 ~]# jstat -gc 21270S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
7424.0 7424.0 0.0 198.8 59584.0 53877.2 148656.0 136010.4 127104.0 113635.0 15488.0 13450.1 447 5.911 3 1.280 7.191
其中:
S0C:第一个Survivor区的大小(KB);S1C:第二个Survivor区的大小(KB);S0U:第一个Survivor区的使用大小(KB)S1U:第二个Survivor区的使用大小(KB);EC:Eden区的大小(KB),这里为58MB;EU:Eden区的使用大小(KB),这里为52.6MB;OC:Old区大小(KB),这里为145MB;OU:Old使用大小(KB),这里为132MB;MC:元数据大小(KB);MU:元数据使用大小(KB);CCSC:压缩类空间大小(KB);CCSU:压缩类空间使用大小(KB);YGC:年轻代垃圾回收次数;YGCT:年轻代垃圾回收消耗时间;FGC:老年代垃圾回收次数;FGCT:老年代垃圾回收消耗时间;GCT:垃圾回收消耗总时间。
2.1.2 jmap
jmap -heap打印heap的概要信息,GC使用的算法,heap(堆)的配置及JVM堆内存的使用情况。命令:
[root@test2 server]# jmap -heap 21270
Attaching to process ID 21270, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.162-b12using parallel threads in the new generation.
using thread-local object allocation.
Mark Sweep Compact GC # 使用的是parallel收集器(也叫并行收集器)即 Mark Sweep Compact GCHeap Configuration:MinHeapFreeRatio = 40MaxHeapFreeRatio = 70# 堆的最大大小 256MBMaxHeapSize = 268435456 (256.0MB) # 分别对应新生代的默认值和最大值NewSize = 44695552 (42.625MB)MaxNewSize = 89456640 (85.3125MB) # 老年代/新生代=2,最大堆为256,所以新生代最大值为即256/3# 老年代的默认值OldSize = 89522176 (85.375MB)# 新生代和老年代的大小比例,即老年代:新生代=2:1 NewRatio = 2# 新生代中的eden区与survivor的比例=8:1 SurvivorRatio = 8# 这个是元空间大小,元空间是方法区的一个实现MetaspaceSize = 67108864 (64.0MB)CompressedClassSpaceSize = 125829120 (120.0MB)# 元空间的最大值MaxMetaspaceSize = 134217728 (128.0MB)# G1区块的大小G1HeapRegionSize = 0 (0.0MB)Heap Usage:
# 先是新生代,这里是指eden加上一个survivor空间。容量有65.4M这样,使用了38。7M,还有26.7M空闲。 接近60%的使用率。
New Generation (Eden + 1 Survivor Space):capacity = 68616192 (65.4375MB)used = 40579920 (38.70002746582031MB)free = 28036272 (26.737472534179688MB)59.140443118732094% used
# 单独的eden区,大小为58.2M这样。
Eden Space: # Edencapacity = 61014016 (58.1875MB)used = 40391424 (38.520263671875MB)free = 20622592 (19.667236328125MB)66.20023831901182% used
# 这是其中的一个surivor区,是在使用着的,和上面的eden加起来就等于前面的new generation的大小了,可以试着估摸一下
From Space: # From Survivorcapacity = 7602176 (7.25MB)used = 188496 (0.1797637939453125MB)free = 7413680 (7.0702362060546875MB)2.4795006061422415% used
# 这是另一个survivor的使用情况。此时没有被使用。大小和前面的survivor大小一样
To Space: # To Survivorcapacity = 7602176 (7.25MB)used = 0 (0.0MB)free = 7602176 (7.25MB)0.0% used
# 这个tenured翻译为终身的,我的理解就是这个描述的是老年代。也就是说老年代大小为145M,使用了133M这样,92%的使用率。
tenured generation:capacity = 152223744 (145.171875MB)used = 139545008 (133.0804901123047MB)free = 12678736 (12.091384887695312MB)91.6709866234797% used49252 interned Strings occupying 5222440 bytes.
我们启动命令中设置堆初始化大小为64MB,最大256MB,结合上面查看到的信息:
- 新生代
capacity:58.1875MB+7.25MB+7.25MB = 72.6875MB,需要注意的是这个值并没有达到最大; - 新生代最大值:
85.3125MB; - 老年代
capacity:145.171875MB,同样需要注意的是这个值并没有达到最大; - 老年代最大值:
170.625MB; - 老年代/新生代
=2; - 新生代 + 老年代
capacity = 217.859375MB,我们配置的最大堆为256M,因此并未占满。
2.2 NMT追踪
NMT(Native Memory tracking)是一种Java HotSpot VM功能,可跟踪Java HotSpot VM的内部内存使用情况(jdk8+)。
2.2.1 开启
NMT功能默认关闭,可以通过以下方式开启,在启动参数中添加:
-XX:NativeMemoryTracking=detail
可以设置summary、detail来开启;开启的话,大概会增加5%-10%的性能消耗。
注意:参数需要添加到最前面,否则可能会报错Native memory tracking is not enabled。
运行进程:
java -XX:NativeMemoryTracking=detail -jar -Xmx256m -Xms128m -XX:+UseParNewGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -XX:MaxDirectMemorySize=64m xxxxxx-RELEASE.jar
其中:
Xmx256m:最大堆内存256MB;-XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m:元空间限制;-XX:MaxDirectMemorySize=64m:直接内存限制;-XX:+UseParNewGC:并行收集器。
2.2.2 查看结果
通过jcmd命令分析java进程的内存,进程刚启动时:
[root@test2 server]# jcmd 6898 VM.native_memory summary scale=MB
6898:Native Memory Tracking:Total: reserved=1689MB, committed=349MB
- Java Heap (reserved=256MB, committed=141MB)(mmap: reserved=256MB, committed=141MB)// 元数据
- Class (reserved=1103MB, committed=89MB)(classes #14716)(malloc=3MB #24905)(mmap: reserved=1100MB, committed=86MB)// 线程栈
- Thread (reserved=48MB, committed=48MB)(thread #49)(stack: reserved=48MB, committed=48MB)// 代码缓存
- Code (reserved=251MB, committed=40MB)(malloc=7MB #10434)(mmap: reserved=244MB, committed=33MB)// 垃圾回收
- GC (reserved=5MB, committed=5MB)(malloc=4MB #459)(mmap: reserved=1MB, committed=0MB)// 内部
- Internal (reserved=2MB, committed=2MB)(malloc=2MB #18761)// 符号
- Symbol (reserved=20MB, committed=20MB)(malloc=17MB #185641)(arena=3MB #1)- Native Memory Tracking (reserved=4MB, committed=4MB) # 分析工具占用(tracking overhead=4MB)[root@test2 server]# top -p 6898
top - 10:03:13 up 363 days, 16:12, 3 users, load average: 0.52, 0.62, 0.37
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.6 us, 1.6 sy, 0.0 ni, 96.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8007032 total, 290224 free, 6300700 used, 1416108 buff/cache
KiB Swap: 4063228 total, 2927380 free, 1135848 used. 1039816 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND6898 root 20 0 3908152 384340 14444 S 0.0 4.8 1:50.63 java(1) 可以看到java进程的整个memory主要包含了:
-
顶部的
Total committed,就是当前JVM所使用的大小; -
Java Heap: 堆内存,即-Xmx限制的最大堆大小的内存; -
Class:对于JDK8,其实就是Metadata,被-XX:MaxMetaspaceSize限制最大大小;在JDK10之后,Class部分的报告会多一些,包含了Metadata和Class space两部分; -
Thread:线程与线程栈占用内存,每个线程栈占用大小受-Xss限制,但是总大小没有限制; -
Code:JIT即时编译后(C1C2编译器优化)的代码占用内存,受-XX:ReservedCodeCacheSize限制; -
GC:垃圾回收占用内存,例如垃圾回收需要的CardTable,标记数,区域划分记录,还有标记GC Root等等,都需要内存。这个不受限制,一般不会很大的。Parallel GC不会占什么内存,G1最多会占堆内存10%左右额外内存,ZGC会最多会占堆内存15~20%左右额外内存,但是这些都在不断优化。(注意,不是占用堆的内存,而是大小和堆内存里面对象占用情况相关); -
Internal:命令行解析,JVMTI使用的内存,这个不受限制,一般不会很大的; -
Symbol:常量池占用的大小,字符串常量池受-XX:StringTableSize个数限制,总内存大小不受限制; -
Native Memory Tracking:内存采集本身占用的内存大小,如果没有打开采集(那就看不到这个了,哈哈),就不会占用,这个不受限制,一般不会很大的; -
Arena Chunk:所有通过arena方式分配的内存,这个不受限制,一般不会很大的; -
Tracing:所有采集占用的内存,如果开启了JFR则主要JFR占用的内存。这个不受限制,一般不会很大的;
内存可以有两种统计方式:
- 系统分配器:
malloc实现; JVM直接向操作系统申请内存,通过mmap系统调用实现;
除了Native Memory Tracking记录的内存使用,还有三种内存Native Memory Tracking没有记录,那就是:
Direct Buffer:直接内存;JNI Memory:通过JNI机制直接调用native方法分配的内存,比如malloc;MMap Buffer:底层用的操作系统的mmap,将文件或文件的一部分映射到内存中的技术,通过内存映射文件可以实现高效的文件读写操作;
(2) 结果信息中有两个值,reserved和committed,解释如下:
-
reserved:是指JVM通过mmaped PROT_NONE申请的虚拟地址空间,在页表中已经存在了记录(entries)。说白了,就是已分配的大小;在堆内存下,就是xmx值,jvm申请的最大保留内存; -
committed:是JVM向操作系统实际分配的内存(malloc/mmap),mmaped PROT_READ|PROT_WRITE,相当于程序实际申请的可用内存。在堆内存下,当xms没有扩容时就是xms值,最小堆内存,扩容后就是扩容后的值,heap committed memory。
注意,committed申请的内存并不是说直接占用了物理内存,由于操作系统的内存管理是惰性的,对于已申请的内存虽然会分配地址空间,但并不会直接占用物理内存,真正使用的时候才会映射到实际的物理内存。所以committed > res也是很可能的。
(3) 运行SDK单元测试(并发1,大概有700多条用例,可以看到700次请求调用)再次查看:
[root@test2 server]# jcmd 6898 VM.native_memory summary scale=MB
6898:Native Memory Tracking:Total: reserved=1852MB, committed=609MB
- Java Heap (reserved=256MB, committed=203MB)(mmap: reserved=256MB, committed=203MB)# 元空间,存储已被虚拟机加载的类信息 通过代码瘦身,减少class数量
- Class (reserved=1135MB, committed=125MB)(classes #19896)(malloc=5MB #47783)(mmap: reserved=1130MB, committed=120MB)# 占用过大 线程数*线程栈大小 通过设置线程栈大小,减小栈空间
- Thread (reserved=165MB, committed=165MB)(thread #165)(stack: reserved=165MB, committed=165MB)(malloc=1MB #826)# 占用过大
- Code (reserved=257MB, committed=76MB)(malloc=13MB #18117)(mmap: reserved=244MB, committed=63MB)// 垃圾回收
- GC (reserved=5MB, committed=5MB)(malloc=4MB #1050)(mmap: reserved=1MB, committed=1MB)- Internal (reserved=4MB, committed=4MB)(malloc=4MB #28743)- Symbol (reserved=23MB, committed=23MB)(malloc=20MB #214223)(arena=3MB #1)- Native Memory Tracking (reserved=5MB, committed=5MB)(tracking overhead=5MB)- Arena Chunk (reserved=2MB, committed=2MB)(malloc=2MB)[root@test2 server]# top -p 6898
top - 10:08:34 up 363 days, 16:17, 3 users, load average: 0.78, 0.73, 0.48
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 20.7 us, 1.6 sy, 0.0 ni, 77.6 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
KiB Mem : 8007032 total, 164808 free, 6534920 used, 1307304 buff/cache
KiB Swap: 4063228 total, 2927380 free, 1135848 used. 806608 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND6898 root 20 0 4045.7m 591.9m 15.6m S 81.0 7.6 4:31.84 java
稳定之后,内存占用大概在590MB的样子,这里我们的目标是期望内存占用降低到550MB以下。
2.2.3 分析问题
逐个分析堆外内存的大户:Metaspace、Thread、Code Cache、Direct Memory、JNI Memory;
前三项可以通过NMT工具监控;后两项无法通过NMT工具监控。
2.3 arthas使用
下载包:
curl -O https://arthas.aliyun.com/arthas-boot.jar
运行程序
java -jar arthas-boot.jar,选择监控进程
输入命令,开始监控:
profiler start --event itimer
停止监控:
profiler stop --format html --file /opt/data/result_itimer.html
内存监控:
memory
2.4 jstak
要减少线程数量,首先要搞明白这些线程都是由谁创建的,用在哪里。
jstak可以用来排查CPU使用率高以及线程情况:
[root@test2 server]# jstack -l 27109 > jstack.log
[root@test2 server]# more jstack.log
2023-11-07 09:01:07
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.162-b12 mixed mode):"http-nio-30998-exec-93" #273 daemon prio=5 os_prio=0 tid=0x00007f3158040000 nid=0x3819 waiting for monitor entry [0x00007f3137e81000]java.lang.Thread.State: BLOCKED (on object monitor)at com.alibaba.druid.stat.JdbcDataSourceStat.getRuningSqlList(JdbcDataSourceStat.java:381)at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1720)at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1408)at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:5059)at com.alibaba.druid.filter.stat.StatFilter.dataSource_getConnection(StatFilter.java:689)at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:5055)at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1386)at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1378)at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:99)at org.springframework.jdbc.datasource.DataSourceUtils.fetchConnection(DataSourceUtils.java:158)at org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:116)at org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:79)at org.mybatis.spring.transaction.SpringManagedTransaction.openConnection(SpringManagedTransaction.java:80)at org.mybatis.spring.transaction.SpringManagedTransaction.getConnection(SpringManagedTransaction.java:67)at org.apache.ibatis.executor.BaseExecutor.getConnection(BaseExecutor.java:336)....
"http-nio-30998-exec-92" #272 daemon prio=5 os_prio=0 tid=0x00007f3158035800 nid=0x2e46 waiting for monitor entry [0x00007f3137afb000]java.lang.Thread.State: BLOCKED (on object monitor)at com.alibaba.druid.stat.JdbcDataSourceStat.getRuningSqlList(JdbcDataSourceStat.java:381)at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1720)at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1408)at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:5059)at com.alibaba.druid.filter.stat.StatFilter.dataSource_getConnection(StatFilter.java:689)at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:5055)at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1386)at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1378)
导出线程快照,可以从线程名或线程栈中的方法名大概猜出线程的作用。
2.5 show-busy-java-threads
show-busy-java-threads用于快速排查Java的CPU性能问题(top us值过高),自动查出运行的Java进程中消耗CPU多的线程,并打印出其线程栈,从而确定导致性能问题的方法调用。
show-busy-java-threads
# 从所有运行的Java进程中找出最消耗CPU的线程(缺省5个),打印出其线程栈# 缺省会自动从所有的Java进程中找出最消耗CPU的线程,这样用更方便
# 当然你可以手动指定要分析的Java进程Id,以保证只会显示出那个你关心的那个Java进程的信息
show-busy-java-threads -p <指定的Java进程Id>show-busy-java-threads -c <要显示的线程栈数>show-busy-java-threads <重复执行的间隔秒数> [<重复执行的次数>]
# 多次执行;这2个参数的使用方式类似vmstat命令show-busy-java-threads -a <运行输出的记录到的文件>
# 记录到文件以方便回溯查看show-duplicate-java-classes -S <存储jstack输出文件的目录>
# 指定jstack输出文件的存储目录,方便记录以后续分析##############################
# 注意:
##############################
# 如果Java进程的用户 与 执行脚本的当前用户 不同,则jstack不了这个Java进程
# 为了能切换到Java进程的用户,需要加sudo来执行,即可以解决:
sudo show-busy-java-threadsshow-busy-java-threads -s <指定jstack命令的全路径>
# 对于sudo方式的运行,JAVA_HOME环境变量不能传递给root,
# 而root用户往往没有配置JAVA_HOME且不方便配置,
# 显式指定jstack命令的路径就反而显得更方便了# -m选项:执行jstack命令时加上-m选项,显示上Native的栈帧,一般应用排查不需要使用
show-busy-java-threads -m
# -F选项:执行jstack命令时加上 -F 选项(如果直接jstack无响应时,用于强制jstack),一般情况不需要使用
show-busy-java-threads -F
# -l选项:执行jstack命令时加上 -l 选项,显示上更多相关锁的信息,一般情况不需要使用
# 注意:和 -m -F 选项一起使用时,可能会大大增加jstack操作的耗时
show-busy-java-threads -l# 帮助信息
$ show-busy-java-threads -h
Usage: show-busy-java-threads [OPTION]... [delay [count]]
Find out the highest cpu consumed threads of java, and print the stack of these threads.Example:show-busy-java-threads # show busy java threads infoshow-busy-java-threads 1 # update every 1 second, (stop by eg: CTRL+C)show-busy-java-threads 3 10 # update every 3 seconds, update 10 timesOutput control:-p, --pid <java pid> find out the highest cpu consumed threads fromthe specified java process, default from all java process.-c, --count <num> set the thread count to show, default is 5.-a, --append-file <file> specifies the file to append output as log.-S, --store-dir <dir> specifies the directory for storing intermediate files, and keep files.default store intermediate files at tmp dir, and auto remove after run.use this option to keep files so as to review jstack/top/ps output later.delay the delay between updates in seconds.count the number of updates.delay/count arguments imitates the style of vmstat command.jstack control:-s, --jstack-path <path> specifies the path of jstack command.-F, --force set jstack to force a thread dump.use when jstack <pid> does not respond (process is hung).-m, --mix-native-frames set jstack to print both java and native frames (mixed mode).-l, --lock-info set jstack with long listing. Prints additional information about locks.cpu usage calculation control:-d, --top-delay specifies the delay between top samples, default is 0.5 (second).get thread cpu percentage during this delay interval.more info see top -d option. eg: -d 1 (1 second).-P, --use-ps use ps command to find busy thread(cpu usage) instead of top command,default use top command, because cpu usage of ps command is expressed asthe percentage of time spent running during the *entire lifetime*of a process, this is not ideal in general.Miscellaneous:-h, --help display this help and exit.
2.6 pmap
pmap命令是Linux上用来开进程地址空间的,执行pmap -x <pid> | sort -n -k3 > pmap-sorted.txt命令可以根据实际内存排序。
三 、堆外内存优化
3.1 垃圾回收器选择
修改并行收集器为串行收集器,只有一个线程进行垃圾回收;
java -XX:NativeMemoryTracking=detail -jar -Xmx256m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -XX:MaxDirectMemorySize=64m xxxxxx-RELEASE.jar
运行SDK单元测试(并发1)再次查看:
[root@test2 server]# jcmd 11168 VM.native_memory summary scale=MB
11168:Native Memory Tracking:Total: reserved=1845MB, committed=604MB
- Java Heap (reserved=256MB, committed=203MB)(mmap: reserved=256MB, committed=203MB)- Class (reserved=1137MB, committed=127MB)(classes #20214)(malloc=5MB #49449)(mmap: reserved=1132MB, committed=122MB)- Thread (reserved=161MB, committed=161MB)(thread #161)(stack: reserved=161MB, committed=161MB)(malloc=1MB #802)- Code (reserved=258MB, committed=79MB)(malloc=14MB #18539)(mmap: reserved=244MB, committed=65MB)// 垃圾回收,从-XX:+UseParNewGC时占用的5M降低到了-XX:+UseSerialGC时的1M
- GC (reserved=1MB, committed=1MB)(mmap: reserved=1MB, committed=1MB)- Internal (reserved=4MB, committed=4MB)(malloc=4MB #29358)- Symbol (reserved=23MB, committed=23MB)(malloc=20MB #214761)(arena=3MB #1)- Native Memory Tracking (reserved=5MB, committed=5MB)(tracking overhead=5MB)[root@test2 server]# top -p 11168
top - 10:47:42 up 363 days, 16:56, 3 users, load average: 0.16, 0.34, 0.33
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.3 us, 1.0 sy, 0.0 ni, 97.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 7819.4 total, 134.5 free, 6376.4 used, 1308.5 buff/cache
MiB Swap: 3968.0 total, 2858.8 free, 1109.2 used. 793.0 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11168 root 20 0 4036.9m 582.1m 15.5m S 3.8 7.4 4:38.87 java
可以看到垃圾回收占用内存从-XX:+UseParNewGC时占用的5M降低到了-XX:+UseSerialGC时的1M。
稳定之后,内存占用大概在582MB的样子,并没有比之前的590M少多少。
3.2 元空间内存优化
在JDK1.8之前,堆中存在着叫方法区(Method Area)的区域,位于永久代,用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据(就是说常量池在这里)。
在JDK1.8,改名为元数据空间(Metaspace),位置从堆中移动到了本地内存。但本质功能没变,都是用于存储已被虚拟机加载的类信息,常量、静态变量,还包括在类、实例、接口初始化时用到的特殊方法。
每个Java对象在Metaspace中都有一个指针,当JVM堆内存小于32G时,JVM默认会启用CompressedOops(压缩指针)优化,这个优化让对象引用占用32bit,而不是64bit。
另外,通过启用UseCompressedClassPointers这个选项,也是默认启用的,将能够把每个对象的类的指针压缩为32bit,当这个选项开启时,元数据被从Metaspace转移到另一个区域:Compressed class space(压缩类空间)。
3.2.1 分析元空间
怎么分析Metaspace的使用量呢?你可以打印classloader(类加载器)的统计信息;
[root@test2 server]# jcmd 11168 GC.class_stats
3.2.2 限制元空间内存
如何限制Metaspace 的内存使用呢?首先这里有两个选项:-XX:MaxMetaspaceSize(包含CompressedClassSpaceSize)、-XX:CompressedClassSpaceSize。
另外一个JVM选项,经常出现误解的是:-XX:MetaspaceSize,设置的既不是初始化,也不是最小化的大小,而是高水位线,当达到水位线后,GC循环被触发,所以如果你看到GC日志中有类似这样的信息:[Full GC (Metadata GC Threshold) 1032K->894K(198656K), 0.077995 secs],就要注意是达到水位线了。
Metaspace可以配置在何种比例时,进行扩容和缩容,通过配置这两个选项:-XX:MinMetaspaceFreeRatio、-XX:MaxMetaspaceFreeRatio。
建议JVM启动参数指定-XX:MaxMetaspaceSize,一般大小256M足够,因为默认值无限大,如果出现频繁加载class等情况,容易出现OOM。
这里我们测试发现设置为128m程序可以正常启动运行,如果设置为64m进程无法正常启动。
注意:这部分如果想瘦身,可以通过修改减少代码引用的class,同时将其设置为一个合理的值。
3.3 线程栈内存优化
- 用于存储线程执行过程中的局部变量、方法调用、操作数栈等;
- 栈内存由
JVM自动管理,每个线程都有一个独立的栈; - 栈内存与堆内存相互独立,它们之间不共享数据;
- 分为
JVM Stack(Java虚拟机栈)、Native Stack(本地方法栈)。
3.3.1 JVM Stack(Java虚拟机栈)
每个方法被执行时会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息. 每个方法被调用至返回的过程, 就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程(VM提供了-Xss来指定线程的最大栈空间, 该参数也直接决定了函数调用的最大深度)。这里局部变量表,就是我们定义的方法内部变量,包括8大基本类型和对象引用。
- 线程私有;
- 使用
-Xss设置每个线程栈的大小; - 如果被实现为固定大小内存,线程请求分配的栈容量超过
Java虚拟机栈允许的最大容量时,Java虚拟机将会抛出一个StackOverflowError异常; - 如果被实现为动态扩展内存大小,并且扩展的动作已经尝试过,但是目前无法申请到足够的内存去完成扩展,或者在建立新的线程时没有足够的内存去创建对应的虚拟机栈,那Java虚拟机将会抛出一个
OutOfMemoryError异常。
设置栈大小为328k;
java -XX:NativeMemoryTracking=detail -jar -Xss328k -Xmx256m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -XX:MaxDirectMemorySize=64m xxxxxx-RELEASE.jar
运行SDK单元测试(并发1)再次查看:
[root@test2 server]# jcmd 13115 VM.native_memory summary scale=MB
13115:Native Memory Tracking:Total: reserved=1745MB, committed=527MB
- Java Heap (reserved=256MB, committed=224MB)(mmap: reserved=256MB, committed=224MB)- Class (reserved=1141MB, committed=132MB)(classes #20770)(malloc=5MB #52857)(mmap: reserved=1136MB, committed=126MB)# 每个线程栈大小从之前1M降低到328k
