部署本地大模型并构建对话网页需要分为以下几个步骤,以下是详细指南:
1. 选择大模型
推荐模型:
- 开源模型(适合本地部署):
- LLaMA(Meta,需申请权限) / Alpaca(斯坦福基于LLaMA微调)
- ChatGLM-6B(清华,支持中英双语,显存需求低)
- Falcon(阿联酋TII,商业友好许可)
- Vicuna(基于LLaMA的对话优化模型)
- 模型下载:
- Hugging Face Hub:https://huggingface.co/models
- 国内镜像(如阿里云、百度云等,加速下载)。
2. 部署大模型
环境准备:
- Python 3.8+:确保已安装。
- 安装依赖库:
pip install torch transformers huggingface-hub fastapi uvicorn python-dotenv
示例代码(以ChatGLM-6B为例):
# model_server.py
from transformers import AutoTokenizer, AutoModel
from fastapi import FastAPI, Request
from fastapi.middleware.cors import CORSMiddleware
import uvicornapp = FastAPI()# 允许跨域
app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_methods=["*"],allow_headers=["*"],
)# 加载模型
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda() # GPU运行
# model = model.float().cpu() # CPU运行(速度较慢)@app.post("/chat")
async def chat(request: Request):data = await request.json()prompt = data.get("prompt", "")response, _ = model.chat(tokenizer, prompt, history=[])return {"response": response}if __name__ == "__main__":uvicorn.run(app, host="0.0.0.0", port=8000)
运行模型服务:
python model_server.py
3. 构建网页界面
前端技术选型:
- 简单版:HTML + JavaScript + CSS
- 进阶版:Vue.js / React + Axios
示例代码(HTML/JS):
<!DOCTYPE html>
<html>
<head><title>AI Chat</title><style>.chat-box { width: 600px; margin: 20px auto; }#response { white-space: pre-wrap; }</style>
</head>
<body><div class="chat-box"><textarea id="input" rows="4" cols="50"></textarea><button onclick="sendRequest()">发送</button><div id="response"></div></div><script>async function sendRequest() {const input = document.getElementById("input").value;const responseDiv = document.getElementById("response");try {const res = await fetch("http://localhost:8000/chat", {method: "POST",headers: { "Content-Type": "application/json" },body: JSON.stringify({ prompt: input }),});const data = await res.json();responseDiv.innerHTML = data.response;} catch (error) {responseDiv.innerHTML = "请求失败:" + error.message;}}</script>
</body>
</html>
4. 连接模型与网页
-
启动模型后端:
python model_server.py -
打开网页:
- 直接双击HTML文件,或通过本地Web服务器(如VS Code Live Server)打开。
5. 部署优化
性能优化:
- 模型量化(减少显存占用):
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).quantize(8).cuda() # 8-bit量化 - 使用GPU:确保安装对应版本的CUDA和PyTorch。
- 异步处理:使用FastAPI的异步接口提升并发能力。
功能增强:
- 对话历史:在后端保存用户对话历史。
- 流式输出:通过WebSocket实现逐字输出效果。
- 前端美化:引入Bootstrap或Element UI优化界面。
6. 高级部署(可选)
-
使用LangChain:
from langchain.llms import HuggingFacePipeline from langchain.chains import ConversationChainllm = HuggingFacePipeline.from_model_id(model_id="THUDM/chatglm-6b",task="text-generation",device=0 # GPU设备号 ) chain = ConversationChain(llm=llm) -
Docker容器化:
FROM python:3.8-slim COPY . /app WORKDIR /app RUN pip install torch transformers fastapi uvicorn CMD ["uvicorn", "model_server:app", "--host", "0.0.0.0", "--port", "8000"]
注意事项
- 硬件要求:
- ChatGLM-6B:至少需13GB显存(FP16)或8GB显存(INT8量化)。
- CPU模式需要32GB+内存,且推理速度较慢。
- 模型下载:
- 首次运行会自动下载模型。
- 国内用户可使用镜像站或手动下载后指定本地路径:
model = AutoModel.from_pretrained("./chatglm-6b")
- 安全与隐私:
- 本地部署时数据不会外传。
- 若公网开放,需添加身份验证(如API Key)。
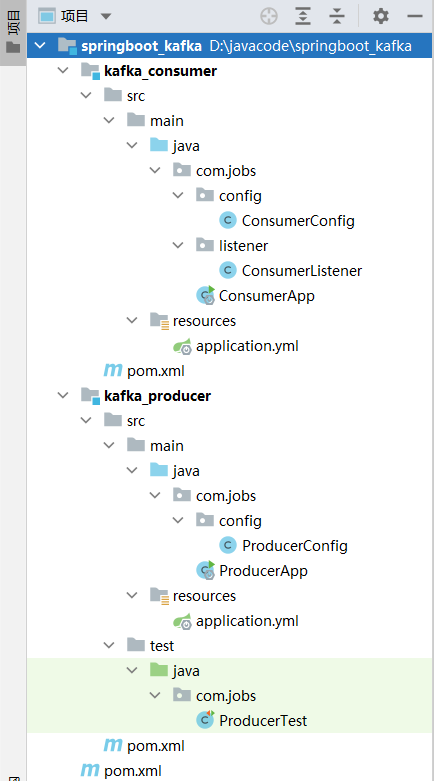
完整项目结构
├── model_server.py # 后端服务
├── static
│ └── index.html # 前端页面
├── requirements.txt # 依赖列表
└── .env # 环境变量(可选)
通过以上步骤,你可以在本地实现一个完整的大模型对话系统!

![[2025.1.28 MySQL学习] 锁](https://img2024.cnblogs.com/blog/3574171/202501/3574171-20250128150927207-52284983.png)