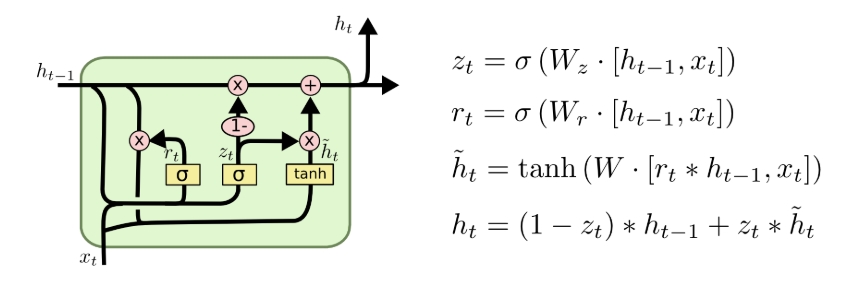
三个网络的架构图:
RNN:

LSTM:
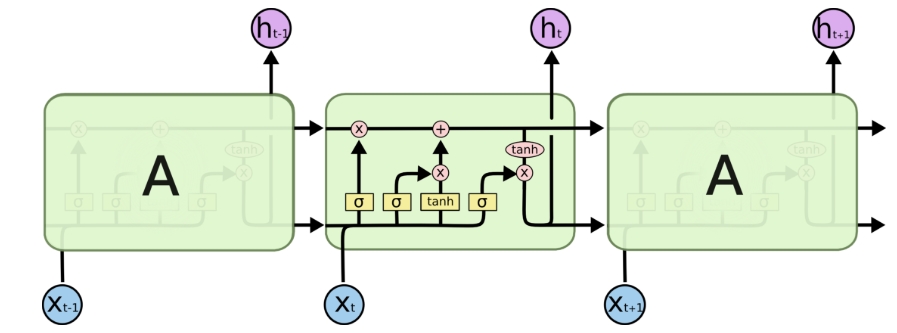
GRU:
特性对比列表:
|
特性
|
RNN
|
LSTM
|
GRU
|
|---|---|---|---|
|
门控数量
|
无
|
3门(输入/遗忘/输出)
|
2门(更新/重置)
|
|
记忆机制
|
仅隐藏状态ht
|
显式状态Ct + 隐藏状态ht |
隐式记忆(通过门控更新状态) |
|
核心操作 |
直接状态传递 |
门控细胞状态更新 |
门控候选状态混合 |
|
计算复杂度 |
O(d2)(1组权重) |
O(4d2)(4 组权重) |
O(3d2)(3 组权重) |
|
长期依赖学习 |
差(<10步) |
优秀(>1000步) |
良好(~100步) |
|
梯度消失问题 |
严重 |
显著缓解 |
较好缓解 |
|
参数数量 |
最少 |
最多(3倍于RNN) |
中等(2倍于RNN) |
|
训练速度 |
最快 |
最慢 |
较快 |
|
过拟合风险 |
高 |
中等 |
低 |
|
典型应用场景 |
简单序列分类 |
机器翻译/语音识别 |
文本生成/时间序列预测 |
下面是两个例子:
一:LSTM识别数字:
import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms,datasetsdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transforms.ToTensor()) train_loader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True)class RNN(nn.Module):def __init__(self, input_size, hidden_size, num_layers, num_classes):super(RNN, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, num_classes)def forward(self, x):h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)out, _ = self.lstm(x, (h0, c0)) out = self.fc(out[:, -1, :])return outsequence_length = 28 input_size = 28 hidden_size = 128 num_layers = 2 num_classes = 10model =RNN( input_size, hidden_size, num_layers, num_classes).to(device) model.train()optimizer = optim.Adam(model.parameters(), lr=0.01) criterion = nn.CrossEntropyLoss()num_epochs = 10 for epoch in range(num_epochs):running_loss = 0.0correct = 0total = 0for images, labels in train_loader:B,_,_,_= images.shape images = images.reshape(B,sequence_length,input_size)images = images.to(device)labels = labels.to(device)output = model(images)loss = criterion(output, labels)optimizer.zero_grad()loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(output.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}, Accuracy: {(100 * correct / total):.2f}%")
二:GRU数据拟合:
import torch import torch.nn as nn import matplotlib.pyplot as pltclass RNN(nn.Module):def __init__(self):super().__init__()# self.rnn=nn.RNN(input_size=1,hidden_size=128,num_layers=1,batch_first=True)# self.rnn=nn.LSTM(input_size=1,hidden_size=128,num_layers=1,batch_first=True)self.rnn=nn.GRU(input_size=1,hidden_size=128,num_layers=1,batch_first=True)self.linear=nn.Linear(128,1)def forward(self,x):output,_=self.rnn(x)x=self.linear(output)return xif __name__ == '__main__':x = torch.linspace(-300,300,1000)*0.01 y = torch.sin(x*3.0) + torch.linspace(-300,300,1000)*0.01plt.plot(x, y,'r') x = x.unsqueeze(1).cuda()y = y.unsqueeze(1).cuda()model=RNN().cuda()optimizer=torch.optim.Adam(model.parameters(),lr=5e-4)criterion = nn.MSELoss().cuda()for epoch in range(5000):preds=model(x)loss=criterion(preds,y)optimizer.zero_grad()loss.backward()optimizer.step()print('loss',epoch, loss.item())x = torch.linspace(-300,310,1000)*0.01x = x.unsqueeze(1).cuda()pred = model(x)plt.plot(x.cpu().detach().numpy(), pred.cpu().detach().numpy(),'b')plt.show()
参考:Understanding LSTM Networks -- colah's blog






![[ArkUI] 记录一次 ArkUI 学习心得 (1) -- 基础概念](https://img2024.cnblogs.com/blog/3597783/202502/3597783-20250203092447400-1363936170.png)