- Thread (reserved=55MB, committed=55MB)(thread #161)(stack: reserved=55MB, committed=55MB)(malloc=1MB #802)- Code (reserved=258MB, committed=82MB)(malloc=14MB #19487)(mmap: reserved=244MB, committed=68MB)- GC (reserved=1MB, committed=1MB)(mmap: reserved=1MB, committed=1MB)- Internal (reserved=4MB, committed=4MB)(malloc=4MB #30482)- Symbol (reserved=23MB, committed=23MB)(malloc=20MB #215214)(arena=3MB #1)- Native Memory Tracking (reserved=5MB, committed=5MB)(tracking overhead=5MB)[root@test2 server]# top -p 13115
top - 11:27:48 up 363 days, 17:36, 4 users, load average: 0.23, 0.22, 0.24
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.1 us, 2.3 sy, 0.0 ni, 95.5 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
MiB Mem : 7819.4 total, 137.3 free, 6369.6 used, 1312.5 buff/cache
MiB Swap: 3968.0 total, 2858.8 free, 1109.2 used. 799.5 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13115 root 20 0 3869.0m 567.6m 15.5m S 4.7 7.3 6:48.03 java
稳定之后,内存占用大概在567MB的样子。
3.3.2 Native Stack(本地方法栈)
与虚拟机栈基本类似,区别在于虚拟机栈为虚拟机执行的java方法服务,而本地方法栈则是为Native方法服务(Native方法简单点来说就是一个java调用非java代码的接口。一个Native方法由非java语言实现),普通开发基本无需关心。
3.4 Code Cache优化
代码缓存,JIT产生的汇编指令所占的空间;简言之CodeCache是存放JIT生成的机器码(native code)。当然JNI(Java本地接口)的机器码也放在Code Cache里,不过JIT编译生成的native code占主要部分。
-
-XX:InitialCodeCacheSize设置codeCache初始大小,一般默认是48M; -
-XX:ReservedCodeCacheSize设置codeCache预留的大小,通常默认是240M;
设置Code Cache最大64MB;
java -XX:NativeMemoryTracking=detail -jar -Xss328k -Xmx256m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -XX:MaxDirectMemorySize=64m -XX:ReservedCodeCacheSize=64m xxxxxx-RELEASE.jar
运行SDK单元测试(并发1)再次查看:
[root@test2 server]# jcmd 31907 VM.native_memory summary scale=MB
31907:Native Memory Tracking:Total: reserved=1555MB, committed=472MB
- Java Heap (reserved=256MB, committed=203MB)(mmap: reserved=256MB, committed=203MB)- Class (reserved=1137MB, committed=127MB)(classes #20217)(malloc=5MB #43808)(mmap: reserved=1132MB, committed=122MB)- Thread (reserved=55MB, committed=55MB)(thread #161)(stack: reserved=55MB, committed=55MB)(malloc=1MB #802)# 内存占用减小
- Code (reserved=74MB, committed=53MB)(malloc=9MB #10811)(mmap: reserved=65MB, committed=44MB)- GC (reserved=1MB, committed=1MB)(mmap: reserved=1MB, committed=1MB)- Internal (reserved=4MB, committed=4MB)(malloc=4MB #29384)- Symbol (reserved=23MB, committed=23MB)(malloc=20MB #214790)(arena=3MB #1)- Native Memory Tracking (reserved=5MB, committed=5MB)(tracking overhead=5MB)[root@test2 server]# top -p 31907
top - 13:39:39 up 363 days, 19:48, 4 users, load average: 0.37, 0.71, 0.66
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.1 us, 1.8 sy, 0.0 ni, 95.9 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
MiB Mem : 7819.4 total, 166.5 free, 6369.1 used, 1283.8 buff/cache
MiB Swap: 3968.0 total, 2859.0 free, 1109.0 used. 800.3 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31907 root 20 0 3752.2m 559.5m 15.6m S 4.7 7.2 5:14.04 java
稳定之后,内存占用大概在560MB的样子,略微减小。
3.5 Direct Memory优化
3.5.1 介绍
Direct Memory是Java NIO框架引入的一种内存分配机制,允许在堆外分配内存以便更高效地执行I/O操作,通常用于NIO网络编程,JVM使用该内存作为缓冲区,提升I/O性能。
java的NIO库允许java程序使用直接内存。不受JVM内存回收管理,大小可以通过MaxDirectMemorySize设置,默认与-Xmx参数值一致。
创建Direct Buffer的方法:
ByteBuffer.allocateDirect()
该方法分配内存:内部用的是unsafe.allocateMemory(size)方法,但不属于Java NIO库的一部分,
且jdk官方不推荐直接使用unsafe.allocateMemory(size)方法,该方法不受-XX:MaxDirectMemorySize参数控制,容易导致内存被无节制地使用,所以推荐ByteBuffer.allocateDirect()方法分配内存。
通过-XX:MaxDirectMemorySize来指定最大的直接内存,默认值等于Xmx。所以建议指定一下MaxDirectMemorySize,Netty等框架会用到DirectMemory,且一般设置1G足够。
DirectMemory会超过MaxDirectMemorySize前,触发FULL GC(也会附带Young GC),堆内DirectByteBuffer等会对象回收时,会触发对象的clean逻辑,释放该对象关联的DirectMemory,当gc后还是不够,就会OOM。
3.5.2 查看内存占用
运行命令:
java -XX:NativeMemoryTracking=detail -jar -Xss328k -Xmx256m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -XX:MaxDirectMemorySize=64m -XX:ReservedCodeCacheSize=64m xxxxxx-RELEASE.jar
通过Arthas的memory命令查看,运行程序;
java -jar arthas-boot.jar选择监控进程
输入命令,查看内存占用:
[arthas@22488]$ memory
Memory used total max usage
heap 99M 135M 247M 40.27%
eden_space 12M 37M 68M 17.61%
survivor_space 4M 4M 8M 54.41%
tenured_gen 83M 93M 170M 48.64%
nonheap 132M 138M 312M 42.47%
code_cache 31M 31M 64M 48.72%
metaspace 90M 94M 128M 70.69%
compressed_class_space 10M 11M 120M 9.03%
direct 0K 0K - 0.00%
mapped 0K 0K - 0.00%
运行SDK单元测试(并发1),这里只运行了部分测试用例,如果执行完,监视进程会卡死,再次查看:
[arthas@18130]$ memory 使用 当前容量 最大值
Memory used total max usage
`heap 142M 218M 247M 57.57%`
eden_space 24M 60M 68M 35.83%
survivor_space 1M 7M 8M 12.62%
tenured_gen 116M 150M 170M 68.51%
`nonheap 163M 175M 312M 52.48%
code_cache 41M 43M 64M 65.27%
metaspace 108M 118M 128M 85.15%
compressed_class_space 12M 14M 120M 10.80%
direct 80K 80K - 100.00%
mapped 0K 0K - 0.00%[root@test2 server]# jcmd 22488 VM.native_memory summary scale=MB
22488:Native Memory Tracking:Total: reserved=1566MB, committed=505MB
- Java Heap (reserved=256MB, committed=226MB)(mmap: reserved=256MB, committed=226MB)- Class (reserved=1132MB, committed=123MB)(classes #19900)(malloc=4MB #38444)(mmap: reserved=1128MB, committed=118MB)- Thread (reserved=55MB, committed=55MB)(thread #159)(stack: reserved=54MB, committed=54MB)(malloc=1MB #792)- Code (reserved=74MB, committed=53MB)(malloc=9MB #12436)(mmap: reserved=65MB, committed=44MB)- GC (reserved=1MB, committed=1MB)(mmap: reserved=1MB, committed=1MB)- Internal (reserved=19MB, committed=19MB)(malloc=19MB #31512)- Symbol (reserved=24MB, committed=24MB)(malloc=21MB #224912)(arena=3MB #1)- Native Memory Tracking (reserved=5MB, committed=5MB)(tracking overhead=5MB)[root@test2 server]# top -p 22488
top - 16:49:16 up 363 days, 22:58, 3 users, load average: 0.66, 0.74, 0.60
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.2 us, 1.5 sy, 0.0 ni, 96.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 7819.4 total, 215.5 free, 6438.5 used, 1165.4 buff/cache
MiB Swap: 3968.0 total, 2859.8 free, 1108.2 used. 732.3 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22488 root 20 0 3681.4m 543.5m 15.2m S 5.9 7.0 3:45.08 java
arthas分析:
heap(堆内存,total) =eden_space + survivor_space + tenured_gen=218M;nonheap(堆外内存,total)=code_cache + metaspace + compressed_class_space + direct + mapped=175M;heap +nonheap = 218 + 175 = 393M, 这里计算的是总量,实际物理内存占用没那么大;- 所以其他堆外内存总量 = 总堆外物理内存 - (
heap +nonheap) =543 - 393=150m;
这150m包含了Thread(大概55MB)、GC(大概1MB)、Internal、JNI Memory等等。
通过arthas中可以看到direct内存占用很小,80K 因此可以适当调整-XX:MaxDirectMemorySize。
3.5.3 优化测试
设置-XX:MaxDirectMemorySize为32m;
x java -XX:NativeMemoryTracking=detail -jar -Xss328k -Xmx256m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -XX:MaxDirectMemorySize=32m -XX:ReservedCodeCacheSize=64m xxxxxx-RELEASE.jar
运行SDK单元测试(并发1)再次查看:
[root@test2 server]# jcmd 24124 VM.native_memory summary scale=MB
24124:Native Memory Tracking:Total: reserved=1555MB, committed=494MB
- Java Heap (reserved=256MB, committed=224MB)(mmap: reserved=256MB, committed=224MB)- Class (reserved=1137MB, committed=128MB)(classes #20445)(malloc=5MB #44823)(mmap: reserved=1132MB, committed=123MB)- Thread (reserved=55MB, committed=55MB)(thread #160)(stack: reserved=54MB, committed=54MB)(malloc=1MB #797)- Code (reserved=74MB, committed=53MB)(malloc=9MB #10551)(mmap: reserved=65MB, committed=45MB)- GC (reserved=1MB, committed=1MB)(mmap: reserved=1MB, committed=1MB)- Internal (reserved=4MB, committed=4MB)(malloc=4MB #29813)- Symbol (reserved=23MB, committed=23MB)(malloc=20MB #214682)(arena=3MB #1)- Native Memory Tracking (reserved=5MB, committed=5MB)(tracking overhead=5MB)[root@test2 server]# top -p 24124
top - 17:02:38 up 363 days, 23:11, 3 users, load average: 0.40, 0.68, 0.64
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.9 us, 1.3 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
GiB Mem : 7.6 total, 0.3 free, 6.2 used, 1.1 buff/cache
GiB Swap: 3.9 total, 2.8 free, 1.1 used. 0.8 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
24124 root 20 0 3749.4m 551.8m 15.6m S 4.3 7.1 5:09.41 java
稳定之后,内存占用大概在551MB的样子。
3.6 JNI Memory优化
NI (Java Native Interface) memory是指Java应用程序与本地代码交互时使用的内存。Java Native Interface (JNI) 是Java与本地(如C或C++)代码进行交互的桥梁。
使用方式:在Java中使用native关键字定义方法,并在C/C++代码中实现相关的本地方法。如:
private native int inflateBytes(long addr, byte[] b, int off, int len);
该native方法内部也会申请内存用以存储数据,这部分内存属于JNI内存的一部分。
无特定的JVM参数,但需要在本地代码中管理内存分配和释放。
注意:与-XX:MaxDirectMemorySize无关。
JNI内存分配过程:
3.7 关闭共享内存
-Xshare:off尽可能不去使用共享类的数据,运行命令:
java -XX:NativeMemoryTracking=detail -jar -Xss328k -Xmx256m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -XX:MaxDirectMemorySize=32m -XX:ReservedCodeCacheSize=64m xxxxxx-RELEASE.jar
运行SDK单元测试(并发1)后,内存占用反而上升,有600m,因此我们还是将该配置移除。
四、堆内存优化
虚拟机从操作系统那里申请来的的内存空间,是Java虚拟机所管理的内存中最大的一块,并且是所有线程共享的一块内存区域。主要用来为类实例对象和数组分配内存。
堆内内存是分配给JVM的部分内存,用来存放所有Java Class对象实例和数组,JVM GC操作的就是这部分内容。
可以通过-Xmx和-Xms来控制堆的最大可扩展大小(默认情况下-Xmx为物理内存的1/4,-Xms为物理内存的1/64)。如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
堆由新生代(Young)和老年代(Old)组成,java8字符串常量池也放在堆中了(可能是由于字符串常量池编译时不好确认大小,所以放在最大区域的堆中更合适一些)。新生代又被划分为三个区:Eden、From Survivor(简称S0)、To Survivor(简称S1区)。

