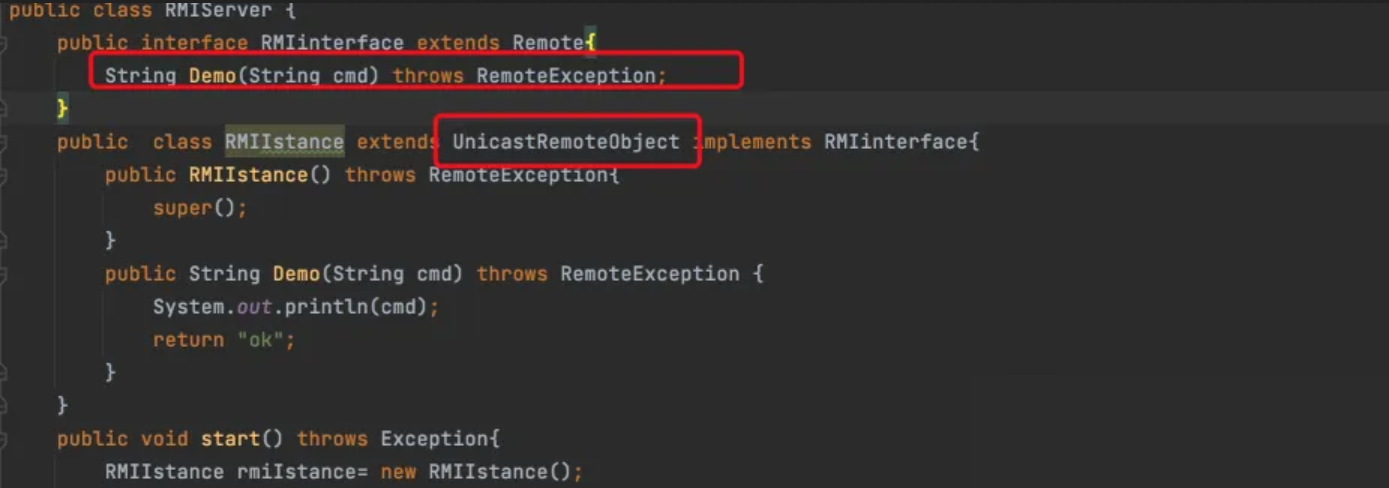
今日学习了Spark Streaming的基本原理,包括DStream的创建和操作
完成了Spark Streaming的代码示例,实现了一个简单的实时数据处理程序
from pyspark import SparkContext from pyspark.streaming import StreamingContext# 初始化Spark Streaming上下文 sc = SparkContext(appName="SimpleSparkStreaming") ssc = StreamingContext(sc, batchDuration=5) # 设置微批处理的时间间隔为5秒# 创建一个DStream,从Socket接收数据 # 假设数据通过Socket发送到localhost的9999端口 lines = ssc.socketTextStream("localhost", 9999)# 对接收到的每行数据进行处理 # 示例:统计每行数据中单词的数量 words = lines.flatMap(lambda line: line.split(" ")) # 将每行数据分割为单词 word_counts = words.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b) # 对单词进行计数# 打印每个微批处理的结果 word_counts.pprint()# 启动StreamingContext ssc.start()# 等待程序运行 ssc.awaitTermination()