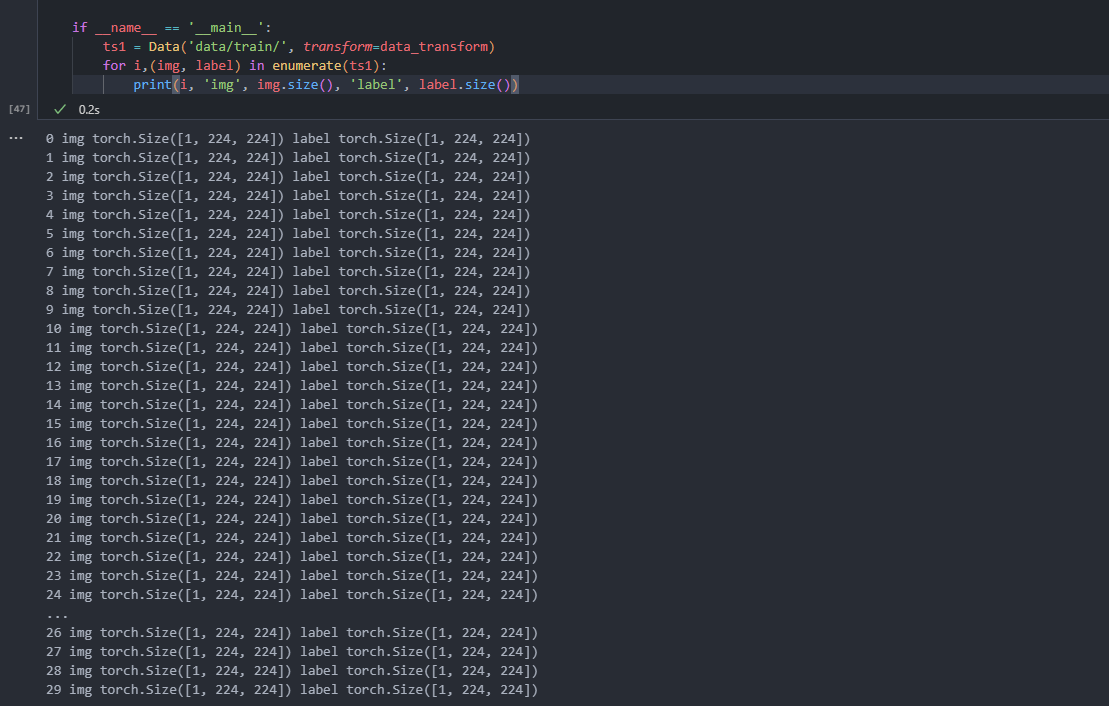
文章目录
- 配置多队列的容量调度器
- 多队列查看
配置多队列的容量调度器
首先,我们进入 Hadoop 的配置文件目录中($HADOOP_HOME/etc/hadoop);
然后通过编辑容量调度器配置文件 capacity-scheduler.xml 来配置多队列的形式。
默认只有 default 队列,显然一个队列不符合集群的生产环境,会造成队列阻塞,资源分配不合理的情况等等,所以这时候就需要配置多队列了。
需求:
-
default队列占总内存的40%,最大资源容量占总资源60% -
hive队列占总内存的60%,最大资源容量占总资源80%。
不管配置多少个队列,总内存的和值最大不超过100%,超过会直接报错。
最大资源容量单个不超过100%,同时在配置队列的情况下也不要配置为100%,那样就失去了配置队列的意义,并发情况下和单队列一样了。
修改相关配置:
<!-- 新增hive队列,默认只有default -->
<property><name>yarn.scheduler.capacity.root.queues</name><value>default,hive</value>
</property><!-- 降低default队列资源额定容量为40%,默认100% -->
<property><name>yarn.scheduler.capacity.root.default.capacity</name><value>40</value>
</property><!-- 降低default队列资源最大容量为60%,默认100% -->