4.1 分析GC情况
运行命令:
java -XX:NativeMemoryTracking=detail -jar -Xss328k -Xshare:off -Xmx256m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -XX:MaxDirectMemorySize=32m -XX:ReservedCodeCacheSize=64m xxxxxx-RELEASE.jar
4.1.1 jstat查看GC信息
运行SDK单元测试(并发1)之后,统计垃圾回收的堆信息:
[root@test2 server]# jstat -gc 27109 1000 100S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
7616.0 7616.0 0.0 3072.6 61312.0 56379.2 152868.0 101196.4 118016.0 107868.8 14336.0 12745.4 341 7.203 3 1.684 8.887
7616.0 7616.0 2787.2 0.0 61312.0 31366.2 152868.0 101578.5 118272.0 108052.8 14336.0 12748.2 342 7.230 3 1.684 8.914
7616.0 7616.0 0.0 2205.3 61312.0 4856.0 152868.0 102158.9 118272.0 108076.4 14336.0 12748.2 343 7.258 3 1.684 8.943
7616.0 7616.0 0.0 2205.3 61312.0 40369.6 152868.0 102158.9 118272.0 108076.4 14336.0 12748.2 343 7.258 3 1.684 8.943
7616.0 7616.0 1696.0 0.0 61312.0 12141.7 152868.0 102683.9 118272.0 108103.1 14336.0 12748.7 344 7.288 3 1.684 8.972
7616.0 7616.0 1696.0 0.0 61312.0 25919.2 152868.0 102683.9 118272.0 108103.1 14336.0 12748.7 344 7.288 3 1.684 8.972
7616.0 7616.0 1696.0 0.0 61312.0 55010.9 152868.0 102683.9 118272.0 108103.1 14336.0 12748.7 344 7.288 3 1.684 8.972
7616.0 7616.0 0.0 1478.2 61312.0 18235.6 152868.0 102970.5 118272.0 108145.7 14336.0 12749.3 345 7.314 3 1.684 8.998
7616.0 7616.0 0.0 1478.2 61312.0 54465.8 152868.0 102970.5 118272.0 108145.7 14336.0 12749.3 345 7.314 3 1.684 8.998
7616.0 7616.0 1347.9 0.0 61312.0 19046.3 152868.0 103151.3 118272.0 108153.7 14336.0 12749.3 346 7.336 3 1.684 9.020
7616.0 7616.0 1347.9 0.0 61312.0 53490.1 152868.0 103151.3 118272.0 108153.7 14336.0 12749.3 346 7.336 3 1.684 9.020
7616.0 7616.0 0.0 1264.5 61312.0 11232.9 152868.0 103357.2 118656.0 108230.5 14464.0 12762.1 347 7.367 3 1.684 9.052
7616.0 7616.0 0.0 1264.5 61312.0 37075.8 152868.0 103357.2 118656.0 108230.5 14464.0 12762.1 347 7.367 3 1.684 9.052
7616.0 7616.0 1190.5 0.0 61312.0 9846.7 152868.0 103527.9 118656.0 108260.6 14464.0 12765.3 348 7.387 3 1.684 9.071
其中:
EC:Eden区的大小,大概为60m;EU:Eden区的使用大小,上升,一直到占满Eden区,空间不足将会进行YGC;如此重复;OC:老年代大小,大概为150m;OU:老年代使用大小,大概为115m;如果空间不足,将会触发FGC;MC:元空间大小,大概为115m;MU:元空间使用大小,大概为105m;如果空间不足,将会触发FGC;FGC:为3;YGC:持续上升;
FGC和YGC会带来一下问题:
GC耗时太长、GC次数太多会影响进程的性能,导致进程响应变慢,或者无法响应;FGC正常次数:越少越好。比较正常情况几个小时一次、或者几天才一次;FGC耗时:耗时很长会导致线程频繁被停止,使应用响应变慢,比较卡顿;YGC耗时:耗时在几十或者几百毫秒属于正常情况,用户几乎无感知,对程序影响比较少。耗时太长或者频繁,会导致服务器超时问题;YGC次数:太频繁,会降低服务的整体性能。高并发服务时,影响会比较大;JVM内存设置越大,FGC耗时越长,并非越大越好。一般JVM配置]的内存越想,FGC时间越短,1G>2G>3G。
FGC/YGC常见原因:
- 大对象:系统一次性加载了过多数据到内存中(比如
SQL查询未做分页),导致大对象进入了新生代/老年代; - 内存泄漏:频繁创建了大量对象,但是无法被回收(比如
IO对象使用完后未调用close方法释放资源),先引发FGC,最后导致OOM; - 程序频繁生成一些长生命周期的对象,当这些对象的存活年龄超过分代年龄时便会进入老年代,最后引发
FGC; - 程序
BUG导致动态生成了很多新类,使得Metaspace不断被占用,先引发FGC,最后导致OOM; JVM参数设置问题:包括总内存大小、新生代和老年代的大小、Eden区和S区的大小、元空间大小、垃圾回收算法等等;
4.1.2 jmap查看大对象
jmap -histo可以查看Java堆中各个类的实例数量、内存占用大小等信息,可用于查找内存泄漏等问题。
查看堆内存中的存活对象,并按空间排序:
[root@test2 server]# jmap -histo 27109 | head -n20num #instances #bytes class name
----------------------------------------------1: 391200 31296000 com.alibaba.csp.sentinel.node.metric.MetricNode # 31MB2: 213029 20542832 [C # 20MB3: 119474 11988272 [Ljava.lang.Object; # 11MB 4: 14981 10411704 [B # 10MB 5: 23935 9723200 [I6: 106841 9402008 java.lang.reflect.Method7: 211831 5083944 java.lang.String8: 113795 4551800 java.util.LinkedHashMap$Entry9: 134070 4290240 java.util.concurrent.ConcurrentHashMap$Node10: 37939 3117600 [Ljava.util.HashMap$Node;11: 81318 2602176 java.util.HashMap$Node12: 21628 2403128 java.lang.Class13: 67043 2145376 com.alibaba.csp.sentinel.slots.statistic.base.LongAdder14: 43936 2108928 org.aspectj.weaver.reflect.ShadowMatchImpl15: 76102 1826448 java.util.ArrayList16: 78596 1698400 [Ljava.lang.Class;17: 27665 1549240 java.util.LinkedHashMap
其中实例最多的类是MetricNode,占用31MB。
4.2 打开GC日志
打印GC日志第一步,就是开启打印GC参数,也就是最基本的参数:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps
每次发生GC后查看下堆前后的内存情况,更直观:
-XX:+PrintHeapAtGC
打印safepoint信息:进入STW阶段之前,需要要找到一个合适的safepoint ,这个指标一样很重要(非必选,出现GC问题时最好加上此参数调试)
-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1
上面只是定义了打印的内容,默认情况下,这些日志会输出到控制台(标准输出)。那如果你的程序日志也输出到控制台呢,这个日志内容就会很乱,分析起来很麻烦。如果你是追加的方式(比如tomcat的catalina.out就是追加),这个文件会越来越大,分析起来就要命了。
所以需要一种分割日志的机制,这个机制嘛……JVM自然是提供的。
# GC日志输出的文件路径
-Xloggc:/path/to/gc-%t.log
# 开启日志文件分割
-XX:+UseGCLogFileRotation
# 最多分割几个文件,超过之后从头开始写
-XX:NumberOfGCLogFiles=14
# 每个文件上限大小,超过就触发分割
-XX:GCLogFileSize=100M
最终进程启动命令:
java -XX:NativeMemoryTracking=detail -jar -Xss328k -Xmx256m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -XX:MaxDirectMemorySize=32m -XX:ReservedCodeCacheSize=64m -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:/opt/data/gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=14 -XX:GCLogFileSize=100M xxxxxx-RELEASE.jar
4.2.1 Metadata FGC
运行SDK单元测试(并发1)、然后再运行接口测试,然后进程运行一段时间。
查看GC日志:
[root@test2 data]# tail -f gc-2023-11-07_11-04-38.log.0.current
......
{Heap before GC invocations=299 (full 2):def new generation total 43520K, used 41795K [0x00000000f0000000, 0x00000000f2f30000, 0x00000000f5550000)eden space 38720K, 100% used [0x00000000f0000000, 0x00000000f25d0000, 0x00000000f25d0000)from space 4800K, 64% used [0x00000000f2a80000, 0x00000000f2d80f30, 0x00000000f2f30000)to space 4800K, 0% used [0x00000000f25d0000, 0x00000000f25d0000, 0x00000000f2a80000)tenured generation total 96592K, used 95495K [0x00000000f5550000, 0x00000000fb3a4000, 0x0000000100000000)the space 96592K, 98% used [0x00000000f5550000, 0x00000000fb291c18, 0x00000000fb291e00, 0x00000000fb3a4000)Metaspace used 97979K, capacity 103320K, committed 103552K, reserved 1140736Kclass space used 11476K, capacity 12322K, committed 12416K, reserved 1048576K2023-11-07T11:10:59.464+0800: 381.382: [GC (Allocation Failure) 2023-11-07T11:10:59.464+0800: 381.382: [DefNew: 41795K->1793K(43520K), 0.0311857 secs]2023-11-07T11:10:59.495+0800: 381.413: [Tenured: 96811K->81141K(96976K), 0.7669372 secs] 137290K->81141K(140496K), [Metaspace: 97979K->97979K(1140736K)], 0.8007792 secs] [Times: user=1.58 sys=0.00, real=0.80 secs]Heap after GC invocations=300 (full 3):def new generation total 60992K, used 0K [0x00000000f0000000, 0x00000000f4220000, 0x00000000f5550000)eden space 54272K, 0% used [0x00000000f0000000, 0x00000000f0000000, 0x00000000f3500000)from space 6720K, 0% used [0x00000000f3500000, 0x00000000f3500000, 0x00000000f3b90000)to space 6720K, 0% used [0x00000000f3b90000, 0x00000000f3b90000, 0x00000000f4220000)tenured generation total 135240K, used 81141K [0x00000000f5550000, 0x00000000fd962000, 0x0000000100000000)the space 135240K, 59% used [0x00000000f5550000, 0x00000000fa48d680, 0x00000000fa48d800, 0x00000000fd962000)Metaspace used 97052K, capacity 101838K, committed 103552K, reserved 1140736Kclass space used 11336K, capacity 12070K, committed 12416K, reserved 1048576K
}{Heap before GC invocations=300 (full 3):def new generation total 60992K, used 54272K [0x00000000f0000000, 0x00000000f4220000, 0x00000000f5550000)eden space 54272K, 100% used [0x00000000f0000000, 0x00000000f3500000, 0x00000000f3500000)from space 6720K, 0% used [0x00000000f3500000, 0x00000000f3500000, 0x00000000f3b90000)to space 6720K, 0% used [0x00000000f3b90000, 0x00000000f3b90000, 0x00000000f4220000)tenured generation total 135240K, used 81141K [0x00000000f5550000, 0x00000000fd962000, 0x0000000100000000)the space 135240K, 59% used [0x00000000f5550000, 0x00000000fa48d680, 0x00000000fa48d800, 0x00000000fd962000)Metaspace used 97481K, capacity 102414K, committed 103808K, reserved 1140736Kclass space used 11378K, capacity 12130K, committed 12416K, reserved 1048576K2023-11-07T11:11:02.088+0800: 384.007: [GC (Allocation Failure) 2023-11-07T11:11:02.089+0800: 384.007: [DefNew: 54272K->681K(60992K), 0.0266521 secs] 135413K->81823K(196232K), 0.0272026 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]Heap after GC invocations=301 (full 3):def new generation total 60992K, used 681K [0x00000000f0000000, 0x00000000f4220000, 0x00000000f5550000)eden space 54272K, 0% used [0x00000000f0000000, 0x00000000f0000000, 0x00000000f3500000)from space 6720K, 10% used [0x00000000f3b90000, 0x00000000f3c3a688, 0x00000000f4220000)to space 6720K, 0% used [0x00000000f3500000, 0x00000000f3500000, 0x00000000f3b90000)tenured generation total 135240K, used 81141K [0x00000000f5550000, 0x00000000fd962000, 0x0000000100000000)the space 135240K, 59% used [0x00000000f5550000, 0x00000000fa48d680, 0x00000000fa48d800, 0x00000000fd962000)Metaspace used 97481K, capacity 102414K, committed 103808K, reserved 1140736Kclass space used 11378K, capacity 12130K, committed 12416K, reserved 1048576K
}......{Heap before GC invocations=620 (full 12):def new generation total 72448K, used 2K [0x00000000f0000000, 0x00000000f4e90000, 0x00000000f5550000)eden space 64448K, 0% used [0x00000000f0000000, 0x00000000f0000820, 0x00000000f3ef0000)from space 8000K, 0% used [0x00000000f3ef0000, 0x00000000f3ef0000, 0x00000000f46c0000)to space 8000K, 0% used [0x00000000f46c0000, 0x00000000f46c0000, 0x00000000f4e90000)tenured generation total 160200K, used 93459K [0x00000000f5550000, 0x00000000ff1c2000, 0x0000000100000000)the space 160200K, 58% used [0x00000000f5550000, 0x00000000fb094e10, 0x00000000fb095000, 0x00000000ff1c2000)Metaspace used 113578K, capacity 127369K, committed 131072K, reserved 1165312Kclass space used 13521K, capacity 15432K, committed 16128K, reserved 1048576K# Metadata空间不能满足分配时触发,这个阶段不会清理软引用;
2023-11-07T12:06:25.538+0800: 3707.456: [Full GC (Metadata GC Threshold) 2023-11-07T12:06:25.538+0800: 3707.456: [Tenured: 93459K->93459K(160200K), 0.6515715 secs] 93461K->93459K(232648K), [Metaspace: 113578K->113578K(1165312K)], 0.6518179 secs] [Times: user=0.65 sys=0.00, real=0.66 secs]Heap after GC invocations=621 (full 13):def new generation total 72448K, used 0K [0x00000000f0000000, 0x00000000f4e90000, 0x00000000f5550000)eden space 64448K, 0% used [0x00000000f0000000, 0x00000000f0000000, 0x00000000f3ef0000)from space 8000K, 0% used [0x00000000f3ef0000, 0x00000000f3ef0000, 0x00000000f46c0000)to space 8000K, 0% used [0x00000000f46c0000, 0x00000000f46c0000, 0x00000000f4e90000)tenured generation total 160200K, used 93459K [0x00000000f5550000, 0x00000000ff1c2000, 0x0000000100000000)the space 160200K, 58% used [0x00000000f5550000, 0x00000000fb094e30, 0x00000000fb095000, 0x00000000ff1c2000)Metaspace used 113578K, capacity 127369K, committed 131072K, reserved 1165312Kclass space used 13521K, capacity 15432K, committed 16128K, reserved 1048576K
}{Heap before GC invocations=621 (full 13):def new generation total 72448K, used 0K [0x00000000f0000000, 0x00000000f4e90000, 0x00000000f5550000)eden space 64448K, 0% used [0x00000000f0000000, 0x00000000f0000000, 0x00000000f3ef0000)from space 8000K, 0% used [0x00000000f3ef0000, 0x00000000f3ef0000, 0x00000000f46c0000)to space 8000K, 0% used [0x00000000f46c0000, 0x00000000f46c0000, 0x00000000f4e90000)tenured generation total 160200K, used 93459K [0x00000000f5550000, 0x00000000ff1c2000, 0x0000000100000000)the space 160200K, 58% used [0x00000000f5550000, 0x00000000fb094e30, 0x00000000fb095000, 0x00000000ff1c2000)Metaspace used 113578K, capacity 127369K, committed 131072K, reserved 1165312Kclass space used 13521K, capacity 15432K, committed 16128K, reserved 1048576K# 经过Metadata GC Threshold触发的full gc后还是不能满足条件,这个时候会触发再一次的gc cause为Last ditch collection的full gc,这次full gc会清理掉软引用
2023-11-07T12:06:26.190+0800: 3708.108: [Full GC (Last ditch collection) 2023-11-07T12:06:26.190+0800: 3708.108: [Tenured: 93459K->93459K(160200K), 0.7257697 secs] 93459K->93459K(232648K), [Metaspace: 113578K->113578K(1165312K)], 0.7260672 secs] [Times: user=0.72 sys=0.00, real=0.72 secs]
Heap after GC invocations=622 (full 14):def new generation total 72448K, used 0K [0x00000000f0000000, 0x00000000f4e90000, 0x00000000f5550000)eden space 64448K, 0% used [0x00000000f0000000, 0x00000000f0000000, 0x00000000f3ef0000)from space 8000K, 0% used [0x00000000f3ef0000, 0x00000000f3ef0000, 0x00000000f46c0000)to space 8000K, 0% used [0x00000000f46c0000, 0x00000000f46c0000, 0x00000000f4e90000)tenured generation total 160200K, used 93459K [0x00000000f5550000, 0x00000000ff1c2000, 0x0000000100000000)the space 160200K, 58% used [0x00000000f5550000, 0x00000000fb094e30, 0x00000000fb095000, 0x00000000ff1c2000)Metaspace used 113578K, capacity 127369K, committed 131072K, reserved 1165312Kclass space used 13521K, capacity 15432K, committed 16128K, reserved 1048576K
}
以如下内容为例,进行解析:
# 表示的是发生GC的原因Allocation Failure
2023-11-07T11:10:59.464+0800: 381.382: [GC (Allocation Failure) # 表示GC发生的区域在新生代,GC前该区域(DefNew)已使用容量->GC后该区域已使用容量(该内存区域总容量) 该内存区域(DefNew)GC所占用的时间
2023-11-07T11:10:59.464+0800: 381.382: [DefNew: 41795K->1793K(43520K), 0.0311857 secs] # 表示GC发生的区域在老年区,GC前该区域(Tenured)已使用容量->GC后该区域已使用容量(该内存区域总容量),紧接着又发生了一次元空间GC
2023-11-07T11:10:59.495+0800: 381.413: [Tenured: 96811K->81141K(96976K), 0.7669372 secs] 137290K->81141K(140496K), [Metaspace: 97979K->97979K(1140736K)], 0.8007792 secs] [Times: user=1.58 sys=0.00, real=0.80 secs]# Metadata空间不能满足分配时触发,这个阶段不会清理软引用;
2023-11-07T12:06:25.538+0800: 3707.456: [Full GC (Metadata GC Threshold) 2023-11-07T12:06:25.538+0800: 3707.456: [Tenured: 93459K->93459K(160200K), 0.6515715 secs] 93461K->93459K(232648K), [Metaspace: 113578K->113578K(1165312K)], 0.6518179 secs] [Times: user=0.65 sys=0.00, real=0.66 secs]# 经过Metadata GC Threshold触发的full gc后还是不能满足条件,这个时候会触发再一次的gc cause为Last ditch collection的full gc,这次full gc会清理掉软引用
2023-11-07T12:06:26.190+0800: 3708.108: [Full GC (Last ditch collection) 2023-11-07T12:06:26.190+0800: 3708.108: [Tenured: 93459K->93459K(160200K), 0.7257697 secs] 93459K->93459K(232648K), [Metaspace: 113578K->113578K(1165312K)], 0.7260672 secs]
通过夜莺工具查看FGC:

发现进程在12点左右开始一直FGC,我们过滤FGC日志文件:
[root@test2 data]# grep "Full GC" gc-2023-11-07_11-04-38.log.0.current -nR
.....
120773:2023-11-07T13:23:20.530+0800: 8322.448: [Full GC (Last ditch collection) 2023-11-07T13:23:20.530+0800: 8322.448: [Tenured: 93377K->93373K(160200K), 0.6633689 secs] 93377K->93373K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.6636420 secs] [Times: user=0.66 sys=0.00, real=0.66 secs]
120793:2023-11-07T13:23:21.202+0800: 8323.121: [Full GC (Metadata GC Threshold) 2023-11-07T13:23:21.202+0800: 8323.121: [Tenured: 93373K->93376K(160200K), 0.6627200 secs] 95900K->93376K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.6631133 secs] [Times: user=0.67 sys=0.00, real=0.66 secs]
120813:2023-11-07T13:23:21.866+0800: 8323.784: [Full GC (Last ditch collection) 2023-11-07T13:23:21.866+0800: 8323.784: [Tenured: 93376K->93376K(160200K), 0.7250454 secs] 93376K->93376K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.7253098 secs] [Times: user=0.71 sys=0.00, real=0.73 secs]
120833:2023-11-07T13:23:22.592+0800: 8324.510: [Full GC (Metadata GC Threshold) 2023-11-07T13:23:22.592+0800: 8324.510: [Tenured: 93376K->93376K(160200K), 0.7186618 secs] 93378K->93376K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.7189358 secs] [Times: user=0.71 sys=0.00, real=0.72 secs]
120853:2023-11-07T13:23:23.311+0800: 8325.229: [Full GC (Last ditch collection) 2023-11-07T13:23:23.311+0800: 8325.229: [Tenured: 93376K->93372K(160200K), 0.8038098 secs] 93376K->93372K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.8040762 secs] [Times: user=0.80 sys=0.00, real=0.80 secs]
120953:2023-11-07T13:27:14.127+0800: 8556.046: [Full GC (Metadata GC Threshold) 2023-11-07T13:27:14.127+0800: 8556.046: [Tenured: 93372K->93374K(160200K), 0.7745977 secs] 117739K->93374K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.7749777 secs] [Times: user=0.76 sys=0.00, real=0.78 secs]
120973:2023-11-07T13:27:14.902+0800: 8556.821: [Full GC (Last ditch collection) 2023-11-07T13:27:14.903+0800: 8556.821: [Tenured: 93374K->93374K(160200K), 0.6193658 secs] 93374K->93374K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.6195913 secs] [Times: user=0.62 sys=0.00, real=0.62 secs]
120993:2023-11-07T13:27:15.523+0800: 8557.441: [Full GC (Metadata GC Threshold) 2023-11-07T13:27:15.523+0800: 8557.442: [Tenured: 93374K->93375K(160200K), 0.6492947 secs] 94628K->93375K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.6495084 secs] [Times: user=0.64 sys=0.00, real=0.65 secs]
121013:2023-11-07T13:27:16.173+0800: 8558.091: [Full GC (Last ditch collection) 2023-11-07T13:27:16.173+0800: 8558.091: [Tenured: 93375K->93371K(160200K), 0.5554500 secs] 93375K->93371K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.5556849 secs] [Times: user=0.56 sys=0.00, real=0.56 secs]
121033:2023-11-07T13:27:16.730+0800: 8558.648: [Full GC (Metadata GC Threshold) 2023-11-07T13:27:16.730+0800: 8558.648: [Tenured: 93371K->93371K(160200K), 0.6549924 secs] 93373K->93371K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.6553189 secs] [Times: user=0.65 sys=0.00, real=0.65 secs]
121053:2023-11-07T13:27:17.385+0800: 8559.304: [Full GC (Last ditch collection) 2023-11-07T13:27:17.385+0800: 8559.304: [Tenured: 93371K->93371K(160200K), 0.6061750 secs] 93371K->93371K(232648K), [Metaspace: 113692K->113692K(1165312K)], 0.6064198 secs] [Times: user=0.61 sys=0.00, real=0.61 secs]
这里比较奇怪的是Metadata引起的FGC,并没有导致OOM。
注意:这部分如果想瘦身,只能通过修改减少代码引用的class,同时将其设置为一个合理的值。
4.2.2 调整XX:MaxMetaspaceSize
这里我们尝试将-XX:MaxMetaspaceSize设置为256MB,再次运行程序;
java -XX:NativeMemoryTracking=detail -jar -Xss328k -Xmx256m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=256m -XX:MaxDirectMemorySize=32m -XX:ReservedCodeCacheSize=64m -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:/opt/data/gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=14 -XX:GCLogFileSize=100M xxxxxx-RELEASE.jar
运行SDK单元测试(并发1)、然后再运行接口测试,然后进程运行一段时间;
[root@test2 ~]# jcmd 9752 VM.native_memory summary scale=MB
9752:Native Memory Tracking:Total: reserved=1556MB, committed=495MB
- Java Heap (reserved=256MB, committed=224MB)(mmap: reserved=256MB, committed=224MB)# metaspace
- Class (reserved=1139MB, committed=130MB)(classes #20698)(malloc=5MB #43534)(mmap: reserved=1134MB, committed=125MB)# 已经优化
- Thread (reserved=55MB, committed=55MB)(thread #161)(stack: reserved=55MB, committed=55MB)(malloc=1MB #802)# 已经优化
- Code (reserved=72MB, committed=51MB)(malloc=7MB #7869)(mmap: reserved=65MB, committed=44MB)- GC (reserved=1MB, committed=1MB)(mmap: reserved=1MB, committed=1MB)- Internal (reserved=5MB, committed=5MB)(malloc=4MB #30580)- Symbol (reserved=23MB, committed=23MB)(malloc=20MB #215338)(arena=3MB #1)- Native Memory Tracking (reserved=5MB, committed=5MB)(tracking overhead=5MB)[root@test2 ~]# jstat -gc 9752 1000 100S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
7616.0 7616.0 1.2 0.0 61440.0 9861.2 153056.0 114948.1 128128.0 114187.1 15744.0 13570.4 520 10.082 3 1.456 11.539
7616.0 7616.0 1.2 0.0 61440.0 11090.6 153056.0 114948.1 128128.0 114187.1 15744.0 13570.4 520 10.082 3 1.456 11.539
7616.0 7616.0 1.2 0.0 61440.0 12328.5 153056.0 114948.1 128128.0 114187.1 15744.0 13570.4 520 10.082 3 1.456 11.539
7616.0 7616.0 1.2 0.0 61440.0 13557.9 153056.0 114948.1 128128.0 114187.1 15744.0 13570.4 520 10.082 3 1.456 11.539
7616.0 7616.0 1.2 0.0 61440.0 14789.4 153056.0 114948.1 128128.0 114187.1 15744.0 13570.4 520 10.082 3 1.456 11.539[root@test2 ~]# top -p 9752
top - 15:01:46 up 364 days, 21:10, 4 users, load average: 1.00, 0.83, 0.64
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 9.3 us, 16.3 sy, 0.0 ni, 74.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
GiB Mem : 7.6 total, 0.1 free, 6.2 used, 1.3 buff/cache
GiB Swap: 3.9 total, 2.8 free, 1.1 used. 0.8 avail MemUnknown command - try 'h' for helpPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND9752 root 20 0 3756.8m 603.4m 15.6m S 3.7 7.7 11:56.36 java
发现我们将最大元空间调整到256M后:
MC:元空间大小,大概为125m;MU:元空间使用大小,大概为111m;- 整个进程占用内存达到了
600MB;
如果我们想降低内存占用,目前只能尝试去降低堆内存。
4.3 MAT分析
程序稳定运行后,dump堆内存文件;
jmap -dump:format=b,file=9752.hporf 9752
4.3.1 概览
使用MemoryAnalyzer工具分析加载dump文件:

OverView功能是导入了dump文件之后,对可能出现的问题做了一个整体性的分析概述,首先呈现在眼前的是以一个形状图的方式,快速展现了该文件中dump文件大小,以及类、对象和类加载器的数量。
4.3.2 查看某块内存区域
当光标移动到蓝色区域时候,会呈现该日志文件的主要线程,类加载器,深堆,浅堆信息;

通过List objects可以查看这块区域的对象信息:

比如org.springframework.boot.loader.LaunchedURLClassLoader其Retained Heap为13118928Byte=12.51MB,与上图中大小一致;

4.3.3 Leak Suspects
在该菜单下,另一个比较好用的就是这个Leak Suspects功能,MAT分析工具会根据你导入的dump文件,快速生成一份怀疑报告,将可能出现内存泄露的点展示出来,便于开发或运维人员进行问题定位;

4.3.4 Histogram
Histogram列举类的实例信息:

当点击进去之后,为我们呈现出dump文件中,已经创建的主要的对象信息,默认按照Shallow Heap,而这个排序,多少也反映出在当前的dump文件中,那些排在前面的对象可能是我们分析问题的关键入口;


这里我们char[]类型的对象占用的内存最多,如果我们查看每个对象存放了哪些内容,可以右键List objects查看,比如我查看com.......common.schema.RegexConfig类型的对象(只有一个实例);

