无论片内还是片外访存,存储器的访存代价非常大 [1]。因此有非常多的工作放眼在减少 memory access 以提升系统能耗和表现。我将减少访存归类为三种方法:
- 发掘数据复用。如矩阵乘法中输入某个矩阵的某一行/列要多次复用读入,依次可以读取一次之后利用先前读取的结果,这一类方法依赖于算法的数据复用特征,复用度越高意义越大。软件代表工作有 timeloop,硬件代表工作有 systolic array 复用输入输出,各种加速器中广泛存在的 accumulator 复用输出中间变量。
- Fused Operation。每次操作都需要读入数据并输出数据,计算过程中有大量中间变量生成以及相应的读写操作。把相邻操作作为一个整体,将内部中间变量直接通过执行单元之间数据通路或者较低层次的 memory 就可以避开高层次高代价的 memory access。其本质也可以算作一种对中间变量读/写的一种数据复用,软件代表工作有各种加速库 fusion 算子,硬件代表工作有 DIANNAO 最早提及处理的执行 pipeline,MAC 单元后接 activation Speical Unit 基本成为加速器基操。
- Recomputaion。本质来自存储空间有限和某些变量生存周期较长之间的矛盾,对计算图某个节点重复执行以节约存储空间进而减少 memory access。这种范式由于对编译器改动较大暂时没有看到比较系统的工作。
这三种范式编译器开发难度依次增大,所有程序本质上都是数据依赖图,但 NP 问题优化算力有限,需要分而治之划分为多个子图,或者称算子和 kernel 进行局部优化。数据复用大致上没有改变 kernel 的范围优化难度相对较低,因此目前工作分析已经相对完备。而第二种扩大了 kernel 的范围,优化难度提高,无论软件或是硬件目前主要靠人力维护算子库或者依赖硬件架构师的经验。
但此类硬件工作本质上也和写算子差不多,依靠人为经验确定结构固化在电路上。最近也有很多新型的 spatial accelerator 选择在更通用的互联数据流架构上发力 [2] [3],一来支持更加通用的加速优化,二来将硬件设计的人力转移到软件编译器层面,降低迭代周期和成本。
通用性架构往往需要引入各类互联网络以及相应的控制流,通路的 overhead 是否会超过优势?如果优势立得住的,那么又如何在参数空间取值以 trade-off?额外开销反映在 both 硬件和软件,本文尝试从硬件视角建立一个简单 baseline 比较开销。
软件和硬件 Baseline
考虑如下伪代码
D1 = SiLU(D0)
D2 = Exp(D1)
这两种在 SambaNova 总结的操作流类型中属于最简单的 element-wise map 操作[3:1],数据通路较为简单利于展开分析。
考虑我们的硬件系统拥有一个存储 SRAM ,以及两个定制化的 SiLU 和 Exp 执行单元,所有执行单元都是纯组合逻辑。另外一个先验是现有的大部分网络单层算子的维度远远大于硬件规格,即使一个算子也要拆分多个周期完成,比如 SiLU 算子在时间上分别执行 SiLU#0、SiLU#1、SiLU#2 ... 完成,或者说代码中的循环是必然的 。我们假设 SRAM 和执行单元的数据宽度都是一致。
硬件执行表现分析
考虑传统硬件通路设计,即执行单元之间不存在直接通路,所有的数据交互都需要通过 SRAM 完成。比如 D1 数据就需要先从 SiLU 单元写入 SRAM,然后 exp 单元再从 SRAM 中读出。假设每个算子维度叫做宽度,多个算子连接叫做深度,执行上有两种策略:
- 深度优先(DF)。SiLU #0, Exp#0, SiLU #1, Exp#1。
- 宽度优先(BF)。SiLU #0, SiLU#1, Exp#0, Exp#1。
Single Port
假设 SRAM 是 Signle Port,此时 SRAM 的接口带宽全部占满,无论 DF 还是 BF 都会卡在 SRAM 上结果一致。

Dual Port - BF
我们尝试给 Memory 添加 dual port ,以同时支持读写。因为本身读写操作带有延时,从读取到写入需要两个周期完成,为避免数据依赖导致的序列化延时,采用 BF 策略。
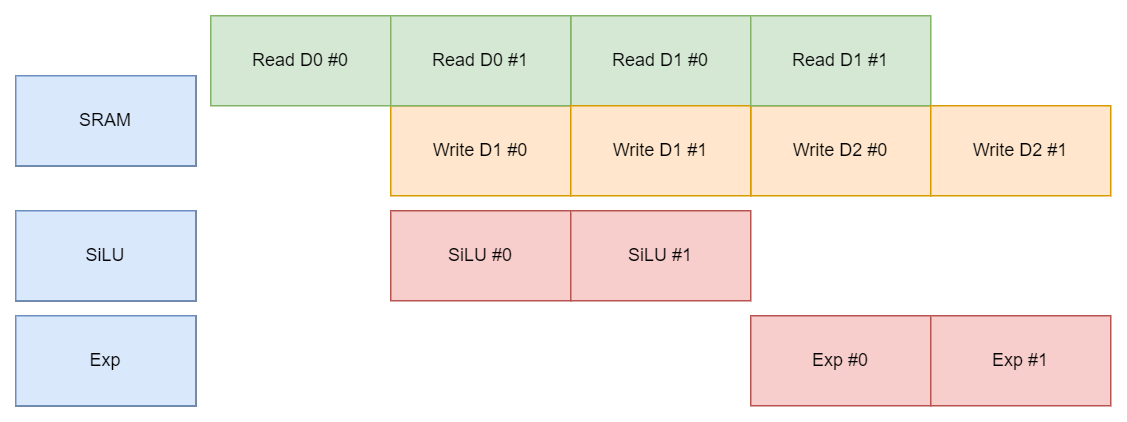
总体延时减少了,但除去启动推出阶段(Prologue/Epilogue),稳定阶段(Steady)SRAM 的吞吐仍然被占满而执行单元 utilization 较低,是否可以进一步提高 SRAM 吞吐减少延时。
Multi-bank
SRAM 可大致看为由 6T 存储阵列以及读入读出接口组成,我们分析互联代价需要保持存储 capacity 不变而改变接口带宽。有三种方法:
- 直接添加 port 的数量。比如 single port 到 dual port,好处是多个 port 共用同一块存储空间,可以真正意义上 random access,但存在电路上限,一般 PDK 提供类型还是以 1~2 个 port 为主;
- 减少 SRAM 深度增加宽度。但注意为了保持多个 EU 吞吐满,SRAM 的宽度是大于单个 EU 的宽度的。需要在电路上引入一些变宽 FIFO 来转换数据宽度,控制流复杂且适用场景有限(我尝试绘制了这种情况的 pipeline,不会减少太多 latency);
- 缩小每个 bank 的深度,增加 bank 数量。这里 bank 的含义是逻辑上每个 bank 的地址都有相应的电路独立控制,而非物理上生成多个 bank 然后用统一的地址逻辑管理拼成一个统一的逻辑存储。这种方法可以充分利用增加的带宽,但对数据的 memory layout 有一定要求,否则可能导致 serialized 降低性能,可见 ThunderKittens [4] 对 GPU L2 Cache memory layout 的分析。
为了突出稳定阶段的变化,绘制更多循环次数的示意图。

通过添加 bank 将存储带宽再次翻倍后,稳定阶段 SRAM 和执行单元的 utilization 都达到 100%,大大降低了延时。另外仅当 serialize 严重时执行有先后 DF-BF 之分,这里单元全部跑起来没有区分边界。
Dataflow
假设 SiLU 和 Exp 单元之间存在数据通路,无需通过 SRAM 。
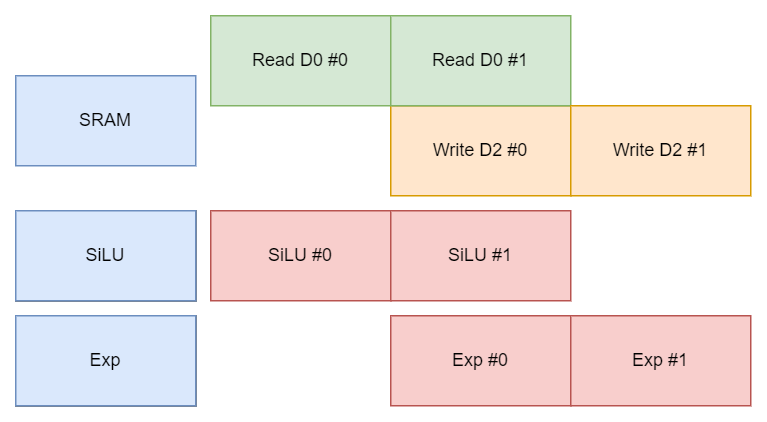
仅用 Dual Port 便实现了稳定阶段执行单元 100% 的 utilization。
代价是什么?
Multi-bank 和 Dataflow 都实现了 100% 的 utlization,那么代价是什么呢?Multi-bank 相比 Dataflow 多了一倍带宽,需要额外的读写电路支持,并且由于划分逻辑 bank 需要特殊的 memory layout 设计;Dataflow 为了支持执行单元之间的通信则需要额外的互联网络。
由于程序上 Exp 在 SiLU 之后执行,所以仅需从 SiLU 到 Exp 的通路即可实现,但电路需要保证通用性,理论上支持任意互联则要将所有可能的输入输出端口之间建立通路,比如 SiLU->Exp, Exp->SiLU,Exp->Exp,SiLU->SiLU, Buf->SiLU, Buf->Exp, SiLU->Buf, Exp->Buf。
为了泛化分析,假如系统中存在着 N 个这样的 map element-wise 单元以及一个 dual port SRAM,那么互联网络由 N 个可以选择 N 输入的 MUX 组成。而 multi-bank 系统则需要保证有 N 个 bank。量化分析需要比对添加 bank 和添加互联网络的边缘成本。
Bank 的边缘成本
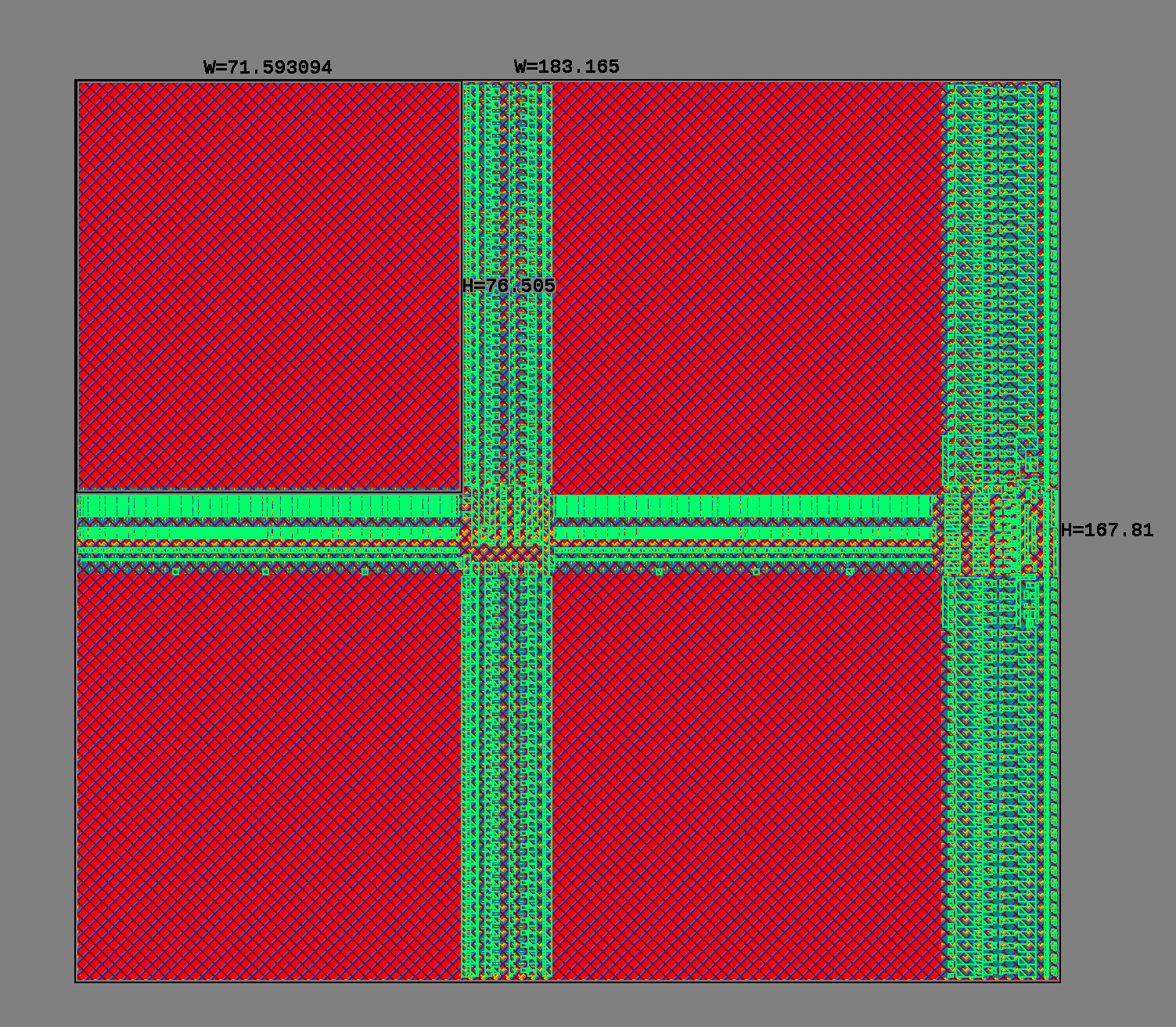
以上是宽度为 64bit 深度为 2048 的 Single Port SRAM,面积大致由三部分组成:
- Cell。图上红色的部分,cell 分布均匀密度固定,总面积和 capacity 有关;
- Necessary Driver。wordline、bitline driver、SA、decoder 等等。Dataport 和 address port 在图的右侧,右侧竖着一条主要是 bitline driver,而中间横着一条是 wordline driver。
- Additional Driver。随着阵列尺寸扩大,bitline 和 wordline 长度相应扩大,为了优化时序和能耗特性,会将 bitline 和 wordline 拆分打断(又称 {hierarchical/splitted} {wordline/bitline}),引入额外的驱动电路至负责驱动一小节,比如这里的十字架将bitline 和 wordline 都分成了两端。
这三种面积开销中,只有 cell 部分面积是固定的。但我们可以大致引入数量级比较。以下是 64bit 宽度 512 深度的 single port / dual port SRAM 面积 profile。
| Type | Cell Area | Other Area |
|---|---|---|
| Single Port | 5300 | 3860 |
| Dual Port | 5300 | 8010 |
对于 512 深度下增加 64bit 的 port,面积数量级大致在 k。
互联网络的边缘成本
之前纯理论分析 MUX 的面积正比于输入选择 port 数量 [5]。2 输入选择 MUX 代码如下,其余规格以此类推:
module mux_2to1_64bit (input wire clock, // Clock signalinput wire [63:0] in0,input wire [63:0] in1, // 2 inputsinput wire [0:0] sel, // Selection signaloutput reg [63:0] out // 64-bit registered output
);// Internal signal to hold the selected valuewire [63:0] mux_out;// The output is assigned based on the value of selassign mux_out = sel == 1'd0 ? in0 :sel == 1'd1 ? in1 : 64'b0;// Register the output on the rising edge of the clockalways @(posedge clock) beginout <= mux_out;endendmodule
因为执行单元组合逻辑,在网络中引入打拍才合理。以下是不同输入的 MUX 在 200 MHz 约束下的面积:
| MUX | 2-1 | 4-1 | 8-1 | 32-1 | 64-1 |
|---|---|---|---|---|---|
| Area | 628 | 671 | 803 | 1470 | 2326 |
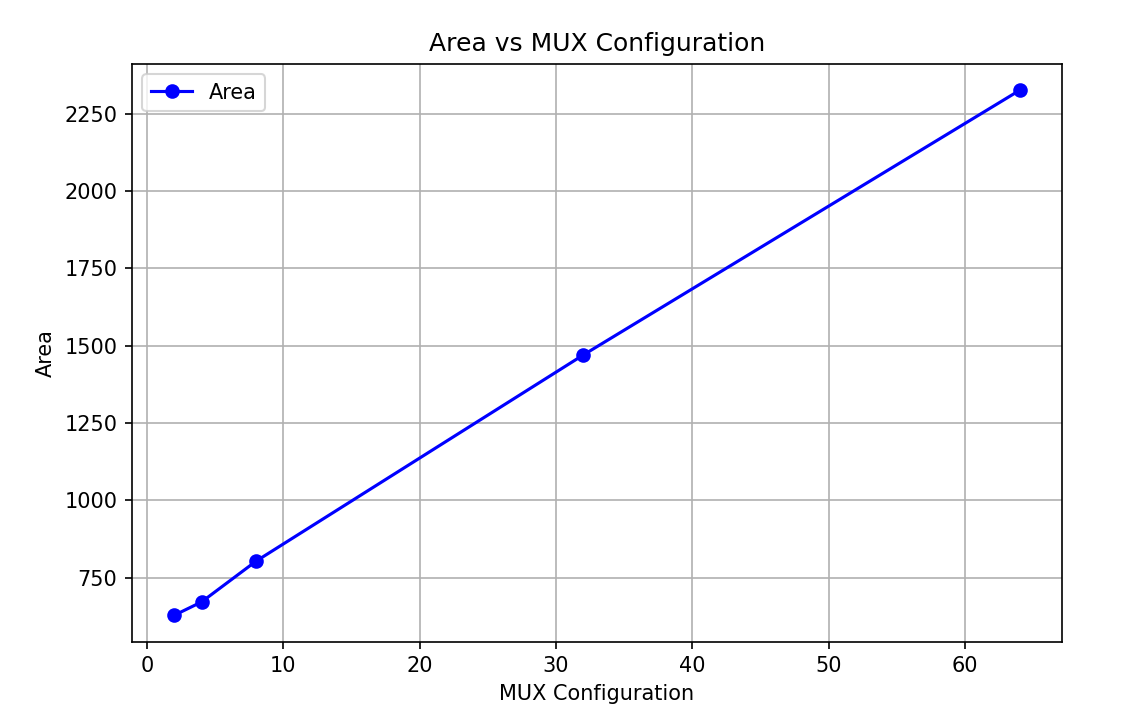
面积曲线大致成线性,验证之前分析是正确的,即 \(Area = k \times N\)。
互联 vs Bank
而整个网络互联面积应为 \(Area= k \times N^2\)。拟合斜率大致为 27.48,得到 64bit 粒度宽度下全互联网络随着计算单元个数变化的面积范围:
| N | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|
| 27.48 * N² | 109.92 | 439.68 | 1758.72 | 7043.52 | 28035.84 | 69870.72 |
| 1000 * N | 2000 | 4000 | 8000 | 16000 | 32000 | 64000 |
因为假设port增加的数量是线性的,以1000斜率预估数量级,在 8 个互联之前互联网络面积开销比 port 小一个数量级。
总结
建模较为粗糙,比如只考虑综合面积,MUX 选择应该对布局布线有很大影响;Bank 系统也应该有选择执行单元的 MUX;对 Bank 提高带宽方式分析建模并不够准确等等。但从结论来看,在 MUX 互联数量较少的情况下,面积还是有数量级的优势的,现有 CGRA 大都以相邻四向或是八向连接是能够立得住的。
硬件层面功耗实验还没考虑,而软件层面也缺失对编译栈改动的影响。值得进一步关注分析。
https://www.cnblogs.com/devil-sx/p/18563196 ↩︎
https://www.cnblogs.com/devil-sx/p/18564476 ↩︎
https://www.cnblogs.com/devil-sx/p/18476553 ↩︎ ↩︎
https://arxiv.org/abs/2410.20399 ↩︎
https://www.cnblogs.com/devil-sx/p/18446423 ↩︎