<property><name>yarn.scheduler.capacity.root.default.maximum-capacity</name><value>60</value>
</property>
为新队列添加相关配置:
<!-- 指定hive队列的资源额定容量 -->
<property><name>yarn.scheduler.capacity.root.hive.capacity</name><value>60</value>
</property><!-- 用户最多可以使用队列多少资源,1表示使用所有资源,也就是百分之百 -->
<property><name>yarn.scheduler.capacity.root.hive.user-limit-factor</name><value>1</value>
</property><!-- 指定hive队列的资源最大容量 -->
<property><name>yarn.scheduler.capacity.root.hive.maximum-capacity</name><value>80</value>
</property><!-- 启动hive队列 -->
<property><name>yarn.scheduler.capacity.root.hive.state</name><value>RUNNING</value>
</property><!-- 哪些用户有权向队列提交作业 -->
<property><name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name><value>*</value>
</property><!-- 哪些用户有权操作队列,管理员权限(查看/杀死) -->
<property><name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name><value>*</value>
</property><!-- 哪些用户有权配置提交任务优先级 -->
<property><name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name><value>*</value>
</property><!-- 指定了Hive作业的最大应用程序生存时间,将参数设置为 -1 意味着不设置应用程序生存时间的限制,即Hive作业的应用程序可以一直保持运行状态,直到它们自己完成或被终止。-->
<property><name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name><value>-1</value>
</property><!-- 指定了Hive作业的默认应用程序生存时间-->
<property><name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name><value>-1</value>
</property>
配置添加完成后,分发配置到集群其它机器。
该配置设置完成后,无需重启集群,使用下列命令进行队列刷新即可:
yarn rmadmin -refreshQueues
当然,不嫌麻烦可以去重启集群。
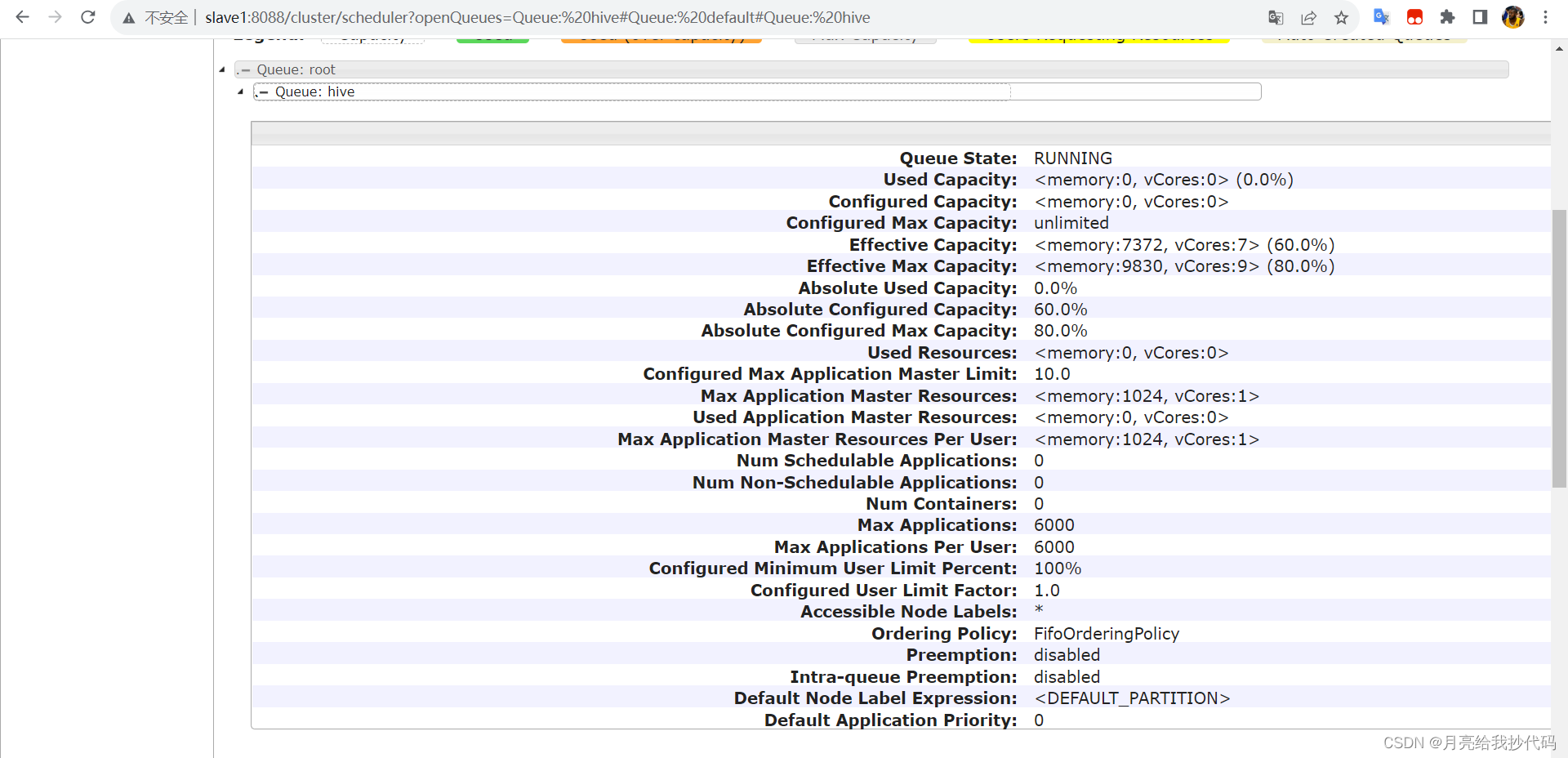
多队列查看
进入 Yarn 的 WEB 界面就可以看到我们配置好的队列了。
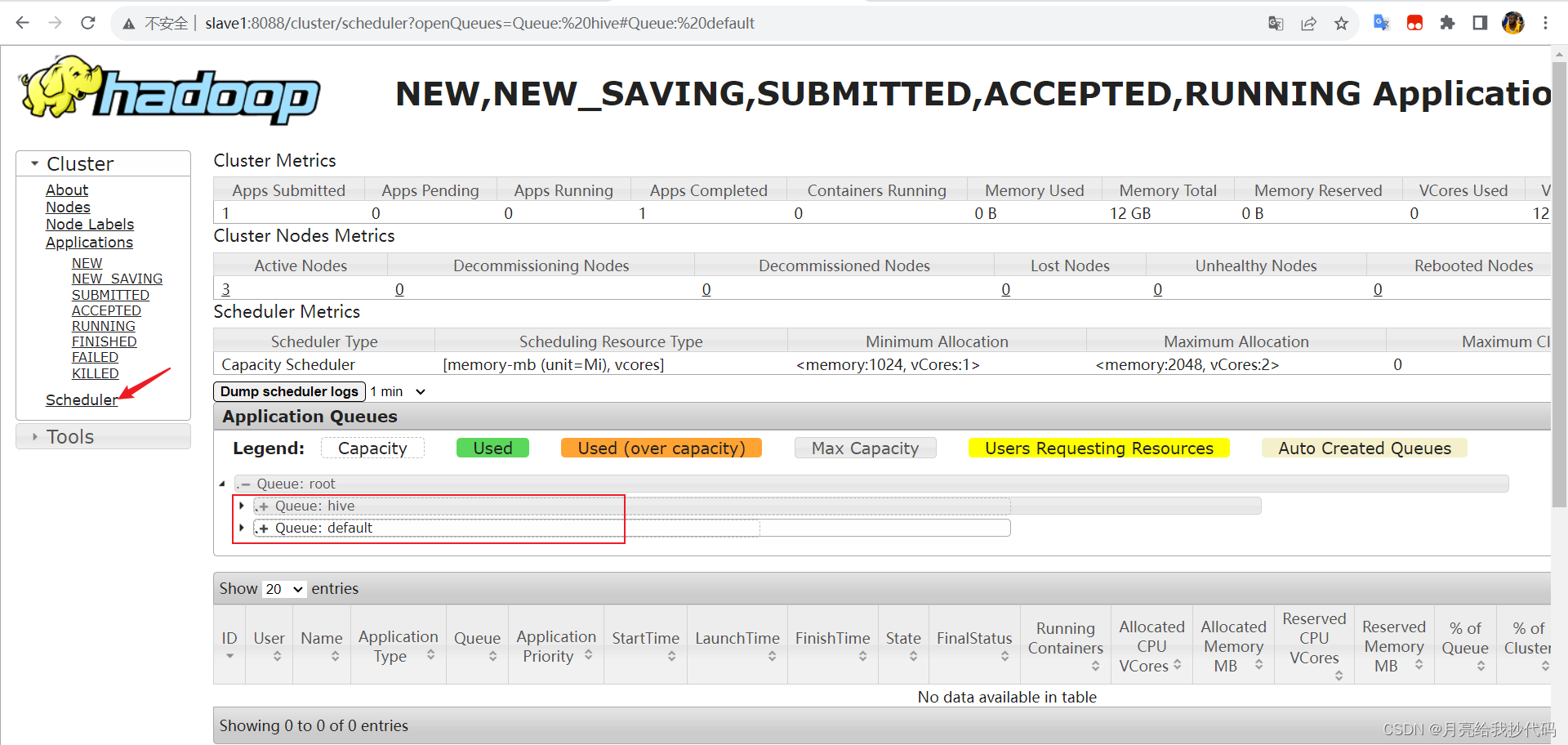
点开可以看到更为详细的配置信息: