多LLM文本摘要:创新方法与卓越成果

论文
https://arxiv.org/abs/2412.15487
Multi-LLM Text Summarization 2412.15487
多LLM摘要框架在每一轮对话中有两个至关重要的步骤:生成和评估。根据使用的是多LLM去中心化摘要还是中心化摘要,这些步骤会有所不同。在这两种策略中,k个不同的大语言模型(LLM)都会生成文本的多样摘要。然而,在评估阶段,多LLM中心化摘要方法利用单个大语言模型来评估摘要并选择最佳摘要,而去中心化多LLM摘要则使用k个大语言模型进行评估。
方法
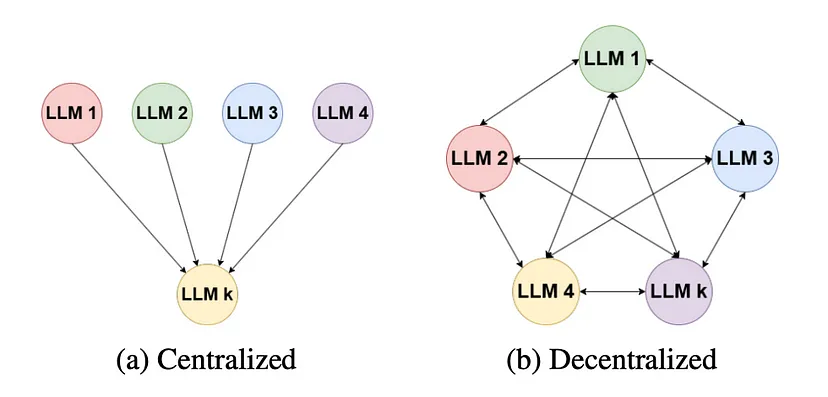
以使用5个大语言模型的示例来说明中心化和去中心化方法。
该方法处理的长文本输入可能长达数万字,这通常超出了大多数标准大语言模型的上下文窗口。为了解决这个问题,建立了一个两阶段的过程,包括对源文档进行分块,独立总结源文档的每个块,然后对连接的中间结果进行第二轮分块和总结 。在这两个阶段中,两种框架都允许多个大语言模型协作,最终生成整个原始参考文档高质量的单一最终摘要。
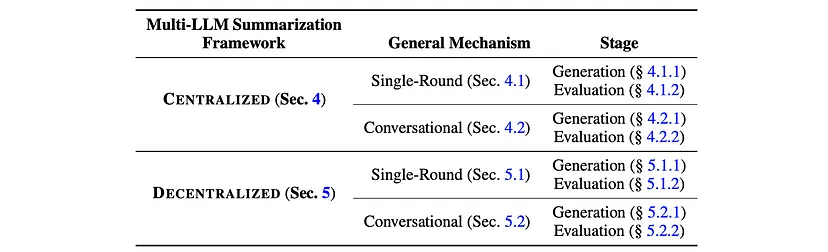
多LLM摘要框架概述
中心化多LLM摘要

- 单轮:每个大语言模型都会被提示一次,然后收集它们的摘要。随后通过一个评估步骤来选择最佳的最终摘要。在单轮设置中,参与模型列表中的每个大语言模型Mj∈M,都会使用通用提示P独立生成相同输入文本的摘要。对于每个大语言模型Mj,输出为Sj =Mj(P,S),其中S代表输入文本。对所有Mj运行此步骤会产生一组摘要S = {S1,…,Sk}。从概念上讲,每个模型都贡献了其独特的视角,从而形成了多样化的候选摘要池,这对于后续评估阶段中稳健地选择摘要非常重要。

在收集到候选摘要集S后,一个中央代理C∈M会评估这些摘要。中央大语言模型C使用评估提示Pec来评估每个摘要的质量。正式表示为,E = C(Pec, S),其中E是中央大语言模型对所有候选摘要的评估结果。这包括选择最佳摘要(以匿名标识符表示)以及该评估的置信度得分(表示为0到10之间的整数)。通过对标识符进行去匿名化来恢复所选摘要Sj的文本,并将其设置为最终输出S∗。在单轮模式下,由于不再进行进一步的迭代,因此该过程到此结束。

- 对话式:生成和评估阶段会重复多次。每个生成-评估过程被定义为一轮,并且定义了该过程结束或开始新一轮的条件,最多进行指定的最大轮数。对话式方法的第一轮与单轮过程类似。每个大语言模型Mj使用提示P从原始输入文本S生成初始摘要S(1)j :S(1) =Mj(P,S)。如果上一轮的评估结果置信度得分低于阈值,或者如果大语言模型未能输出可读的置信度得分,则流程进入下一轮。在第二轮及后续轮次中,会使用提示P(i)。后续轮次中的大语言模型既可以访问要总结的文本,也可以访问上一轮的摘要。具体来说,在第i>1轮中:S(i)j =Mj(P(i),S)。

第i>1轮的评估阶段在概念上与单轮设置类似,但现在是对在生成阶段刚刚生成的候选摘要Si = {S1(i), . . . , Sk(i)}进行评估。中央大语言模型C使用Pec评估这些候选摘要:E(i) = C(Pec, Si)。如果置信水平达到阈值,该过程终止,并且中央大语言模型选择的摘要被接受为S∗。否则,该过程进入下一轮摘要生成和评估。

去中心化多LLM摘要

- 单轮:生成过程与中心化方法中的相同。多个大语言模型独立为输入文本生成摘要,从而获得摘要列表S = {S1,…,Sk}。在评估时,每个生成摘要的模型都会收到一个新的评估提示(该提示不包含置信水平),并且会收到要总结的文本以及所有代理(包括其自身)生成的摘要。更正式地说,收集模型偏好E(i), . . . , E(i) ,其中每个E(i)代表模型Mj在S(i),…,S(i)中选择的最佳摘要。当大多数模型选择相同的摘要时,就达成了收敛。当没有出现多数选择时,在单轮方法(tmax = 1)中,算法会从指定的决胜模型Mt中选择摘要。


- 对话式:生成过程遵循与中心化方法相同的方法,生成摘要集S = S1 , . . . , Sk 。与单轮方法的一个关键区别在于条件再生机制:当第一轮未能达成共识时,后续轮次会使用一个新的提示,该提示包含先前评估生成的摘要。第一轮评估与单轮方法中的评估相同,但会使用新的生成提示进入额外的轮次。在单轮情况下,未达成共识会立即触发回退到决胜模型。相比之下,对话式方法会使用更新后的提示启动新的生成-评估轮次。这个过程会一直持续,直到出现多数共识或者达到最大轮数tmax。如果在tmax轮后仍未达成共识,算法将默认使用决胜机制。


实验设置
使用ArXiv和GovReport来评估摘要方法。使用ROUGE-1、ROUGE-L、BLEU-1和BLEU-4指标来评估大语言模型生成的摘要的质量。为了与多LLM方法进行比较,将GPT-3.5、GPT-4o、GPT-4o mini和LLaMA3–8B作为基线。所有模型都使用4K字符的块大小,最终摘要由生成的摘要连接而成。
评估
去中心化和中心化多LLM方法的结果。
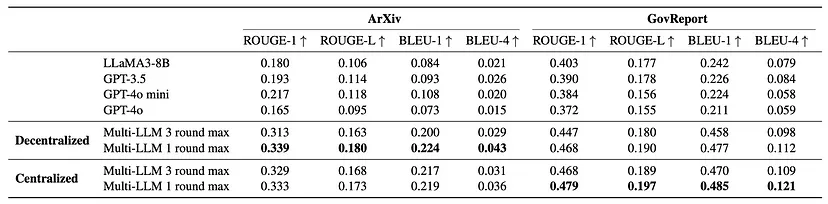
多LLM方法在不同评估和决胜模型下的结果。
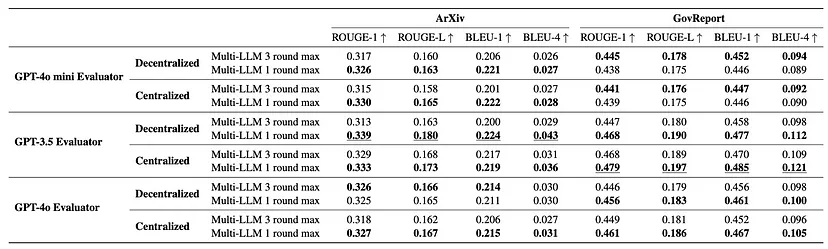
多LLM框架显著优于单LLM基线,在某些情况下提升高达3倍。
中心化多LLM方法的得分平均提高了73%,而去中心化方法的得分平均提高了70%。
仅使用两个大语言模型以及单轮的生成和评估就能带来显著的性能提升,这表明了该方法的成本效益。
该框架的有效性在不同的中央模型(评估器)和决胜模型中是一致的。
使用两个以上的大语言模型以及额外的生成和评估轮次并不会带来进一步的改进。
代码实现
from langchain_ollama import ChatOllamagemma2 = ChatOllama(model="gemma2:9b", temperature=0)
llama3 = ChatOllama(model="llama3:8b", temperature=0)
llama3_1 = ChatOllama(model="llama3.1:8b", temperature=0)prompt_initial_summary = """
Provide a concise summary of the text in around 160 words.
Output the summary text only and nothing else.
{text}
""".strip()prompt_subsequent_summary = """
Given the original text below, along with the summaries of that text by 3 LLMs,
please generate a better summary of the original text in about 160 words.
ORIGINAL:
{text}
Summary by agent_1:
{summary_1}
Summary by agent_2:
{summary_2}
Summary by agent_3:
{summary_3}
""".strip()prompt_decentralised_evaluation = """
Given the original text below, along with the summaries of that text by 3 agents,
please evaluate the summaries and output the name of the agent that has the best summary.
Output the exact name only and nothing else.
ORIGINAL:
{text}
Summary by agent_1:
{summary_1}
Summary by agent_2:
{summary_2}
Summary by agent_3:
{summary_3}
""".strip()prompt_centralised_evaluation = """
Given the initial text below, along with the summaries of that text by 3 LLMs,
please evaluate the generated summaries and output the name of the LLM has the best summary.
On a separate line indicate a confidence level between 0 and 10.
ORIGINAL:
{text}
Summary by agent_1:
{summary_1}
Summary by agent_2:
{summary_2}
Summary by agent_3:
{summary_3}
Remember, on a separate line indicate a confidence level between 0 and 10.
""".strip()prompt_concate = """
Provide a concise summary of the text in around 160 words.
Output the summary text only and nothing else.
{summaries}
""".strip()class SingleTurnCentralised():def __init__(self, models):self.models = modelsdef generate(self, text):summaries = []for model in self.models:summaries.append(model.invoke([{"role": "user", "content": prompt_initial_summary.format(text=text)}]).content)return summariesdef evaluate(self, text, summaries):response = gemma2.invoke([{"role": "user", "content": prompt_centralised_evaluation.format(text=text, summary_1=summaries[0], summary_2=summaries[1], summary_3=summaries[2])}]).contentwinner, *_, confidence = response.split()return winner, confidencedef __call__(self, chunks):summarised_chunks = []for chunk in chunks:summaries = self.generate(chunk)winner, confidence = self.evaluate(chunk, summaries)summarised_chunks.append(summaries[int(winner[-1]) -1])final_summary = gemma2.invoke([{"role": "user", "content": prompt_concate.format(summaries="\n".join(summarised_chunks))}]).contentreturn final_summarysingle_turn_centralised = SingleTurnCentralised([gemma2, llama3, llama3_1])
final_summary = single_turn_centralised(chunks)
LLM架构专栏文章
1. LLM大模型架构专栏|| 从NLP基础谈起
2.LLM大模型架构专栏|| 自然语言处理(NLP)之建模
3. LLM大模型架构之词嵌入(Part1)
4. LLM大模型架构之词嵌入(Part2)
5. LLM大模型架构之词嵌入(Part3)
6. LLM架构从基础到精通之循环神经网络(RNN)
7. LLM架构从基础到精通之LSTM
8. LLM架构从基础到精通之门控循环单元(GRUs)
9. 20000字的注意力机制讲解,全网最全
10. 深入探究编码器 - 解码器架构:从RNN到Transformer的自然语言处理模型
11. 2w8000字深度解析从RNN到Transformer:构建NLP应用的架构演进之路
欢迎关注公众号 柏企科技圈 与柏企阅文 如果您有任何问题或建议,欢迎在评论区留言交流!
本文由mdnice多平台发布





![折腾笔记[11]-使用rust进行直接法视觉里程计估计](https://img2024.cnblogs.com/blog/1048201/202501/1048201-20250123123551774-423709835.png)