最后一行,也就是说我们内存中对象一共有1957023个,占用总大小为92675176byte=88.4MB。
此外,另外有2个参数值得注意,就是列举出来的Shallow Heap的和Retained Heap:
(1) shallow heap:中文意思是浅堆,它的大小为对象自身占用的内存大小,强调不包括它所引用的对象大小;
非数组类型的对象的shallow size:shallow_size=对象头+各成员变量大小之和+对齐填充;
这里的各成员变量大小之和就是实例数据,如果存在继承情况,当然要包含父类的成员变量。
注:记住不包含所引用的对象本身的大小。
数组类型的对象shallow size: shallow_size=对象头+类型变量大小*数组长度+对齐填充,其中如果类型是引用类型则是4字节或8字节(64位系统),如果是boolean类型则是1字节,以此类推。
注:这里的类型变量大小*数组长度就是实例数据,强调是变量不是对象本身。
(2) Retained heap中文意思是保留堆,它的大小为对象本身大小(即shallow heap大小)与其所引用对象大小之和;
换个说法就是当前对象被GC后,从Heap上总共能释放掉的内存,强调是GC后能释放的。即要排除被GC Roots直接或间接引用的对象。他们暂时不会被被当做Garbag。
非数组类型的对象的Retained Size:Retained Size=当前对象shallow_size+当前对象可直接或间接引用到的对象的shallow_size总和。(间接引用的含义:A->B->C, C就是间接引用);
数组类型的对象Retained Size:
- 数组的元素类型是引用类型:
Retained Size=数组对象的shallow_size+数组中各个引用对象的shallow_size之和 - 数组的元素类型为基本数据类型:
Retained Size=数组对象的shallow_size+数组中各基本数据类型大小之和
分析这个的意义在于,实际开发过程中,可能因为编码的习惯不好,导致某些类中,对象的引用链条特别长,层级也很深,最后甚至连自己都不一定能搞清楚那些对象是实际在使用的,假如正好有那么一些对象实际上并没有使用,但是在某些循环中大量创建,尤其是大对象,在这种情况下,很容易造成GC过程的失败最终引发OOM,从MAT中的这个展现的数据来看,对于快速定位那些数量较多的对象还是很有帮助的
4.3.5 线程分析概览

注意:拉到最下面,可以看到线程总数,点击线程总数,可以展开所有线程。
点击该菜单,展示出当前dump文件中,所有的线程信息,如上图所示,展示出了所有的线程,主线程,以及各个线程中的浅堆和深堆占用的大小,类加载器,是否守护线程等信息.
可以对线程排序,分析有哪些线程,减少不必要的线程,比如我这里有logback线程8个,cp30、druid、等线程,此外还有auth-schedule-pool-xx线程;

auth-schedule-pool-xx为业务线程,这里竟然有50个;因此需要检查代码,合理设置核心线程数、最大线程数等。
4.4 堆大小优化
在并发为1的情境下,通过夜莺工具查看两个小时FGC信息,可以看到FGC次数稳定在3(程序启动就会触发3次FGC),说明我们分配的堆内存应该是够用的。
此外,我们通过MAT工具对内存分析,也了解到我们内存中对象大小为88.4MB。
程序启动出现的3次FGC,主要是由于-XX:MetaspaceSize=64m设置的小了,可以考虑更改-XX:MetaspaceSize=128m。
[root@test2 data]# grep "Full GC" gc-2023-11-07_15-18-46.log.0.current -nR
3953:2023-11-07T15:19:31.407+0800: 44.512: [Full GC (Metadata GC Threshold) 2023-11-07T15:19:31.407+0800: 44.512: [Tenured: 40877K->43283K(87424K), 0.3225427 secs] 47349K->43283K(126720K), [Metaspace: 62881K->62881K(1105920K)], 0.3230060 secs] [Times: user=0.47 sys=0.00, real=0.33 secs]
[root@test2 data]# vim gc-2023-11-07_15-18-46.log.0.current
由于我们设置的堆内存最大值为256MB,而实际dump的内存只有88.4MB,因此我们可以适当降低堆内存最大值,我们更改为192MB进行尝试;
java -XX:NativeMemoryTracking=detail -jar -Xss328k -Xmx192m -Xms128m -XX:+UseSerialGC -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=256m -XX:MaxDirectMemorySize=32m -XX:ReservedCodeCacheSize=64m -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:/opt/data/gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=14 -XX:GCLogFileSize=100M xxxxxx-RELEASE.jar
需要注意的是:调整成-Xmx192m,如果设置的堆大小是一个合理的值(不会出现FGC的情况下),不会对接口性能产生影响。
4.4.1 测试1
运行SDK单元测试(并发1)、然后再运行接口测试,执行完成后;查看内存占用情况:
[root@test2 server]# jcmd 30412 VM.native_memory summary scale=MB
30412:Native Memory Tracking:Total: reserved=1492MB, committed=461MB# 堆空间内存减少
- Java Heap (reserved=192MB, committed=192MB)(mmap: reserved=192MB, committed=192MB)- Class (reserved=1139MB, committed=129MB)(classes #20503)(malloc=5MB #44057)(mmap: reserved=1134MB, committed=124MB)- Thread (reserved=55MB, committed=55MB)(thread #161)(stack: reserved=55MB, committed=55MB)(malloc=1MB #802)- Code (reserved=73MB, committed=52MB)(malloc=8MB #9181)(mmap: reserved=65MB, committed=44MB)- GC (reserved=1MB, committed=1MB)(mmap: reserved=1MB, committed=1MB)- Internal (reserved=4MB, committed=4MB)(malloc=4MB #30101)- Symbol (reserved=23MB, committed=23MB)(malloc=20MB #215218)(arena=3MB #1)- Native Memory Tracking (reserved=5MB, committed=5MB)(tracking overhead=5MB)[root@test2 server]# jstat -gc 30412 1000 100S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
6528.0 6528.0 1319.5 0.0 52480.0 19597.8 131072.0 112687.4 126848.0 113382.0 15488.0 13464.6 460 10.054 3 1.423 11.477
6528.0 6528.0 1319.5 0.0 52480.0 20574.2 131072.0 112687.4 126848.0 113382.0 15488.0 13464.6 460 10.054 3 1.423 11.477
6528.0 6528.0 1319.5 0.0 52480.0 21575.4 131072.0 112687.4 126848.0 113382.0 15488.0 13464.6 460 10.054 3 1.423 11.477
6528.0 6528.0 1319.5 0.0 52480.0 23499.2 131072.0 112687.4 126848.0 113382.0 15488.0 13464.6 460 10.054 3 1.423 11.477
6528.0 6528.0 1319.5 0.0 52480.0 24481.1 131072.0 112687.4 126848.0 113382.0 15488.0 13464.6 460 10.054 3 1.423 11.477
6528.0 6528.0 1319.5 0.0 52480.0 25455.4 131072.0 112687.4 126848.0 113382.0 15488.0 13464.6 460 10.054 3 1.423 11.477
^C[root@test2 server]# top -p 30412
top - 15:43:14 up 364 days, 21:52, 4 users, load average: 0.81, 1.01, 1.08
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 36.8 us, 6.9 sy, 0.0 ni, 55.7 id, 0.0 wa, 0.0 hi, 0.6 si, 0.0 st
MiB Mem : 7819.4 total, 183.2 free, 6304.2 used, 1331.9 buff/cache
MiB Swap: 3968.0 total, 2860.5 free, 1107.5 used. 878.5 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30412 root 20 0 3627.1m 546.7m 15.6m S 7.0 7.0 8:25.68 java
整个进程占用内存达到了546MB;并且:
EC:Eden区的大小,大概为51m;由于堆内存最大为192MB,考虑到老年代/新生代=2,所以老年代最大为64MB;EU:Eden区的使用大小,如果仍然有请求的话该值会持续上升,一直到占满Eden区,空间不足将会进行YGC;如此重复;OC:老年代大小,大概为128m;由于堆内存最大为192MB,考虑到老年代/新生代=2,所以老年代最大为128MB;OU:老年代使用大小,大概为110m;可用空间为128 - 110 = 18MB,如果空间不足,将会触发FGC;MC:元空间大小,大概为123m;MU:元空间使用大小,大概为110m;如果空间不足,将会触发FGC。
4.4.2 测试2
尝试进行数据导入、导出操作,导入2.7M的数据,然后查看内存占用情况:
[root@test2 server]jcmd 30412 VM.native_memory summary scale=MB
30412:Native Memory Tracking:Total: reserved=1501MB, committed=472MB
- Java Heap (reserved=192MB, committed=192MB)(mmap: reserved=192MB, committed=192MB)# 文件导入导出,内存占用会上升
- Class (reserved=1145MB, committed=137MB)(classes #21128)(malloc=5MB #48772)(mmap: reserved=1140MB, committed=132MB)- Thread (reserved=55MB, committed=55MB)(thread #161)(stack: reserved=55MB, committed=55MB)(malloc=1MB #802)- Code (reserved=74MB, committed=53MB)(malloc=9MB #11455)(mmap: reserved=65MB, committed=44MB)- GC (reserved=1MB, committed=1MB)(mmap: reserved=1MB, committed=1MB)- Internal (reserved=4MB, committed=4MB)(malloc=4MB #31460)- Symbol (reserved=23MB, committed=23MB)(malloc=20MB #216977)(arena=3MB #1)- Native Memory Tracking (reserved=5MB, committed=5MB)(tracking overhead=5MB)[root@test2 server]# jstat -gc 30412 1000 100S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT
6528.0 6528.0 0.0 1115.5 52480.0 44102.4 131072.0 115016.5 134656.0 115931.7 16640.0 13829.5 606 12.723 4 2.142 14.866
6528.0 6528.0 0.0 1115.5 52480.0 45540.8 131072.0 115016.5 134656.0 115931.7 16640.0 13829.5 606 12.723 4 2.142 14.866
6528.0 6528.0 0.0 1115.5 52480.0 47085.3 131072.0 115016.5 134656.0 115931.7 16640.0 13829.5 606 12.723 4 2.142 14.866
6528.0 6528.0 0.0 1115.5 52480.0 48523.7 131072.0 115016.5 134656.0 115931.7 16640.0 13829.5 606 12.723 4 2.142 14.866[root@test2 server]# top -p 30412
top - 16:12:43 up 364 days, 22:21, 4 users, load average: 0.56, 0.74, 1.08
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.9 us, 4.1 sy, 0.0 ni, 93.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 7819.4 total, 188.5 free, 6310.3 used, 1320.6 buff/cache
MiB Swap: 3968.0 total, 2860.8 free, 1107.2 used. 872.7 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30412 root 20 0 3633.1m 575.9m 15.6m S 5.8 7.4 11:39.91 java
可以看到FGC次数变成了4次,这说明文件导入触发了一次FGC操作,这主要是因为导入数据2.7M多数据,程序需要大量的内存对数据进行处理。此外整个进程占用内存达到了575MB。
4.4.3 持续观察
接下来程序持续运行一段时间,前期每过大约半个小时执行一个SDK单元测试,后面调整为每过大约3分钟执行一个SDK单元测试,观察FGC频率;

最上面是CPU占用清情况,当单元测试运行时,CPU占用率变高。
接着是物理内存实际占用情况,可以看到物理内存从最初的550M左右缓慢持续上升,已经达到630MB,存在一定的风险。我们查看一下物理内存实际占用情况:
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.7 us, 1.2 sy, 0.0 ni, 97.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 7819.4 total, 196.0 free, 6417.4 used, 1206.0 buff/cache
MiB Swap: 3968.0 total, 2863.3 free, 1104.7 used. 762.6 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30412 root 20 0 3657.1m 629.7m 15.5m S 4.0 8.1 137:52.98 java
剩下的是FGC以及OU情况,大概每过一段时间会发生一次FGC,并且从老年区使用情况(OU)可以看到每次FGC之后,OU都会降低到一个相对稳定的值。
由于我们的堆内存很小,尽管采用了串行回收算法,FGC时间大概也只有1s,如果业务场景用户较多的话,还是尽量采用并行或者G1垃圾回收算法。
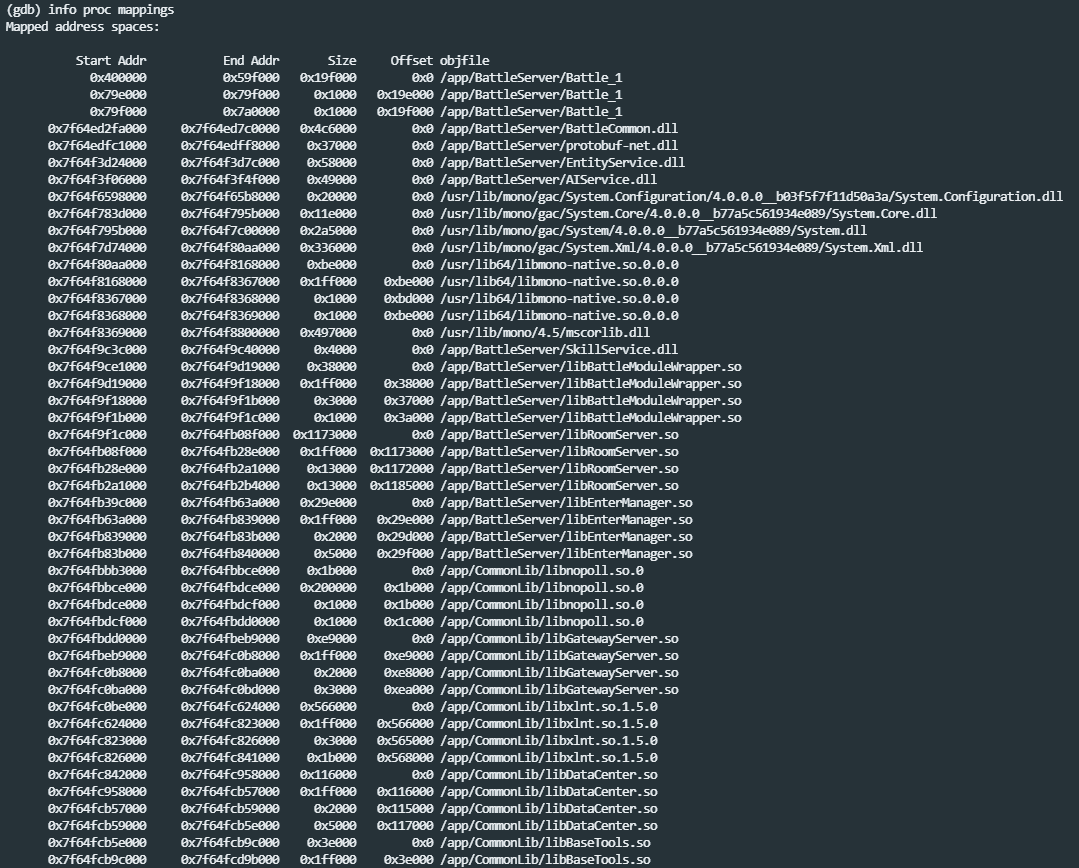
4.4.4 pmap + smaps + gdb分析
由于我们在持续观察的过程中,发现物理内存有升高的分享,虽然物理内存上升的不多。但是我还是想弄清楚是什么造成了物理内存的上升。
在linux,有一个很有用的工具,pmap命令,可以用来展示Java进程完整的内存映射。
执行如下命令可以根据实际内存排序(11月8号,6点左右):
[root@test2 server]# pmap -x 30412 | sort -n -k3 > pmap-sorted.txt
[root@test2 server]# cat pmap-sorted.txt
Address Kbytes RSS Dirty Mode Mapping
......
00007ff1c0000000 8108 6988 6988 rw--- [ anon ]
00007ff1f8000000 8512 8512 8512 rw--- [ anon ]
00007ff20849c000 9028 9004 9004 rw--- [ anon ]
00007ff209b22000 13156 9676 0 r-x-- libjvm.so
00007ff188000000 11036 9844 9844 rw--- [ anon ]
00007ff184000000 65528 12192 12192 rw--- [ anon ]
0000000100000000 18816 18748 18748 rw--- [ anon ]
00007ff1e0000000 22548 22548 22548 rw--- [ anon ]
00007ff1e4000000 64488 33848 33848 rw--- [ anon ] # 33MB 测试发现该快内存会持续增大 11月10号,1点左右 53844/52MB
00007ff1dc000000 61304 37164 37164 rw--- [ anon ] # 36MB 测试发现该快内存会持续增大 11月10号,1点左右 54452/53MB
00007ff204000000 53736 45776 45776 rw--- [ anon ] # 44MB 未变化
00007ff200000000 47360 46704 46704 rwx-- [ anon ] # 45MB 测试发现该快内存会持续增大 11月10号,1点左右 50840/49MB
00000000f4000000 65536 65536 65536 rw--- [ anon ] # 新年代 64MB 未变化
00000000f8000000 131072 131072 131072 rw--- [ anon ] # 老年代 128MB 未变化
total kB 3746076 657528 642360
内存映射是一个很长的表格,展示了进程拥有的每一个地址空间范围,这其中我们能看到地址空间范围的长度和对应的RSS内存大小占用。有一些区域是映射给了磁盘上的jar文件或者so共享库文件,其他是匿名的,代表的是内存而不是文件。
最下面的几个内存块占用的内存相对较多,那有没有办法知道里面存的是什么内容呢,答案是肯定的。经过一番资料查阅,发现可以通过gdb的命令把指定地址范围的内存块dump出来。
要执行gdb的dump需要先知道一个地址范围,通过smaps可以输出进程使用的内存块详细信息,包括地址范围和来源;
[root@test2 server]# cat /proc/30412/smaps > smaps.txt
查看smaps.txt,找到有问题的内存块地址,比如下面的f8000000-100000000;
f4000000-f8000000 rw-p 00000000 00:00 0
Size: 65536 kB # 申请的虚拟内存大小
Rss: 65536 kB # 64MB,应该就是新生代 实际申请的物理内存
Pss: 65536 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 65536 kB
Referenced: 65536 kB
Anonymous: 65536 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
VmFlags: rd wr mr mp me ac sd
f8000000-100000000 rw-p 00000000 00:00 0
Size: 131072 kB
Rss: 131072 kB # 128MB,应该就是老年代OC
Pss: 131072 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 131072 kB
Referenced: 131072 kB
Anonymous: 131072 kB
AnonHugePages: 2048 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
VmFlags: rd wr mr mp me ac sd
7ff200000000-7ff202e40000 rwxp 00000000 00:00 0
Size: 47360 kB
Rss: 46704 kB # 45MB
Pss: 46704 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 46704 kB
Referenced: 46704 kB
Anonymous: 46704 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
VmFlags: rd wr ex mr mp me ac sd
7ff204000000-7ff20747a000 rw-p 00000000 00:00 0
Size: 53736 kB
Rss: 45776 kB # 44MB 应该是Code Cache
Pss: 45776 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 45776 kB
Referenced: 45776 kB
Anonymous: 45776 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
7ff1dc000000-7ff1dfbde000 rw-p 00000000 00:00 0
Size: 61304 kB
Rss: 37164 kB # 36MB
Pss: 37164 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 37164 kB
Referenced: 37164 kB
Anonymous: 37164 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
7ff1e4000000-7ff1e7efa000 rw-p 00000000 00:00 0
Size: 64488 kB
Rss: 33848 kB # 33MB
Pss: 33848 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 33848 kB
Referenced: 33848 kB
Anonymous: 33848 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
启动gdb:
[root@test2 server]# gdb attach 30412
(1) dump指定内存地址到指定的目录下,参数的地址需要在smaps拿到地址前加上0x:
dump memory /tmp/0xf8000000-0x100000000.dump 0xf8000000 0x100000000
显示长度超过100字符的字符串
strings -100 /tmp/0xf8000000-0x100000000.dump
发现里面有有大量的SQL语句在内存中,这部分内存应该是位于堆内存老年代中,正常来说是可以通过FGC释放掉。
此外:Druid连接池的监控stat可能造成内存泄漏Druid连接池的监控stat造成内存泄漏。
(2) dump指定内存地址到指定的目录下,参数的地址需要在smaps拿到地址前加上0x:
dump memory /tmp/0xf4000000-0xf8000000.dump 0xf4000000 0xf8000000
显示长度超过100字符的字符串
strings -100 /tmp/0xf4000000-0xf8000000.dump
发现里面有有大量的SQL语句在内存中,这部分内存应该是位于堆内存新生代中,正常来说是可以通过YGC释放掉。
(3) dump指定内存地址到指定的目录下,参数的地址需要在smaps拿到地址前加上0x:
dump memory /tmp/0x7ff200000000-0x7ff202e40000.dump 0x7ff200000000 0x7ff202e40000
显示长度超过10字符的字符串
strings -10 /tmp/0x7ff200000000-0x7ff202e40000.dump

这块内存放的是什么,目前我也没有看出来。
(4 ) dump指定内存地址到指定的目录下,参数的地址需要在smaps拿到地址前加上0x:
dump memory /tmp/0x7ff204000000-0x7ff20747a000.dump 0x7ff204000000 0x7ff20747a000
显示长度超过100字符的字符串
strings -100 /tmp/0x7ff204000000-0x7ff20747a000.dump
这块看着像java类相关的信息,具体是啥我也不太了解。
(5 ) dump指定内存地址到指定的目录下,参数的地址需要在smaps拿到地址前加上0x:
dump memory /tmp/0x7ff1dc000000-0x7ff1dfbde000.dump 0x7ff1dc000000 0x7ff1dfbde000
显示长度超过100字符的字符串
strings -100 /tmp/0x7ff1dc000000-0x7ff1dfbde000.dump

这块看着也像java类相关的信息,具体是啥我也不太了解。
(6 ) dump指定内存地址到指定的目录下,参数的地址需要在smaps拿到地址前加上0x:
dump memory /tmp/0x7ff1e4000000-0x7ff1e7efa000.dump 0x7ff1e4000000 0x7ff1e7efa000
显示长度超过20字符的字符串
strings -20 /tmp/0x7ff1e4000000-0x7ff1e7efa000.dump

经过分析几块大内存的数据都dump出来看了一遍,没发现存在啥问题。
4.5 推荐配置
700MB:
java -jar -Xss328k -Xmx192m -Xms128m -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=256m -XX:MaxDirectMemorySize=32m -XX:ReservedCodeCacheSize=64m xxxxxx-RELEASE.jar
1GB:
java -jar -Xss328k -Xmx256m -Xms128m -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=256m -XX:MaxDirectMemorySize=32m -XX:ReservedCodeCacheSize=64m xxxxxx-RELEASE.jar
参考文章
[1] 一次Java内存占用高的排查案例,解释了我对内存问题的所有疑问
[2] JVM实际内存占用超过Xmx的原因,设置Xmx的技巧
[3] 带你认识JDK8中超nice的Native Memory Tracking
[4] 【JVM案例篇】堆外内存(JNI Memory)泄漏(Linux经典64M内存块问题)
[5] JVM中FGC和YGC分析
[6] Eclipse Memory Analyzer(MAT) 使用总结
[7] [记一次堆外内存泄漏排查过程]
[8] java内存缓慢攀升 java内存越来越大
[9] Java进程的内存占用(推荐)




![折腾笔记[10]-使用rust进行ORB角点检测](https://img2024.cnblogs.com/blog/1048201/202501/1048201-20250122162744091-1048158816.png)