前言常用字符集utf8utf8mb4排序规则(Collation)utf8mb4_general_ciutf8mb4_unicode_ciutf8mb4_0900_ai_ci总结对比使用建议示例前言
在使用MySQL创建数据库时候免不了选择字符集和排序规则,不同的字符集对应不同的排序规则,不同的排序规则的性能和效果是不一样的。一般我们经常使用到的字符集是utf8mb4,使用到的排序规则是utf8mb4_general_ci、utf8mb4_unicode_ci、utf8mb4_0900_ai_ci三种。那么今天就来详细介绍下这几种字符集和排序规则,方便大家今后选用。
常用字符集
utf8 和 utf8mb4是我们常用的字符集。
utf8
定义:MySQL中的utf8字符集实际上是指utf8mb3,即每个字符最多使用3个字节进行编码。
支持字符范围:支持大部分Unicode字符,但不包括某些需要4个字节表示的字符(如部分表情符号、一些罕用汉字等)。
适用场景:适合不需要完整Unicode支持的场景,占用空间较小。
utf8mb4
定义:真正的UTF-8实现,每个字符最多使用4个字节进行编码。
支持字符范围:完全支持所有Unicode字符,包括表情符号和罕用汉字。
适用场景:适合需要处理全球语言和特殊字符的场景,虽然占用更多存储空间,但确保了数据完整性。
排序规则
不同的字符集对应不同的排序规则,一般我们字符集选择utf8mb4便于保存表情等特殊字符,那么我们的排序规则则主要介绍utf8mb4_general_ci、utf8mb4_unicode_ci、utf8mb4_0900_ai_ci。其中_ai表示“accent insensitive”,不区分重音。_ci表示“case insensitive”,不区分大小写。
utf8mb4_general_ci
定义:通用的不区分大小写的排序规则。
特点:
比较快,因为它的比较规则较为简单。
不完全符合Unicode标准,在某些情况下可能不够准确。
适用场景:适合对性能要求较高且对排序准确性要求不高的场景。
utf8mb4_unicode_ci
定义:基于Unicode标准的不区分大小写的排序规则。
特点:
更加准确,遵循Unicode标准。
性能稍差于_general_ci,但在大多数情况下可以接受。
适用场景:适合对排序准确性有较高要求的场景。
utf8mb4_0900_ai_ci
定义:MySQL 8.0引入的新排序规则,基于Unicode 9.0标准,不区分大小写和重音。
特点:
支持更多的语言和字符特性。
提供更准确的比较和排序结果。
性能优化较好,提供更好的国际化支持,适合现代应用。
适用场景:适合需要处理多语言文本和特殊字符的现代应用。
总结对比
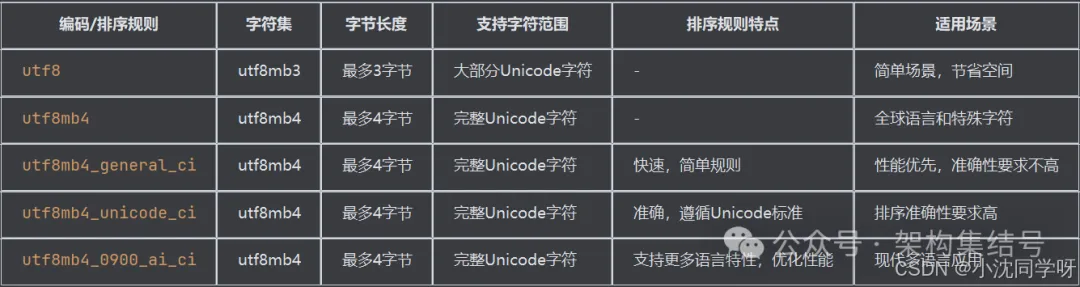
通过选择合适的字符集和排序规则,可以在性能和功能之间找到最佳平衡,确保MySQL数据库在处理多语言和特殊字符时的正确性和高效性。
使用建议
如果需要支持表情符号或其他4字节字符:使用utf8mb4。
如果对性能要求较高且不需要严格的Unicode排序:选择utf8mb4_general_ci。
如果需要严格的Unicode排序和更好的国际化支持:选择utf8mb4_unicode_ci。
如果需要最新的Unicode标准和不区分重音的支持:选择utf8mb4_0900_ai_ci。
示例
创建数据库时设置字符集和排序规则
CREATE DATABASE mydb
CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
创建表时设置字符集和排序规则
CREATE TABLE mytable (
id INT PRIMARY KEY,
name VARCHAR(255)
) ENGINE=InnoDB
DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_unicode_ci;
修改现有表的字符集和排序规则
ALTER TABLE mytable
CONVERT TO CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
原创 senfel 架构集结号