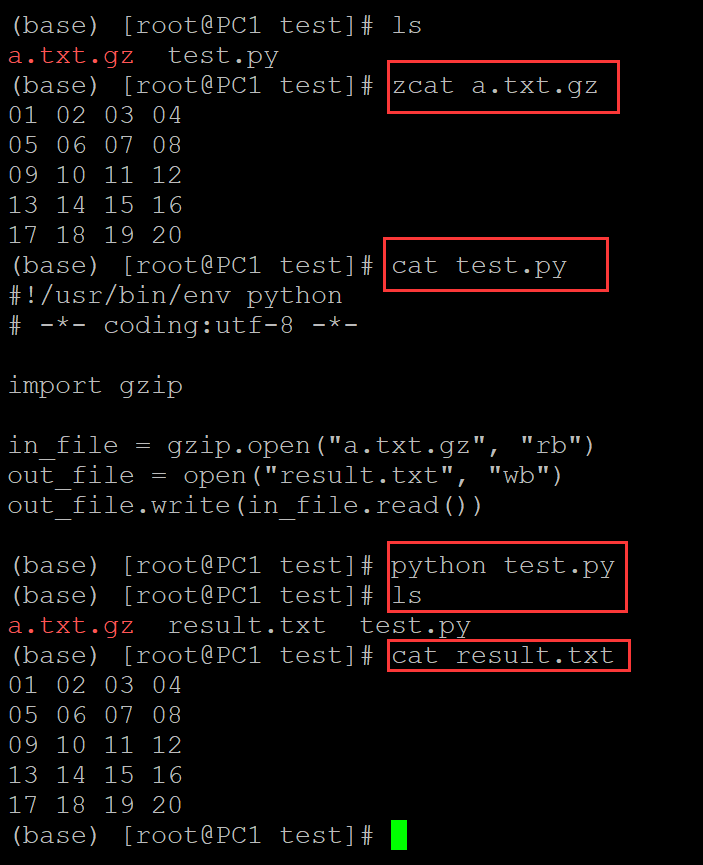
mysql day04课堂笔记
1、索引
1.1、什么是索引?
索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。
一张表的一个字段可以添加一个索引,当然,多个字段联合起来也可以添加索引。
索引相当于一本书的目录,是为了缩小扫描范围而存在的一种机制
对于一本字典来说,查找某个汉字有两种方式:
第一种方式:一页一页挨着找,直到找到为止,这种查找方式数据全字典扫描。
效率比较低
第二种方式:先通过目录(索引)去定位一个大概的位置,然后直接定位到这个
位置,做局域性扫描,缩小扫描范围,快速地查找,这种查找方式属于通过索引检索,
效率较高
t_user
id(idIndex) name(nameIndex) email(emailname) address(addressIndex)
______________________________________________________________________
1 zhangsan
2 lisi
3 wangwu
4 zhaoliu
select * from t_user where name='jack';
以上的这条SQL语句回去name字段上扫描,为什么?
因为查询条件是:name=‘jack’
如果name字段上没有添加索引(目录) ,或者说没有给name字段创建索引
msyql会进行全扫描,会将name字段上的每一个值都对比一遍,效率比较低
mysql在查询方面主要就是两种方式
第一种方式:全表扫描
第二种方式:根据索引检索
注意:在实际中,汉语字典前面的目录是排序的,按照a b c d……排序
为什们排序,因为只有排序了才会有区间查找这一说(缩小扫描范围,
其实就是只扫某一个区间)
在mysql数据库中索引也是需要排序的,并且这个索引的排序和TreeSet
数据结构相同,TreeSet(TreeMap) 底层是一个自平衡的二叉树!在mysql
当中索引是一个B-Tree数据结构
遵循左小右大原则存放,采用中序遍历方式遍历数据。
1.2、索引的实现原理?
假设有一张表t_user
id(pk) name 每一行记录在硬盘上的物理存储编号
————————————————————————————————————————————————————————————
100 zhansan 0x111
120 lisi 0x345
99 wangwu 0x239
101 zhaoliu 0x389
提醒一:在任何数据结构中主键会自动添加索引对象,id字段上自动有
索引,因为id是pk,另外在mysql当中,一个字段上如果有unique约束的话
也会自动创建索引对象
提醒二:在任何数据库中,任何一张表的任何一条记录在硬盘存储上都有
一个硬盘上的物理存储编号。
提醒三:在mysql当中,索引是一个单独的对象,不同的索引存储引擎以不同的方式
存在,在MyISAM存储引擎中,索引存储在一个.myi文件中,在InnoBD存储引擎中
索引存储在一个逻辑名为tablespace的当中,在MEMORY存储引擎当中索引被存储
在内存当中,不管索引存储在哪里,索引在mysql中都是一棵树的形式存在(自平衡二叉树
B_Tree)
1.3、主键上,以及unique字段上都会自动添加索引的!!!
什么条件下,我们会考虑给字段添加索引?
条件一:数据量庞大(到底多少数据量才算庞大,这个要测试,因为每个硬件环境不同)
条件二:该字段经常出现在where的后面,以条件的形式存在,也就是说这个字段总是被
扫描
条件三:该字段很少的DML(insert delete update)操作,(因为DML之后,索引需要重新排序)
建议不要随意添加索引,因为索引也是需要维护的,太多的话反而会降低系统的性能
建议通过主键查询,建议通过unique约束的字段进行查询,效率是比较高的。
1.4、索引怎么创建?怎么删除?语法是什么?
创建索引:
create index emp_name_index on emp(ename);
给emp表的enamel字段添加索引,起别名:emp_ename_index
删除索引:
drop index emp_ename_index on emp;
1.5、在msyql中,怎么查看一个sql语句是否使用了索引进行检索?
mysql>
explain select * from emp where ename ='KING';
----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
扫描14条记录,说明没有使用索引。type=ALL
mysql>
create index emp_ename_index on emp(ename);
+----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-------------+
| 1 | SIMPLE | emp | ref | emp_ename_index | emp_ename_index | 33 | const | 1 | Using where |
+----+-------------+-------+------+-----------------+-----------------+---------+-------+----
1.6、索引有失效的时候,什么时候索引失效?
select * from emp where ename like '%T';
ename 上即使添加了索引,也不会走索引,为什么?
原因是因为模糊匹配当中以‘%’开头了
尽量避免模糊查询的时候以'%'开始
这是一种优化的手段/策略。
mysql>
explain select * from where ename like '%T';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+----
失效的第二种情况:
使用or的时候会失效,如果使用or那么要求or量表的条件字段都要有
索引,才会走索引,如果其中一边有一个字段没有索引,那么另一个字段
上的索引也会失效,所以这是为什么不建议使用or的原因
explain select * from emp where ename ='king' or job ='manager';
+----+-------------+-------+------+-----------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | emp_ename_index | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+-----------------+------+---------+------+------+-------------+
失效的第三种情况:
使用复合索引的时候,没有使用左侧的列查找,索引失效
什么是复合索引?
两个字段,或者更多字段联合起来添加一个索引,叫做复合索引。
create index emp_job_sal_index on emp(job,sal);select * from emp where job='manager';
select * from emp where sal=800;
---+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-------------------+-------------------+---------+-------+------+-------------+
| 1 | SIMPLE | emp | ref | emp_job_sal_index | emp_job_sal_index | 30 | const | 3 | Using where |
+----+-------------+-------+------+-------------------+-------------------+---------+-------+------+-------------+
失效的第四种情况
在where中索引列参加了运算,索引失效
msyql>
create index emp_sal_index on emp(sal);explain select * from emp sal+1=800;
失效的第五种情况:
在where中索引列中使用了函数
explain select * from emp where upper(ename)='SMITH';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
失效的第六种………
失效的第七种……
1.7、索引是各种数据库进行优化的重要手段.优化的时候先考虑的因素是索引
索引在数据库分了很多类?
单一索引:一个字段添加索引
复合索引:两个字段或者多个字段上添加索引。
主键索引:主键上添加索引
唯一性索引:具有unique约束的字段上添加索引。
……
注意唯一性比较弱的字段上添加索引用处不大。
2.视图(view)
2.1、什么是视图?
view:站在不同的角度看待同一份数据。
2.2、怎么创建视图对象? 怎么删除视图对象?
表复制:
mysql>
create table dept2 as select * from dept;
dept2表中的数据:
mysql>
select * from dept2;
创建视图对象:
create view dept2_view as select * from dept2;
删除视图对象:
drop view dept2_view ;
注意:只有DQL 语句才能以view的形式创建
create view view_name as 这里必须是SQL语句;
2.3、视图的作用?
我们可以面向视图对象进行删除增删改查,对视图对象的增删改查,
会导致原表被操作!(视图的特点:通过视图的操作,会影响到原表的数据。)
//面向视图查询
select * from dept2_view;
//面向视图插入
insert into dept2_view(deptno,dname,loc) values(60,'sales','beijing');
查询原表中的数据
mysql>
select * from dept2;
//面向视图删除
mysql>
delete from dept2_view;
//查询原表中的数据
mysql>
select * from dept2;
//创建视图对象
create viewemp_dept_view
as
selecte.ename,e.sal,d.dname
fromemp e
joindept d
one.deptno=d.deptno;
//查询视图对象
mysql>
select * from emp_dept_view;
//面向视图更新
update emp_dept_view set sal=1000 where dname='accounting';
//原表的数据被更新
mysql>
select * from emp;
2.4、视图对象在实际的开发中到底有什么用?
create viewemp_dept_view as select e.ename,e.sal,d.dname from emp e join dept d on e.deptno=d.deptno;
假设有条非常复杂的SQL语句,而这条语句需要在不同的位置上反复使用。
每一次使用这个sql语句的时候都需要重新编写,很长,很麻烦,怎么办呐?
可以吧这条非常复杂的SQL语句以视图对象的形式新建
在需要编写这条sQL语句的位置,直接使用视图对象,可以大大简化开发
并且利于后期的维护,因为修改的时候只需要修改一个位置就行,只需要
修改视图对象所映射的SQL语句
我们以后面向视图开发的时候,使用视图的时候可以像使用table一样
可以对视图进行增删改查等操作的时候,视图不是在内存当中,视图对象
也是存储在硬盘上的,不会消失。
再次提醒:
视图对应的语句只能是DQL语句。
但是视图对象创建完成之后,可以对视图进行增删改查等操作
小插曲:
增删改查,又叫做:CRUD
CRUD是在公司中程序员之间沟通的术语,一般很少说增删改查
3、DBA常用命令?
重点掌握:
数据的导入和导出(数据的备份)
其他命令了解即可
数据导出?
注意:在windows的dos窗口中:
mysqldump bjpowernode>F:\datagripprograms.sql -uroot -p123456
数据导出?
注意:需要先登录到mysql数据库的服务器上。
然后创建数据库:create database bjpowernode;
使用数据库:use bjpowernode
然后初始化数据库:source F:\datagripgrograms.sql
4、数据库设计三范式?
4.1、什么是数据库设计范式?
数据库表的设计依据。教你怎么进行数据库表的设计
4.2、数据库设计范式共有?
3个。
第一范式:要求任何一张表必须有主键,每一个字段原子性不可再分
第二范式:建立在第一范式的基础之上,要求所有非主键字段完全依赖主键,
不产生部分依赖
第三范式:建立在第二范式的基础之上,要求所有非主键字段直接依赖主键,
不要产生传递依赖
面试常问的要熟记
4.3、第一范式最核心,最重要的范式,所有的表的设计都需要满足。
必须有主键,并且每一个主键都是原子性不可再分的
学生编号 学生姓名 联系方式
————————————————————————————
1001 张三 zs@gmail.com,1359999
1002 李四 ls@gmail.com,1368888
1003 王五 ww@163.net,13488888
以上是学生表,满足第一范式吗?
不满足,第一:没有主键,第二:联系方式可以分为邮箱地址和电话
学生编号(pk) 学生姓名 邮箱地址 联系电话
————————————————————————————————————————————————
1001 张三 zs@gmail.com 1359999
1002 李四 ls@gmail.com 1368888
1003 王五 ww@gmail.com 1348888
4.4、第二范式:建立在第一范式的基础之上。要求所有的非主键字段必须完全依赖主键,不要产生部分依赖
学生编号 学生姓名 教师编号 教师姓名
————————————————————————————————————————————
1001 张三 001 王老师
1002 李四 002 赵老师
1003 王五 001 王老师
1001 张三 002 赵老师
这张表描述了学生和老师的关系:(一个学生可能有多个老师,一个老师有多个学生)
这是非常典型的:多对多关系!
分析以上的表是否满足第一范式?
不满足第一范式。
怎么满足第一范式呢?修改
学生编号+教师编号(pk) 学生姓名 教师编号
————————————————————————————————————————————
1001 001 张三 王老师
1002 002 李四 赵老师
1003 001 王五 王老师
1001 001 张三 赵老师
学生编号 教师编号,两个字段联合做主键,复合主键(pk:学生编号+教师编号)
经过修改之后,以上的表满足第一范式,但是满足第二范式吗 ?
不满足,“张三” 依赖1001 “王老师”依赖001 显然产生了部分依赖
产生部分依赖有什么缺点?
数据冗余了,空间浪费了,‘张三’重复了,‘王老师’重复了
为了让以上的表满足第二范式,你需要这样设计:
使用三张表来表示多对多的关系!!!
学生表
学生编号(pk) 学生名字
——————————————————————————
1001 张三
1002 李四
1003 王五
教师表
教师编号(pk) 教师姓名
——————————————————————————————————
001 王老师
002 赵老师
学生教师关系表
id(pk) 学生编号(fk) 教师编号(fk)
——————————————————————————————————————————————————————
1 1001 001
2 1002 002
3 1003 001
4 1001 002
背口诀:
多对多怎么设计?
多对多,三张表,关系表两个外键!!!!
4.5、第三范式:第三范式建立在第二范式的基础之上,要求所有非主键字典必须直接依赖主键,不要产生传递依赖
学生编号(pk) 学生姓名 学生编号 班级名称
——————————————————————————————————————————————————
1001 张三 01 一年一班
1002 李四 02 一年二班
1003 王五 03 一年三班
1004 赵六 03 一年三班
以上表的设计是描述:班级和学生的关系,显然是一对多的关系!
一个教师中有多个学生。
以上设计是否满足第一范式?
满足第一范式,有主键
分析以上表是否满足第二范式?
满足第二范式,因为主键不是符合主键,没有产生部分依赖,主键是单一主键
分析以上表是否满足第三反水?
第三范式要求;不产生传递依赖
一年一班依赖01 ,01依赖1001 ,产生了传递依赖
不符合第三范式的要求,产生了数据的冗余
那么怎么设计一对多呢?
班级表:一
编辑编号(pk) 班级名称
——————————————————————————
01 一年一班
02 一年二班
03 一年三班
学生表:多
学生编号(pk) 学生姓名 班级编号(fk)
——————————————————————————————————————————————
1001 张三 01
1002 李四 02
1003 王五 03
1004 赵六 03
背口诀:
一对多,两张表,多的表加外键!!!
4.6、总结表的设计?
一对多:一对多,两张表,多的表加外键!!!
多对多:多对多,三张表,关系表加外键!!!
一对一:
一对一放到一张表中不就行了吗?为啥还要拆分表?
在实际的开发中,可能存在一张表字段太多,太庞大
这个时候需要拆分表
没有拆分表之前:一张表
t_user
id login_name login_pwd real_name email address....
________________________________________________________________________
1 zhangsan 123 张三 zs@123.com
2 lisi 123 李四 ls@123.com
.....
这种庞大的表建议拆分为两张:
t_login登陆信息表
id login_name login_pwd
_____________________________________
1 zhangsan 123
2 lisi 123
t_user用户详细表
real_name email address.....
_____________________________________
张三 zs@123.com
李四 ls@123.com
口诀:一对一,外键唯一!!!!!
![[ArkUI] 记录一次 ArkUI 学习心得 (1) -- 基础概念](https://img2024.cnblogs.com/blog/3597783/202502/3597783-20250203092447400-1363936170.png)